

Метрики объектов мониторинга будут ценным источником сведений о состоянии инфраструктуры, если их правильно обрабатывать. В Naumen BSM используются различные механизмы, которые позволяют анализировать метрики по отдельности и в комплексе.
В статье разбираем, как анализ метрик помогает выявлять отклонения в работе инфраструктуры и даже предсказывать возможные сбои.
Какие уровни мониторинга бывают
В системе Naumen BSM реализованы три уровня зонтичного мониторинга:
- автоинвентаризация;
- управление событиями;
- анализ метрик.
Каждый из уровней связан с определенным типом данных, которые получает зонтичная система из внешних источников, например, систем инфраструктурного мониторинга.
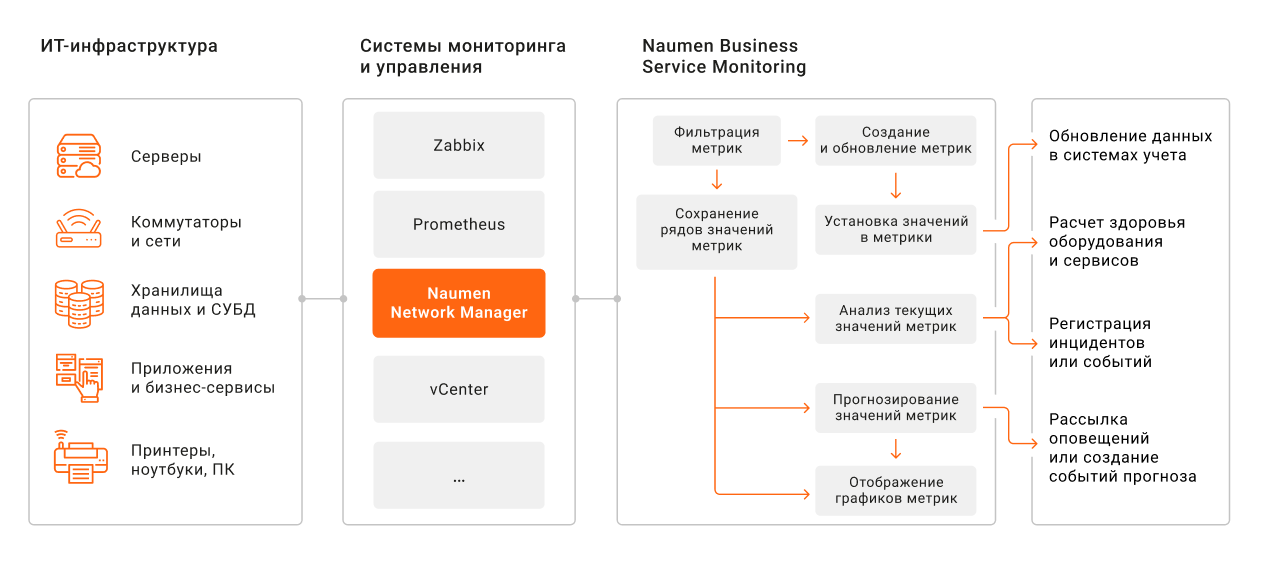
Принцип связи зонтичного мониторинга с другими источниками данных при работе с метриками
Как это работает? Naumen BSM фильтрует и обогащает данные, а затем запускает различные процессы, в том числе в смежных системах.
Автоинвентаризация. В систему поступают данные об объектах автоматической инвентаризации (ОАИ) мониторинга, например, об оборудовании или виртуальных средах. В зонтичной системе сведения обрабатываются, а затем отправляются в базу данных управления конфигурациями (CMDB) и актуализируют ее.
Управление событиями. Процесс строится на обработке данных о событиях — сообщениях об изменениях на объектах мониторинга, которые фиксируют системы инфраструктурного мониторинга. С помощью этих данных автоматически рассчитывается уровень здоровья систем и сервисов, а при необходимости регистрируются инциденты в системе управления сервисным обслуживанием.
