

Меня зовут Александр Свинин, я уже более 10 лет занимаюсь построением CMDB в проектах внедрения продукта Naumen Service Desk. В статье делюсь опытом: откуда взять данные об объектах
1 Что такое и зачем нужна CMDB
2
С чего начать сбор данных
3
Как получить данные
4
Как провести нормализацию данных
5
Как провести дедупликацию данных
6
Как провести агрегацию данных
7
Как отладить процесс сбора данных
Что такое и зачем нужна CMDB
К учету компонентов
CMDB — это база данных управления конфигурациями, которая включает в себя все элементы
Также в управлении ИТ существует понятие «актив». Актив — это любой элемент, который имеет ценность для организации и подлежит управлению на протяжении жизненного цикла, от закупки до списания. Сюда относятся материальные устройства, ПО, лицензии, здания и даже персонал.
Как правило, понятием «актив» оперирует бухгалтерия, а термин «КЕ» используют
Выделим возможности, которые дает CMDB.
Понимать состояние оборудования и его износ. В системе автоматизации можно отобразить характеристики оборудования, срок эксплуатации, дату закупки, информацию о поломках, обслуживании и ремонте. Например, сервер закуплен 10 лет назад и выходит из строя каждые 2 недели.
Планировать закупки и списания оборудования. На основе характеристик устройств, данных о связанных событиях, инцидентах и ремонтах можно сделать вывод, когда менять оборудование, в т.ч. обосновать бюджет на закупку. Например, при заведении пользовательских устройств в CMDB будет видно, что часть сотрудников работает на компьютерах устаревших моделей, и нужна модернизация.
Проводить инвентаризацию. База данных по учету
Описать инфраструктуру комплексно. CMDB позволяет получить полное представление об инфраструктуре, сформировать
Управлять стандартизацией поставщиков. База уже содержит информацию о вендорах оборудования и другие необходимые сведения. Сопоставив и проанализировав данные, получится планировать дальнейшее развитие инфраструктуры. Так, аналитика позволит сделать вывод о надежности устройств, запланировать замену и оценить потребность обучения специалистов, которые будут обслуживать технику.
Предоставлять доступ к данным для специалистов. Например, в виртуальной инфраструктуре возник инцидент информационной безопасности. В базе данных КЕ инженер находит информацию о том, кто является владельцем виртуальной машины, на которой произошел сбой, для каких целей она заказана. Это сэкономит специалисту время при расследовании аварии.
Для построения CMDB нужно собрать начальные данные об объектах инфраструктуры. Несмотря на возможные финансовые и временные затраты, выгоды перевешивают.
С чего начать сбор данных
Обычно объектов в ИТ-инфраструктуре много, а ресурсы ограничены, поэтому не всегда получается сразу охватить все. Необходимо данные условно «разрезать» на части и наполнять базу постепенно. Как это сделать:
1. Определить приоритеты — информация о какой части инфраструктуры нужна в первую очередь, и начать формировать CMDB именно с нее.
Одним организациям важнее навести порядок в данных об автоматизированных рабочих местах и оргтехнике. Допустим, на оплату подрядчикам, которые обслуживают принтеры, каждый месяц уходят большие суммы. CMDB поможет оценить состояние устройств и продумать варианты оптимизации затрат.
Другие компании начинают учет с инфраструктурного оборудования: серверов, сетевых устройств. Например, для развития бизнеса требуется закупка дополнительных серверов, а CMDB поможет оценить, насколько эффективно распределяются имеющиеся мощности.
Еще вариант — начать с нематериальных активов: БД, информационных ресурсов, ПО. Например, организация закупает дорогостоящие лицензии, которыми надо управлять и распределять таким образом, чтобы не возникали простои.
2. Определить стейкхолдеров, которые помогут в сборе данных и формулировании требований.
Как правило,
Как получить данные
Обычно в организации уже ведется базовый учет инфраструктуры. Рассмотрим, какие источники подойдут и данные какого качества от них можно ожидать.
