

В статье расскажем, как в решении зонтичного мониторинга Naumen BSM обрабатываются события, которые поступают из внешних систем. Разберем, как правила типизации и корреляции помогают определить, когда по событию нужно регистрировать инцидент, а когда нет.
Зачем нужны правила обработки событий в зонтичном мониторинге
В ИТ-инфраструктуре происходит огромное количество событий: аварии, предупреждения, сообщения о восстановлении. Все это фиксируют системы инфраструктурного (или корневого) мониторинга. Они же умеют передавать
При этом часть сообщений об авариях может оказаться ложной или избыточной. Например, на сервере произошел сбой в момент пиковой нагрузки, но работа быстро восстановилась без последствий для инфраструктуры. Однако система корневого мониторинга зафиксировала аварийное событие и отправила соответствующее уведомление ответственному администратору. Возможны ситуации, когда системы мониторинга отправляют оповещения об авариях, когда оборудование отключается для проведения плановой профилактики.
Чтобы понять, насколько критичны события, их нужно проанализировать. Для консолидации массивов данных мониторинга и последующего анализа применяются системы зонтичного мониторинга, например, Naumen BSM. Система способна автоматически обрабатывать метрики и события, делать выводы о состоянии здоровья
При анализе событий Naumen BSM использует специальные правила — типизации и корреляции. Правила типизации позволяют унифицировать разнородные данные из внешних источников — систем инфраструктурного мониторинга. А также понять, какое именно оборудование и услуга пострадали. Правила корреляции дают возможность автоматически определить, насколько критичен сбой и как быстро его нужно устранить. Еще правила позволяют избежать регистрации множества инцидентов по идентичным аварийным событиям.
Сценарии обработки событий гибко настраиваются в зависимости от специфики инфраструктуры, критичности услуг и других параметров. Рассмотрим, какие этапы автоматической обработки проходят события и как работают правила.
Унификация событий по правилам типизации
События, поступающие в Naumen BSM из внешних систем, обладают определенным набором параметров, например: время обнаружения, тип события, идентификатор, источник. Значения параметров обычно разноформатные и разнородные. Чтобы понять, как их интерпретировать, настраиваются правила типизации. Правила помогают определить, что значат «сырые» данные и соотнести их с тем представлением, которое заложено в системе зонтичного мониторинга. В результате определяются тип события и произошедшая ситуация.
Так, в системах инфраструктурного мониторинга событиям присваиваются десятки разных типов, например, «Info», «Error», «Warning». В Naumen BSM по умолчанию используются типы событий «Восстановление», «Информация», «Отклонение» и «Предупреждение». В правилах типизации указывается, какие значения, присвоенные событиям во внешних источниках, соответствуют типам событий в зонтичном мониторинге. Система автоматически находит правило типизации, которому соответствуют параметры поступившего события, и назначает нужный тип. Например, событиям с типом «Error» в системе зонтичного мониторинга может назначаться тип «Отклонение».
Аналогичным образом устанавливается ситуация. Система сравнивает значения, полученные из внешнего источника, со значениями, указанными в правиле, и заполняет атрибуты события. Например, при значении «Restore» для параметра «Описание» определяется ситуация «Восстановление работы сервера».
Правила типизации и корреляции при определении услуги и вида события
Не каждая авария в инфраструктуре требует незамедлительных действий
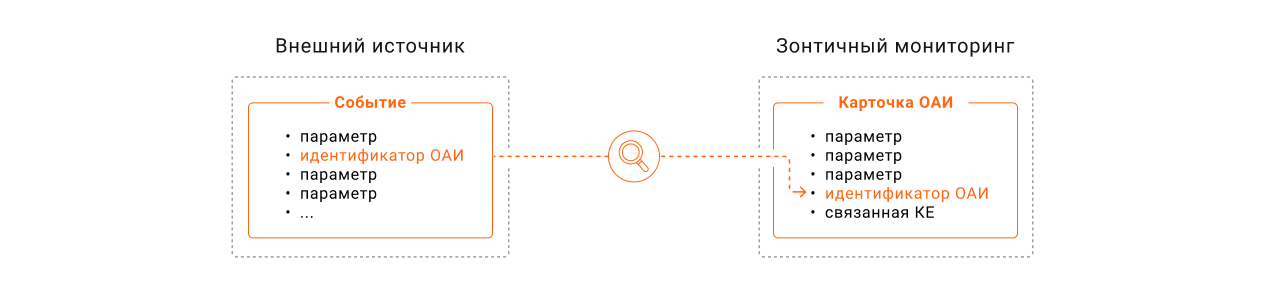
Принцип установления соответствия между объектом автоматической инвентаризации и конфигурационной единицей в базе данных
В терминах мониторинга все элементы инфраструктуры являются объектами автоматической инвентаризации (ОАИ). Каждому ОАИ присвоен свой номер — идентификатор. Правила типизации позволяют по идентификатору ОАИ установить соответствие физического устройства с конфигурационной единицей — виртуальным представлением этого элемента в системе автоматизации. В Naumen BSM отражено, какие услуги поддерживаются конкретными конфигурационными единицами. Это позволяет вычислить услугу, в предоставлении которой участвует устройство.