Анализ метрик. Здесь система отслеживает текущие значения метрик, вычисляет обобщенные значения и строит прогнозы. Такая аналитика позволяет контролировать состояние инфраструктуры, вовремя обнаруживать отклонения и не допускать возникновения инцидентов.
Уровни мониторинга обладают своими преимуществами. Вместе они формируют комплексное видение инфраструктуры помогают ИТ проактивно реагировать на различные ситуации.
Типы метрик в зонтичном мониторинге
В Naumen BSM используются метрики двух типов — пассивные и активные.
Пассивные метрики — это характеристики, которые зонтичная система агрегирует из внешних источников. Показатели могут поступать, например, из Zabbix, Naumen Network Manager, VMware vCenter.
Такие метрики, например, собранные с определенного устройства, можно контролировать с помощью сводного дашборда. На нем отображаются графики нескольких метрик, при этом состав дашборда настраивается. Инфопанель помогает быстро оценивать состояние оборудования и отслеживать динамику изменения показателей, например, при расследовании инцидентов.
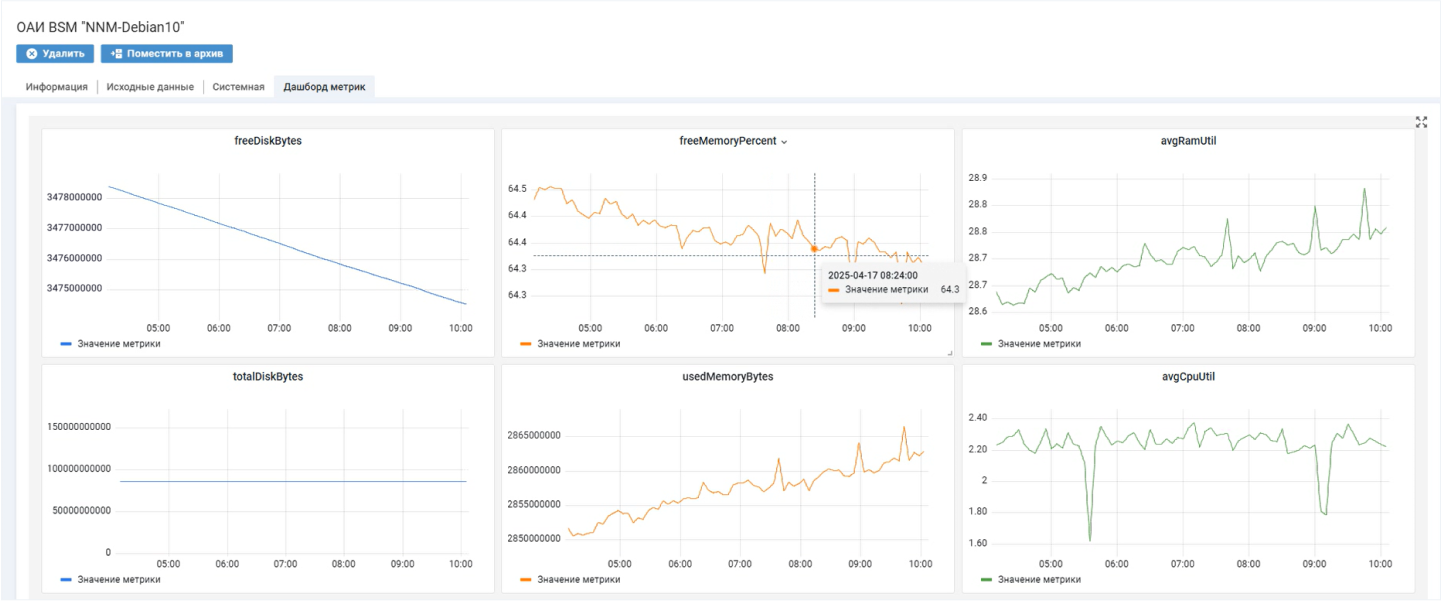
Дашборд позволяет контролировать ключевые метрики оборудования на одном экране
Активные метрики — это показатели, которые создает пользователь. Для их вычисления необходимо настроить скрипт. Они делятся на самостоятельные и обобщенные (агрегированные).