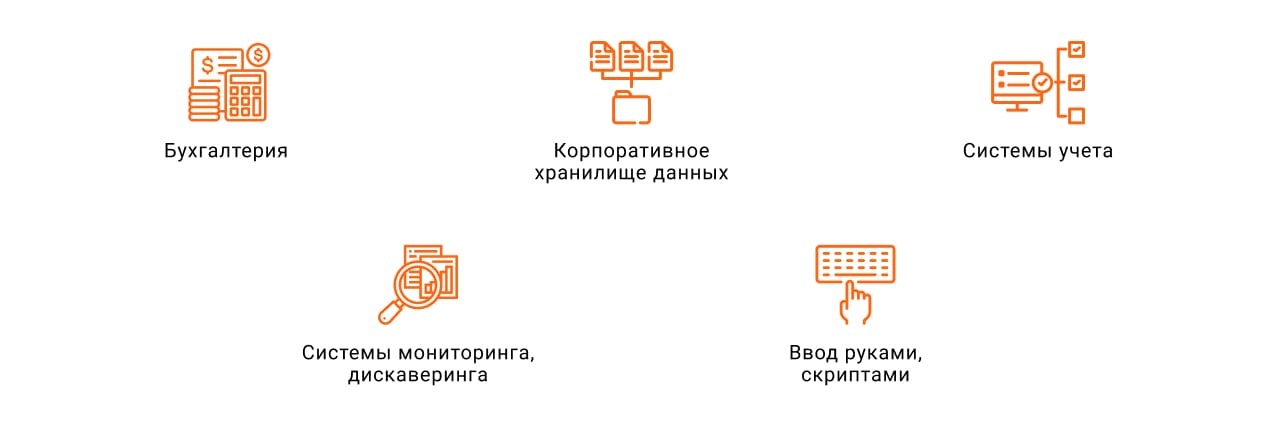
Типовые источники данных для CMDB
Бухгалтерский учет. Может использоваться как единственный или дополнительный источник. В бухгалтерском списке наименований активов содержится информация о стоимости, сроке эксплуатации и материально ответственных лицах. Но здесь не учитываются атрибуты, которые важны для ИТ, например, серийные номера и местоположение.
Корпоративные хранилища данных (КХД). В КХД на бухгалтерские данные накладывается дополнительный слой информации — серийные номера, местоположение, ответственные лица, договора поставки.
Системы учета ИТ-служб. Зачастую
Системы мониторинга и дискаверинга. Считается, чтобы построить хорошую CMDB, они обязательно нужны. Многое зависит от того, насколько полную информацию об инфраструктуре предоставляют инструменты.
Так, системы мониторинга обычно отслеживают метрики оборудования по своим настройкам, но не собирают характеристики, которые нужны в CMDB. Информация будет достоверной, и в некоторых случаях достаточной. Например, если компания использует только
Дискаверинг сканирует сеть, а если находит новое устройство — опрашивает его определенным протоколам. Например, с помощью
Нюанс: сканирование большой сети может занимать месяц и больше. Системы защиты могут обнаружить, что в инфраструктуре отправляется много запросов, и заблокировать активности. Чтобы этого избежать, процедура сканирования должна быть согласована со службами ИБ: по каким протоколам система дискаверинга проводит опрос, какие участки корпоративной сети можно сканировать.
Скрипты. Специально написанные скрипты позволят автоматически собирать информацию о серверах и рабочих станциях и далее передавать в систему.
Ручной ввод. Процесс затратен по времени, и данные, собранные в начале, могут устареть. При ручном вводе возникают опечатки и ошибки, поэтому его стоит применять, если других источников данных нет или информация из них непригодна.
Как показывает проектная практика Naumen, лучше использовать несколько источников. В системах данные могут отображаться
Как провести нормализацию данных
Нормализация — это процесс приведения данных к единому стандарту в соответствии с определенными правилами. Унификация требуется даже в том случае, если всего один источник.
Наименования вендоров. Бывает, что наименование одного производителя пишется
Названия ПО. Данные о ПО могут отображаться в сокращенном виде или полностью, латиницей или кириллицей, с указанием версии или без. Это требует стандартизации.