Далее с помощью правил корреляции система учитывает ситуацию, тип события, услугу и делает вывод, нужно ли создавать инцидент или нет. Например, если зафиксировано событие типа «Отклонение» по важной для организации услуге, система автоматически зарегистрирует инцидент. Для некритичных услуг можно настроить правило, по которому событие будет отражаться на статусе здоровья оборудования.
Также правила корреляции позволяют автоматически назначать сроки устранения инцидента, учитывая принятое в организации соглашение SLA.
Правила корреляции при поступлении однотипных событий
После регистрации инцидента в зонтичный мониторинг продолжат поступать события с пострадавшего устройства. Системы инфраструктурного мониторинга будут фиксировать аварийные события до тех пор, пока работоспособность оборудования не восстановится. Количество аварийных событий, отправленных в зонтичную систему, зависит от периодичности, с которой планировщики задач мониторинга забирают данные из внешних источников.
Допустим, планировщики загружают данные каждые 5 минут, а сбой будет устранен ориентировочно за час. Значит, только с одного ОАИ в зонтичный мониторинг поступит 12 аварийных событий, по каждому из которых по правилам корреляции должен быть зарегистрирован инцидент. А если авария на устройстве привела к отключению связанного оборудования, то количество аварийных событий и, соответственно, инцидентов кратно увеличивается. По факту дублирующие инциденты не нужны, ведь
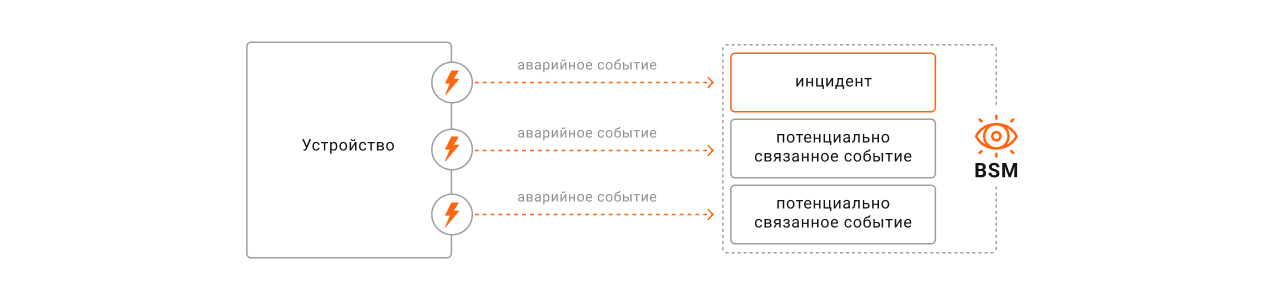
Специальные параметры в правиле корреляции позволяют избежать регистрации инцидентов по одинаковым событиям. Система зафиксирует инцидент по первому событию, а последующие идентичные запросы будет отмечать, как потенциально связанные с инцидентом. Параметры правила настраиваются: интервал может равняться и 15 минутам, и 3 часам, и суткам. Если по прошествии этого времени работоспособность устройств не восстановилась, система зарегистрирует новый инцидент по первому событию, которое поступит в указанный период времени, и «свяжет» с инцидентом более поздние. При закрытии инцидента в системе автоматически будут закрыты все связанные с ним события.
Как работают правила на практике
Рассмотрим на примере, что происходит в Naumen BSM при возникновении инцидента.
Допустим, на коммутаторе вышла из строя интегрированная плата управления. Коммутатор недоступен, и у сотрудников отключается локальная сеть и интернет. Недоступны и услуги, которые зависят от локальной сети. Из-за недоступности серверов отключились некоторые корпоративные приложения, перестали работать принтеры, камеры наблюдения, устройства
Далее с помощью преднастроенных правил типизации в зонтичной системе автоматически устанавливается тип событий, зафиксированных на коммутаторе («Отклонение»), и ситуация («Недоступность коммутатора»). По правилам типизации будут обработаны аварийные события и по другим устройствам.