Самостоятельные метрики учитывают один показатель. Допустим,
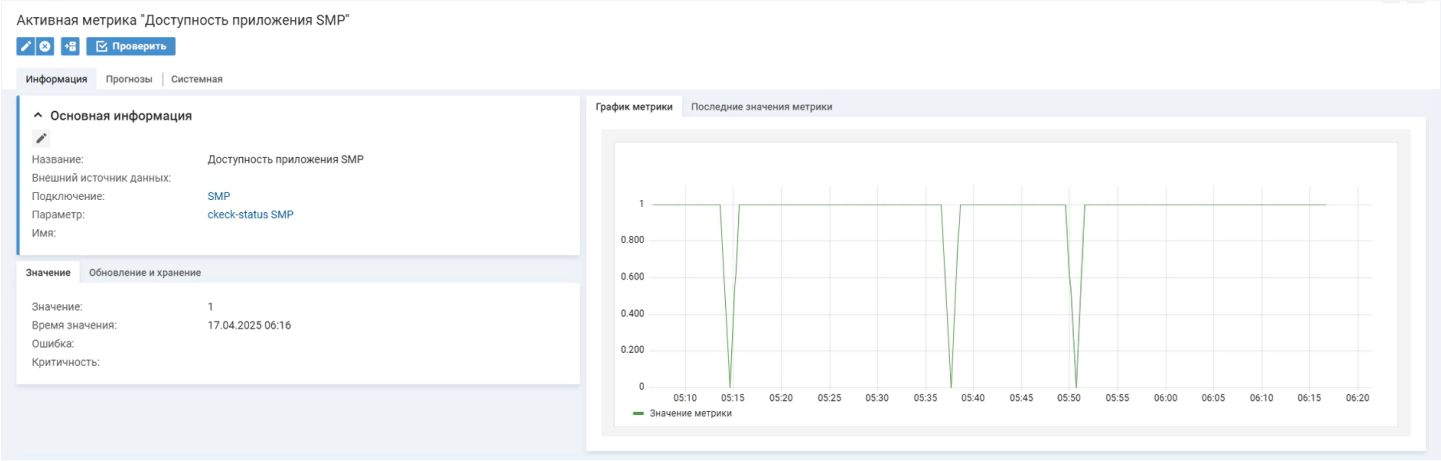
Активная метрика «Доступность приложения SMP» показывает состояние на уровне «доступен» или «недоступен»
Обобщенные метрики вычисляются с помощью комплекса показателей. Например, в Naumen BSM из Zabbix поступают данные по нагрузке процессора (CPU utilization) по каждому отдельному серверу. Несколько серверов составляют кластер, и необходимо измерять среднюю нагрузку на него. Для этого создается активная метрика. Далее скрипт вычисляет среднее значение пассивных метрик CPU utilization всех серверов кластера. В активной метрике будет храниться значение «Загрузка CPU в кластере». Также в карточке будет строиться график этой обобщенной метрики.