Названия моделей. Бывает, что на технике написано одно наименование модели, а когда ее опрашивает дискаверинг или мониторинг, модель передается другая. Чтобы избежать путаницы, рекомендуется аналогично ввести правила для стандартизации.
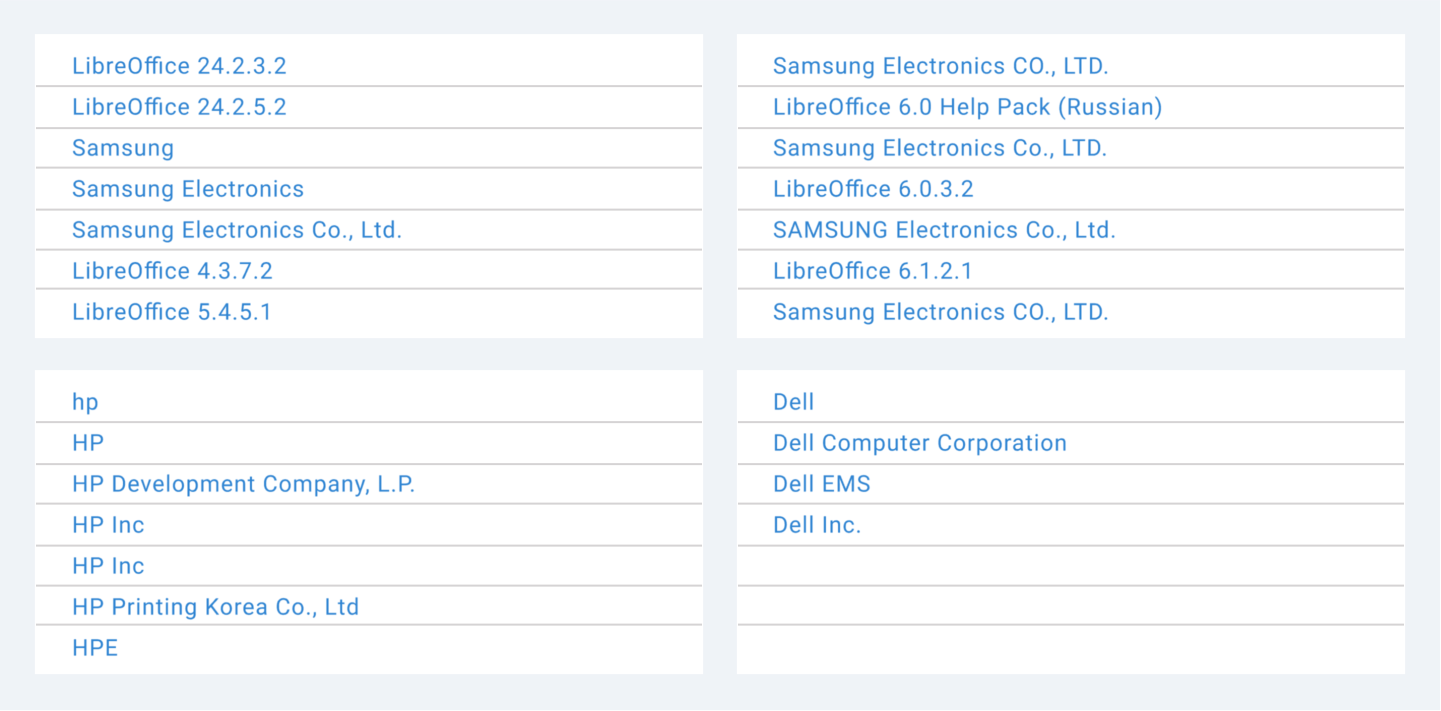
Ненормализованные данные: как собираются названия различных вендоров в системах учета и характеристиках самого оборудования
Классификация. При дискаверинге сложной техники не всегда удается правильно определить тип оборудования. Например, коммутатор хранилища при опросе, скорее всего, будет определен как «коммутатор» или «сетевое оборудование». Чтобы система автоматически выдавала более точную информацию, нужны правила классификации.
