

Мониторинг ИТ-оборудования давно стал обязательным требованием для бизнеса. Однако он не дает представления, как отдельные части инфраструктуры влияют на услуги и процессы в целом. Поэтому многие компании переходят к комплексному мониторингу
Что такое классический ИТ-мониторинг и зачем он нужен
ИТ-мониторинг можно сравнить с пожарной сигнализацией, которая срабатывает при определенных признаках происшествия или опасности. Только в случае с ИТ это «пожары» в инфраструктуре. В режиме реального времени отслеживаются и фиксируются сбои в работе оборудования, нарушения сетевых соединений, системные ошибки, перегрузки серверов или виртуальных машин и прочие отклонения.
Специалисты оперативно узнают о проблемах и устраняют их, что позволяет избежать негативных последствий для бизнеса. Скажем, срыва участия компании в электронных торгах
При этом следить за состоянием различных инфраструктурных элементов вручную не требуется. Такие функции выполняют специализированные системы инфраструктурного мониторинга. Они получают информацию с серверов, виртуальных машин, локальных сетей и других объектов наблюдения. В систему собираются метрики работы оборудования и задаются определенные пороги (триггеры), которые говорят об отклонениях или их риске. При достижении критических значений автоматически генерируется оповещение для
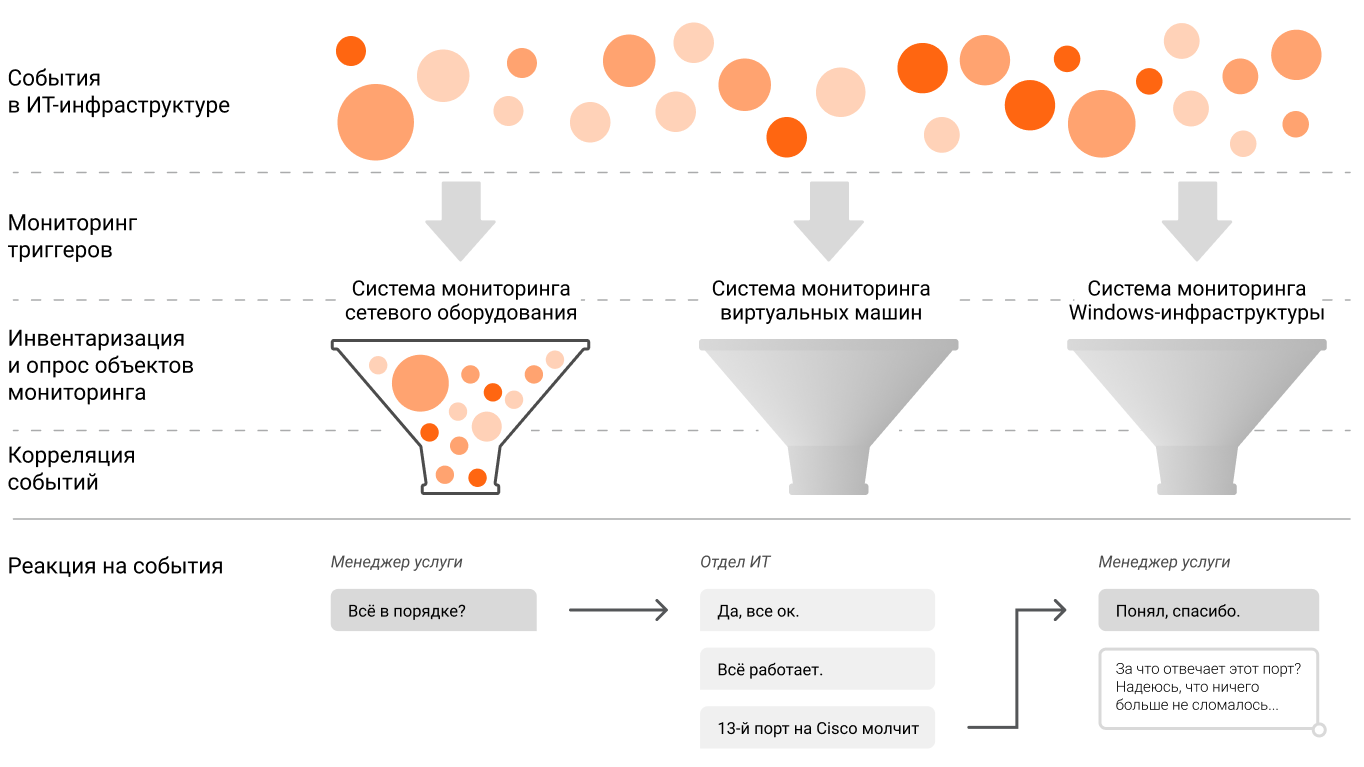
Главная задача классического мониторинга – собирать информацию по объектам инфраструктуры и отслеживать их по заданным метрикам. А при срабатывании триггера оповестить о событии
Почему классический мониторинг недостаточен для управления ИТ-услугами на высоком уровне
Зачастую в компании параллельно используется несколько систем мониторинга. Например, в одной контролируют работу сетевого оборудования, в другой — серверов и виртуальных машин на базе Linux, в третьей —
В территориально распределенных корпорациях и вовсе выстраивается целый лабиринт информационных систем, и комплексной картины по целостной услуге нет ни в одной из них. Каждым инструментом оперируют отдельные специалисты, которые поддерживают определенный инфраструктурный участок и не мотивированы выходить за его пределы. А специалисты, что отвечают за целостные
Менеджеру, который курирует
Нет понимания, как события в инфраструктуре влияют на услуги. Допустим, обнаружен перегруз мощностей виртуальной машины. Угрожает ли это работе корпоративного портала или другого сервиса? Ответить на такой вопрос менеджер может далеко не всегда. Когда услуга прерывается, ему приходится узнавать у