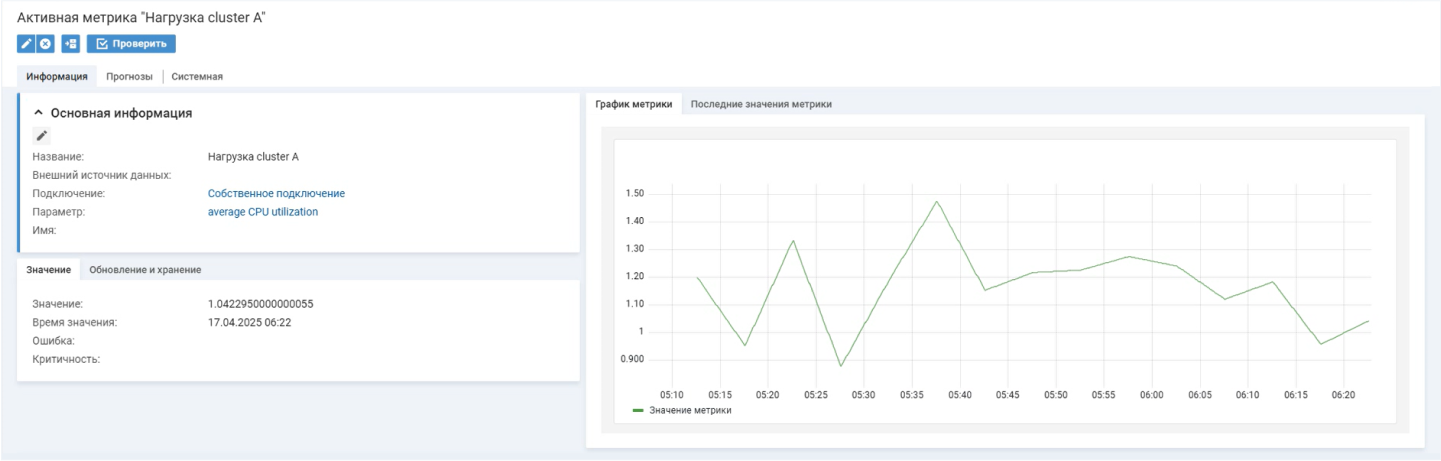
Значения обобщающих метрик сохраняются в системе, а значит, вся динамика изменений доступна на графике
Как работает обобщенный триггер
Триггер в Naumen BSM — это механизм реагирования на определенные условия. В некоторых случаях триггеры настраиваются на пороговые значения метрики. Пороговые значения — это границы, выход за пределы которых, скорее всего, сигнализирует о сбое в работе устройства.
Обобщенный триггер учитывает пороговые значения одновременно нескольких метрик. Условие срабатывания триггера гибко настраивается через скрипты. При этом предусмотрена возможность устанавливать дополнительные параметры срабатывания, например, указать задержку активации на
При срабатывании триггера в системе автоматически создается событие, которое обрабатывается в соответствии с принятыми в организации правилами. Например, регистрируется запрос на обслуживание или инцидент. Кроме того, такие события влияют на расчет здоровья объектов учета.
Допустим, Naumen BSM получает из Prometheus значение метрики «Количество сообщений в очередях Artemis», а из Naumen Network Manager — «Свободное место на диске». На основе метрик создается обобщенный триггер для контроля роста очередей в брокере Artemis. Срабатывание триггера сигнализирует о том, что система не успевает обрабатывать поток данных.
Триггер активируется, когда общее количество сообщений в очередях Artemis превысит 5 тыс., а свободное место на диске станет меньше 1 Гб. Если в триггере указан дополнительный параметр «Задержка активации», равный 10 минутам, то триггер запустится, когда система не будет успевать обрабатывать поток данных в течение указанного периода. При этом будет создано событие и зарегистрирован инцидент.