Единицы измерения. Даже однотипные устройства при опросе системой дискаверинга могут отдавать данные в единицах измерения разного порядка. Например, характеристики разных процессоров отображаться в герцах или мегагерцах. Емкость оперативной памяти — в байтах или мегабайтах. Характеристики нужно сконвертировать, чтобы в CMDB отображались в едином формате.
В результате организация получит стандартизированные данные, приведенные к общему виду.
Как провести дедупликацию данных
Дедупликация — это процесс поиска и «схлопывания» повторяющихся записей о КЕ в базе данных. Здесь нужно определить атрибуты, уникальные для КЕ, и обнаружить повторы. Обычно уникальные атрибуты устройств — это серийный номер, МAC-адрес и хостнейм.
Почему недостаточно одного из атрибутов? Например, уникальным идентификатором мог бы стать серийный номер. Однако нередки ситуации, когда определить его не получается: например, при дискаверинге оборудование «не отдает» данные о серийном номере.
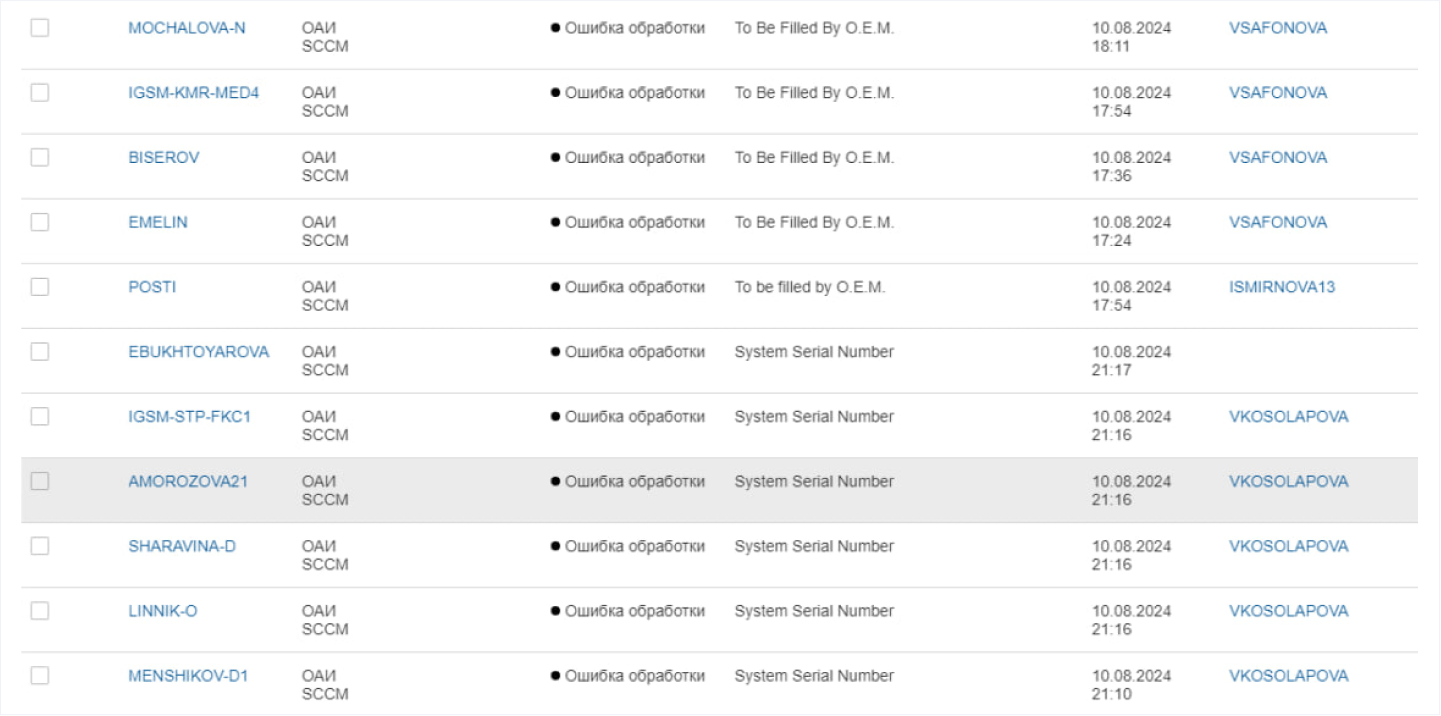
По результатам дискаверинга не всегда удается получить информацию о серийных номерах устройств
Поэтому при дедупликации лучше опираться не только на значение серийного номера, но и на
Сопоставление уникальных идентификаторов поможет эффективно сопоставлять данные из разных источников.