Нет разделения по приоритетам, какие услуги и инфраструктурные элементы наиболее критичные. Из-за этого сложно определить, какие из них требуют пристального контроля и к каким именно
Нет возможности предотвращать простои услуг. Об отклонениях и сбоях приходится узнавать постфактум вместо того, чтобы действовать превентивно и предотвращать угрозы. Ведь работоспособность каждой услуги может обеспечиваться несколькими инфраструктурными элементами, события по которым фиксируют отдельные системы мониторинга. Данные не получается связать воедино, чтобы комплексно оценить состояние сервиса и вовремя узнать о возможных проблемах.
Нет заданного алгоритма, как реагировать на фиксируемые отклонения и сбои в работе сервисов. Система мониторинга лишь сообщает о событиях, но решить проблему с ее помощью нельзя. Даже если коренная причина прерывания сервиса обнаружена, нужен четкий алгоритм действий в таких ситуациях.
Для достижения высокого уровня
Что может помешать изменить подход к мониторингу
К сожалению, обозначенные выше проблемы очевидны не всем. Некоторые стараются сохранить классический подход к
- Это зона моей ответственности: сам знаю, как правильно.
- Менять подход нет времени, поскольку нужно постоянно реагировать на сбои и управлять инфраструктурой.
- Все и так нормально работает в имеющейся системе мониторинга.
Не все специалисты имеют мотивацию к глубоким изменениям. Менеджер услуги оказывается в непростой ситуации, ведь из-за частых прерываний сервисов страдает его профессиональная репутация. Он задается логичным вопросом: а зачем вообще нужен мониторинг, который не дает понимания работы
Как обосновать необходимость мониторинга ИТ-услуг
Чтобы начать контролировать состояние
Другое дело, если менеджер услуг и
- Никто не собирается лезть в чужую зону ответственности и вмешиваться в управление инфраструктурой. Задача — понять, как работает услуга в связке с оборудованием и ПО.
- Нехватка времени и аврал в управлении инфраструктурой связаны с отсутствием комплексного мониторинга услуг. В случае прерывания сервисов
ИТ-специалистам приходится долго разбираться, где именно произошел сбой. - Даже если в конкретной системе мониторинга все четко налажено, возможны ложные срабатывания и ошибки. Настройка триггеров для метрик в нескольких системах зачастую приводят к повторяющимся или противоречащим друг другу реакциям. Если менеджер услуг будет видеть точную картину по состоянию сервисов, он не станет отвлекать
ИТ-специалистов в подобных ситуациях.