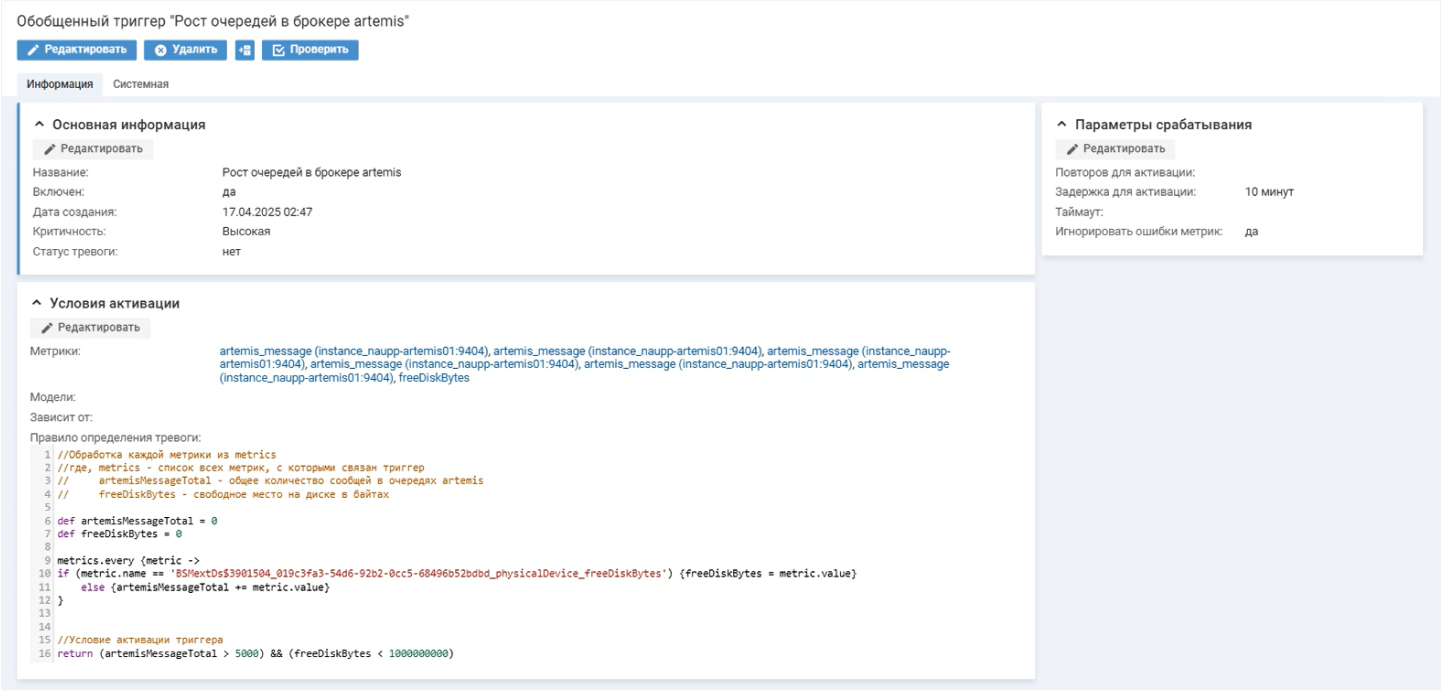
Условия активации обобщенного триггера указываются в скрипте и дополнительных настройках
Прогнозирование метрик и триггеры прогноза
Naumen BSM умеет предсказывать наиболее вероятные значения различных показателей оборудования с помощью
Дальность, или горизонт прогнозирования — это временной интервал, на который требуется рассчитать предполагаемые значения метрики. Чем больше исторических данных, тем более точный расчет на длительный период составит модель.
Допустим, в зонтичную систему из Naumen Network Manager поступают сведения по пассивной метрике freeMemoryPercent (Свободная память в процентах) для определенного сервера. Эти данные дают представление о текущем объеме доступной памяти. Чтобы получить представление о будущем состоянии памяти сервера, нужно создать модель прогнозирования по данной метрике. При этом пользователю будет достаточно указать только один параметр — желаемый горизонт прогнозирования, например, 12 часов.
Чтобы модель построила прогноз значений метрики, необходимо запустить обучение. Во время обучения модель анализирует поведение метрики на исторических данных и автоматически определяет настройки для алгоритма
Еще в системе настраиваются триггеры прогноза. Они отличаются от других триггеров тем, что учитывают не текущие, а предсказанные значения метрик.
Допустим, для метрики freeMemoryPercent (Свободная память в процентах) критическими будут значения ниже 60%. В таком случае можно настроить триггер прогноза, в котором для нижнего порога указать значение 60. Представим, модель спрогнозировала, что через 6 часов значение метрики выйдет за допустимые пределы. Далее сработает триггер, и автоматически в Naumen BSM будет создано событие прогноза.