Как провести агрегацию данных
Агрегация — это процесс обобщения данных, которые поступают из разных источников, по одному и тому же компоненту инфраструктуры. Чтобы получить корректную информацию в CMDB, нужно определить вес данных — приоритет каждого источника.
Допустим, организация использует множество источников, в каждом из которых хранится информация об одном и том же устройстве. Если все источники равнозначные, то пересекающиеся данные будут постоянно меняться. Например, сначала будут отображаться данные из системы мониторинга, потом — из бухгалтерского учета, затем — из системы дискаверинга. Далее потребуется определить приоритеты для источников и списков атрибутов. Причем вес нужно выставлять только для тех атрибутов, которые повторяются в разных источниках.
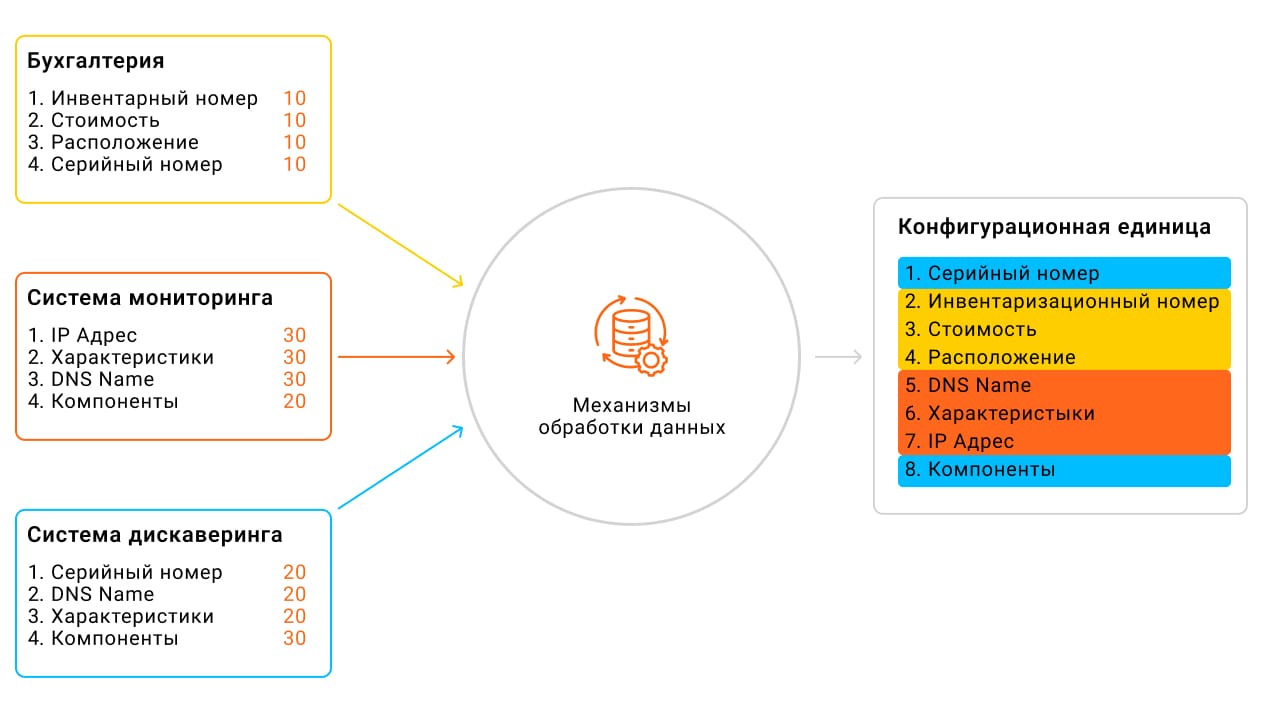
При агрегации разных источников и данных, которые поступают из них, дается разный приоритет, например, 10, 20 и 30
Допустим, данным из бухгалтерии можно доверять, но информация из других источников более полная. Значит, ставим бухгалтерии минимальный вес 10. Почти во всех случаях система мониторинга дает самые качественные данные: всем атрибутам ставим максимальный вес — 30, и только «компонентам» — 20. Данные по компонентам лучше собирает система дискаверинга, поэтому она и получит максимальный приоритет по этому атрибуту. В случае, если придут данные не из трех, а из двух источников, система будет использовать данные с более высоким весом. В результате набор данных о КЕ будет актуализирован.