Для бизнеса же основной аргумент в пользу мониторинга услуг заключается в том, что
Если
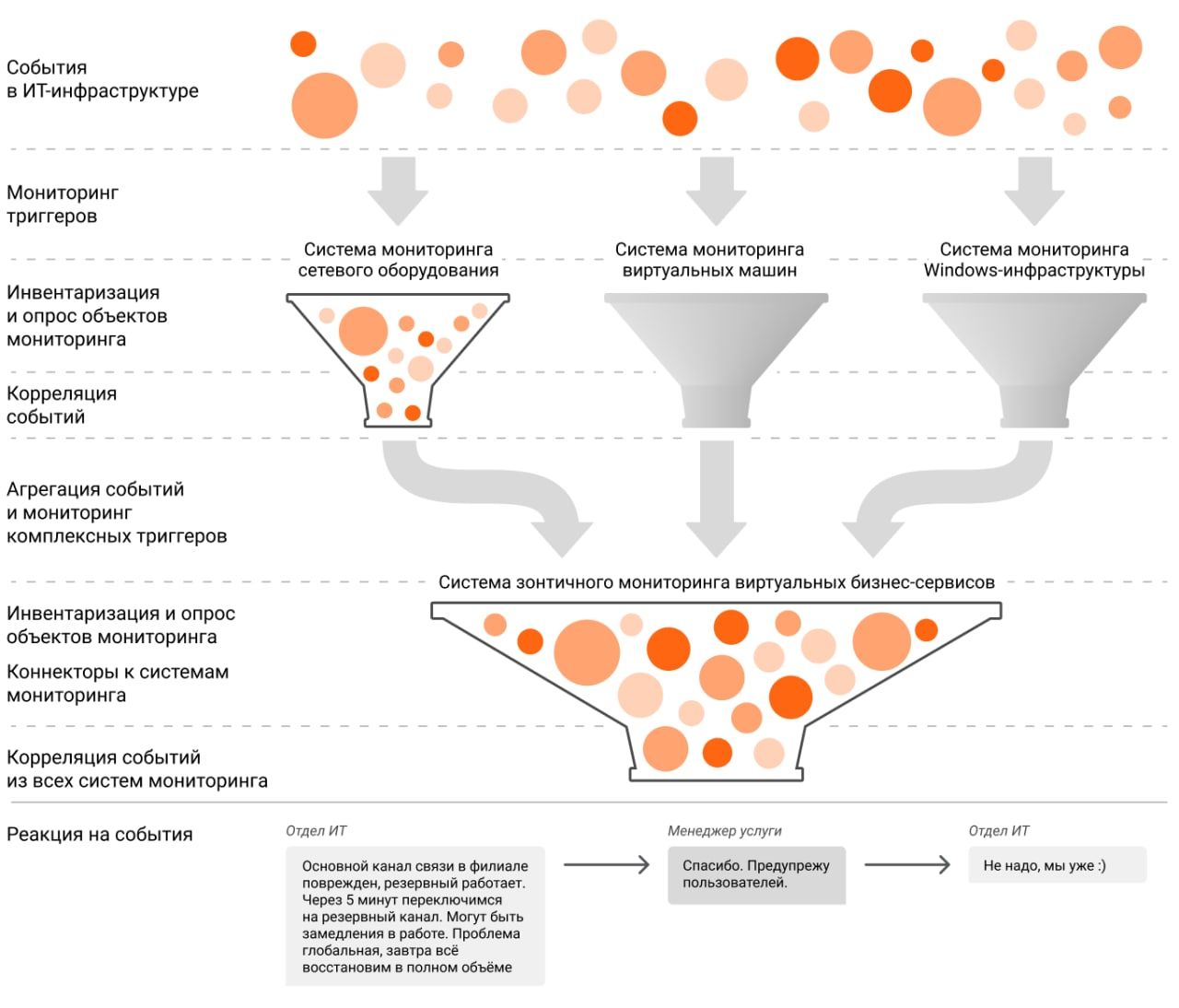
Комплексный мониторинг ИТ-услуг помогает отслеживать состояние и взаимосвязи сервисов, а также обеспечивать их непрерывность
Что дает комплексный мониторинг ИТ-услуг
Перечислим основные выгоды, которые приносит комплексный мониторинг
Получение сводных данных из разных источников. Собранные в ходе мониторинга данные концентрируются в единой системе. Это дает информационную базу для формирования
Понятная взаимосвязь между элементами инфраструктуры и
Прогнозирование отклонений в предоставлении
Построение процесса управления событиями. Это позволяет реализовать единые правила реагирования на отклонения и автоматизировать реакцию на них. К примеру, если в организации применяется инструмент Service Desk для управления поддержкой пользователей, то из системы зонтичного мониторинга можно отправлять туда критичные события, влияющие на услуги. Там автоматически будут создаваться и направляться нужным специалистам заявки на устранение зафиксированных инцидентов.
Повышение точности данных и исключение ошибок. Приведение метрик и триггеров в единый формат и настройка их по общим параметрам позволят избежать возникновения противоречащих событий и ложных срабатываний.
Аналитика и визуализация состояния
Конечно, построение мониторинга