При установлении типа события и ситуации система опирается на определяющие параметры, указанные в правилах типизации
Затем система по идентификатору ОАИ установит связь коммутатора с конфигурационной единицей, а также с услугой «Эксплуатация сети». Это критически важная услуга, поэтому регистрируется инцидент со сроком устранения 2 часа.
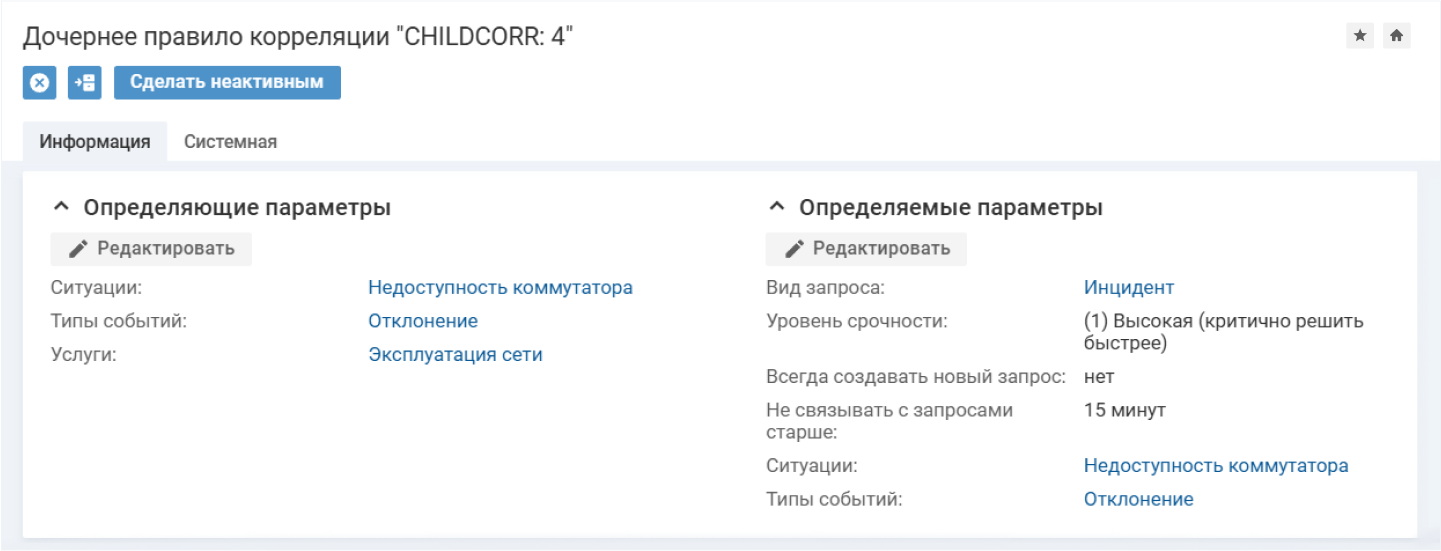
На основе определяющих параметров, указанных в правиле, по событию автоматически регистрируется инцидент с высоким уровнем срочности
Данные из инфраструктуры поступают в зонтичный мониторинг каждые 5 минут. Таким образом, за 15 минут только по сломанному коммутатору фиксируется 3 однотипных события, которые могли бы стать основанием для регистрации инцидента. В правилах корреляции установлено, что инцидент создается по первому событию, а однотипные события, поступившие в систему в течение дальнейших 15 минут, отмечаются как потенциально связанные. Так, за 15 минут в систему поступит 3 аварийных события с устройства и будет создан 1 инцидент.