Как отладить процесс сбора данных
При проверке загруженных данных в систему возможно, что они будут отображаться не так, как нужно. Инфраструктура каждой организации уникальна, и единого набора правил для нормализации, дедупликации и агрегации не существует. Для корректного результата понадобится тонкая настройка и несколько итераций.
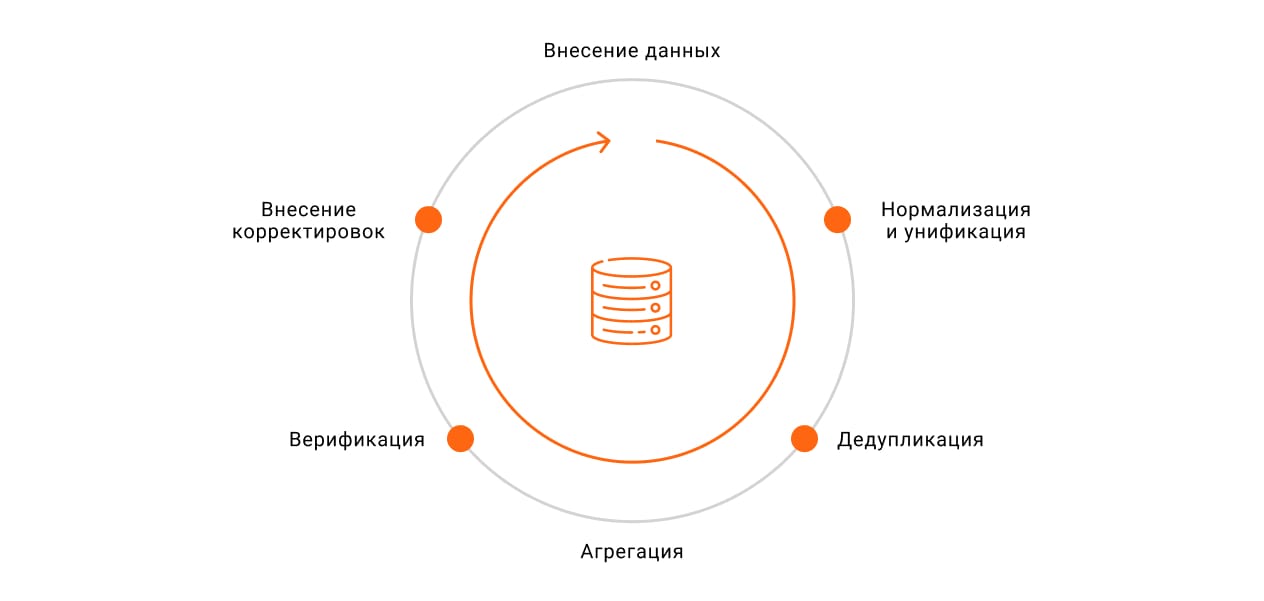
В среднем компания получает соответствующую потребностям CMDB после 5-6 итераций донастроек
Далее необходимо организовать процессы для поддержки CMDB в актуальном состоянии. Что потребуется:
- учитывать все элементы инфраструктуры с необходимой детализацией;
- связывать заявки в Service Desk с оборудованием;
- вносить в систему информацию о новых активах;
- управлять выбыванием оборудования.
О том, как настроить эти процессы, рассмотрим в следующей публикации.