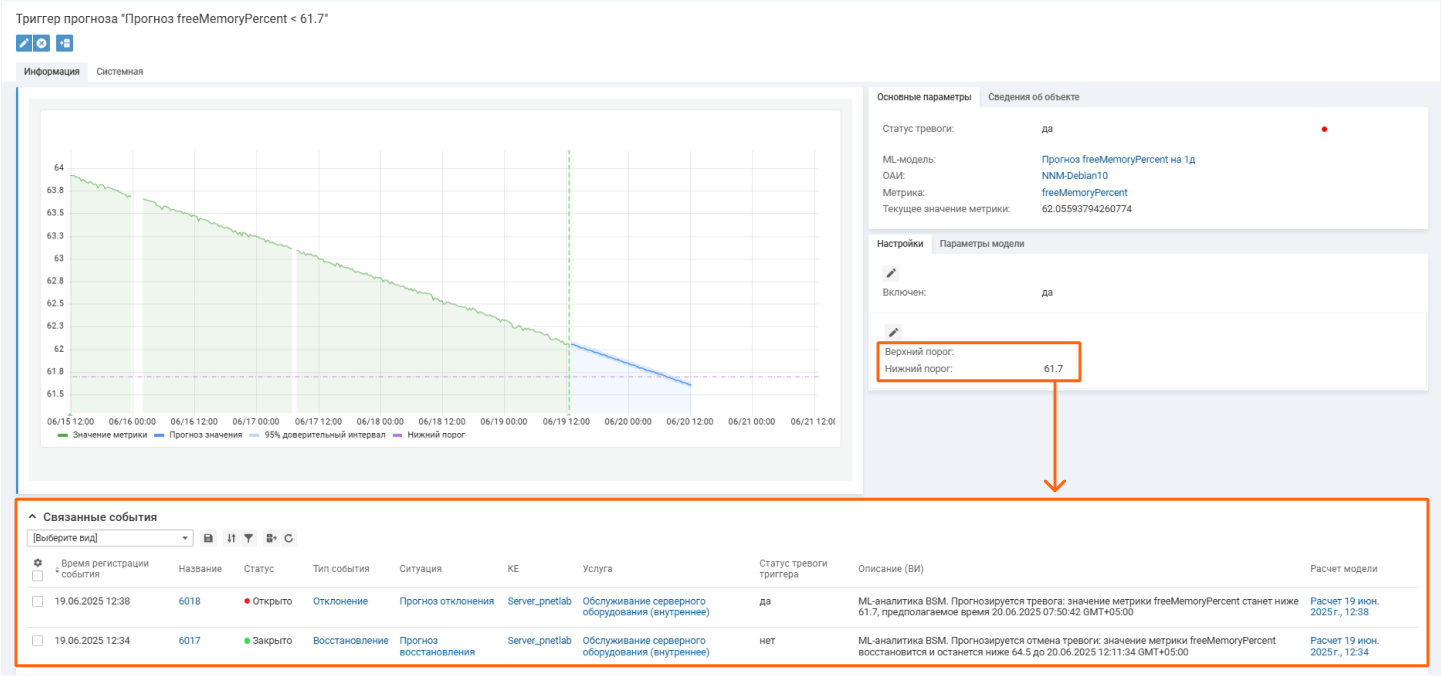
При срабатывании триггера прогноза в системе сразу добавится событие
Главное
- Процесс анализа метрик в зонтичном мониторинге помогает оценивать состояние инфраструктуры в настоящем, сравнивать с прошлыми периодами и прогнозировать в будущем.
- В Naumen BSM предусмотрены различные варианты работы с метриками. Например, можно отслеживать значения, поступающие из внешних источников, или обобщать метрики по заданным условиям.
- Текущие и прогнозируемые значения метрик контролируются с помощью триггеров. В системе заложены настройки, чтобы устанавливать различные правила для автоматического срабатывания триггеров.
- Аналитика метрик помогает
ИТ-подразделению вовремя узнавать о потенциальных сбоях в работе инфраструктуры и предупреждать возникновение инцидентов.
Остались вопросы? Хотите больше узнать о возможностях системы мониторинга? Оставьте заявку, и мы проведем подробное демо.