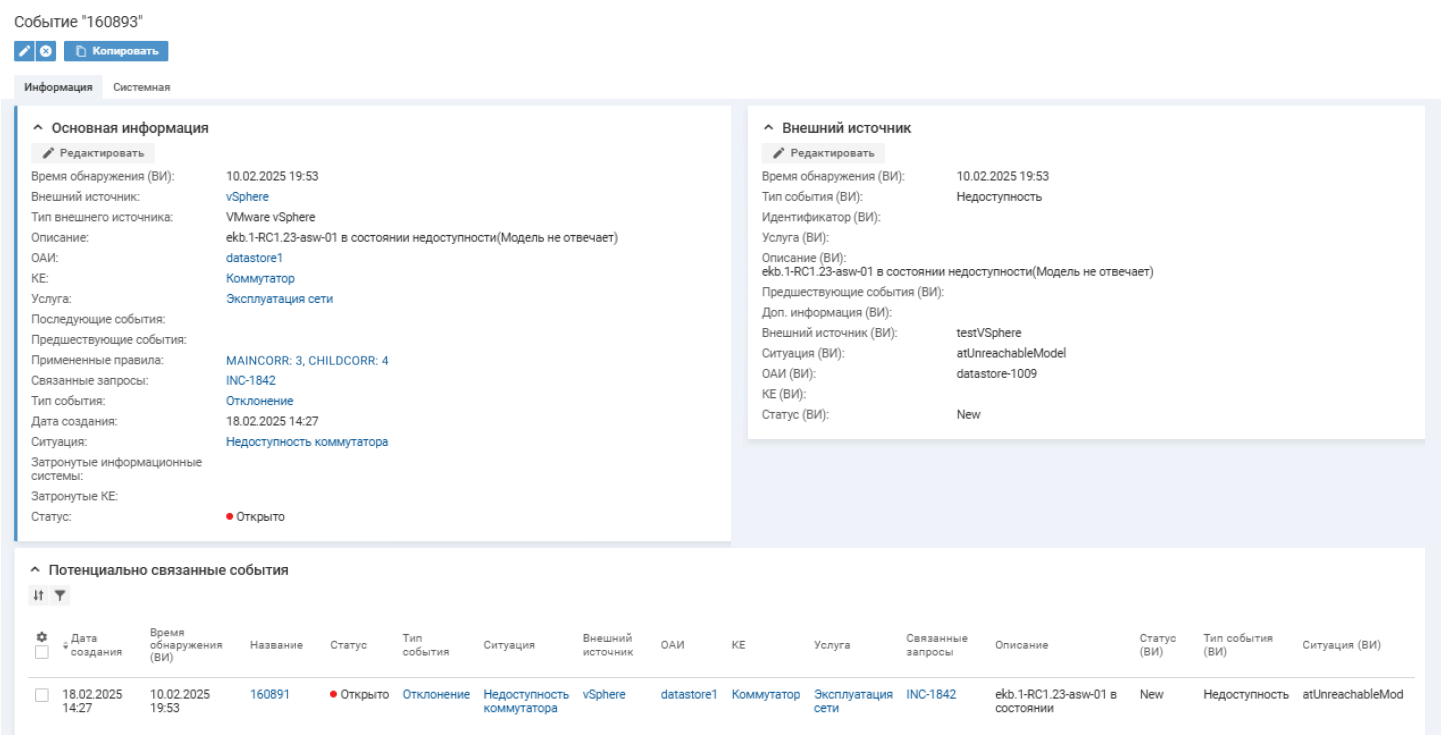
Список связанных событий отображается в карточке инцидента
Допустим, что за 15 минут коммутатор не починили. Поэтому когда это время проходит, аварийные события продолжают поступать. Система снова автоматически регистрирует инцидент по событию, которое поступает первым в рамках текущего интервала в 15 минут, а дальнейшие события «связывает» с этим инцидентом. Циклы создания инцидентов остановятся тогда, когда восстановится нормальная работа коммутатора и внешняя система мониторинга прекратит фиксировать аварии.
Представим, что работоспособность коммутатора восстановили спустя 45 минут после возникновения сбоя. За это время в Naumen BSM только по коммутатору будет зафиксировано 3 инцидента и 8 событий. Такое же количество инцидентов и событий зарегистририруется по другим устройствам, которые были недоступны во время аварии. Далее потребуется закрыть инциденты вручную, при этом автоматически закроются все связанные с этими инцидентами события.
Все связанные события закрываются автоматически при изменении статуса инцидента на «Закрыт»
К выводам
Правила типизации и корреляции в зонтичном мониторинге Naumen BSM позволяют автоматически обрабатывать данные о событиях из внешних источников. В системе устанавливается связь физического устройства с конфигурационной единицей и услугой.
Когда поступают аварийные события, система учитывает критичность услуги и делает вывод, нужно регистрировать инцидент по событию или нет. Благодаря такому подходу инциденты создаются только по тем авариям, которые нужно устранить как можно скорее. Аналогично правила корреляции позволяют сократить число инцидентов по одной и той же аварии.








