

В любом подразделении эксплуатации и технической поддержки происходят типовые ситуации. К примеру, мониторинг фиксирует падение коммутатора, и вся цепочка подключенного оборудования становится недоступной. Начинается шторм тревог. При аварии важно не терять ни секунды.
Несмотря на работу современных систем мониторинга, они дают лишь верхнеуровневый сигнал, что оборудование вышло из строя. Чтобы действительно устранить инцидент, инженерам часто не хватает данных: где физически установлен коммутатор, какие сервисы и сегменты через него проходят, как построены схемы коммутации и сварки волокон, по каким линиям идет трафик, кто отвечает за площадку.
В статье разберем, как с помощью Naumen Inventory можно локализовать и устранить такую аварию: оценить ситуацию, найти решение и быстро восстановить работоспособность сети.
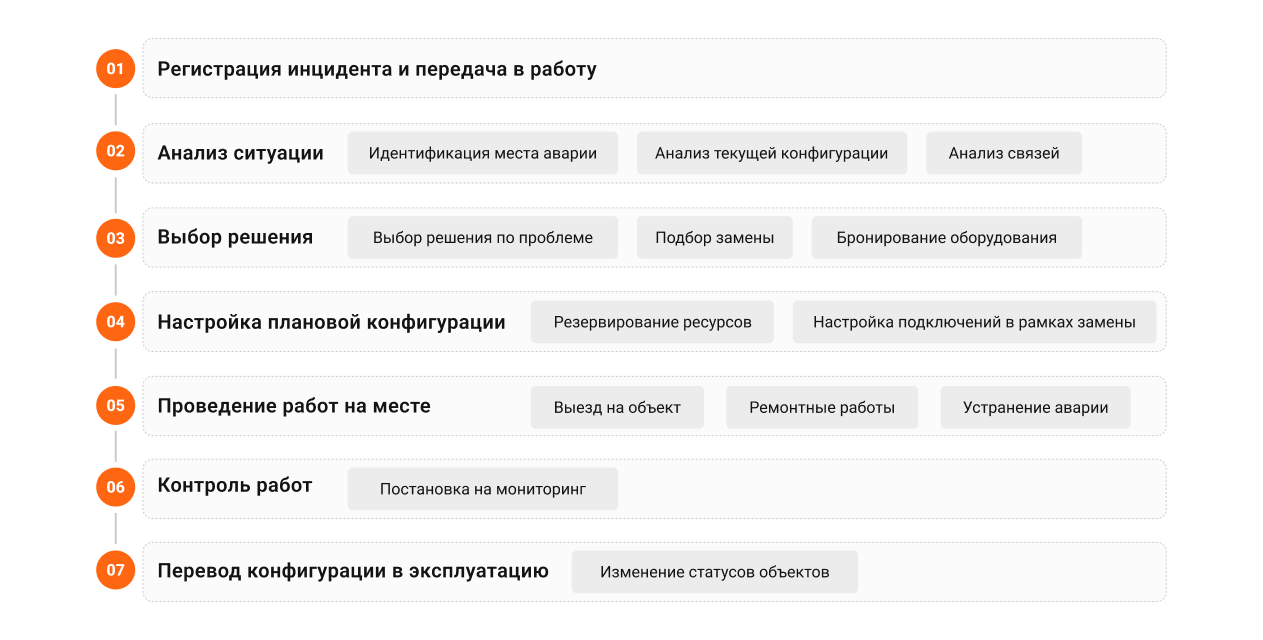
Как устранить аварию в сети за 4 шага
Устранение инцидента делится на несколько шагов: анализ текущего состояния сети, выбор решения по устранению аварии, планирование изменений, выполнение работ на месте и завершение задачи. На каждом шаге инструменты системы учета помогают специалистам действовать быстрее и точнее.
Опыт Naumen показывает, что в первые минуты после аварии важнее всего понять, что именно вышло из строя и какие узлы задеты. В сложной распределенной инфраструктуре это возможно, когда у инженера под рукой детальная схема связей и актуальная информация об объектах сети. Именно такую опору дает Naumen Inventory на всех этапах работы с инцидентом.
Рассмотрим основную функциональность системы на примере ситуации с вышедшим из строя коммутатором.
Этап 1. Анализ ситуации
Информация о сбое чаще всего поступает из систем мониторинга или фиксируется
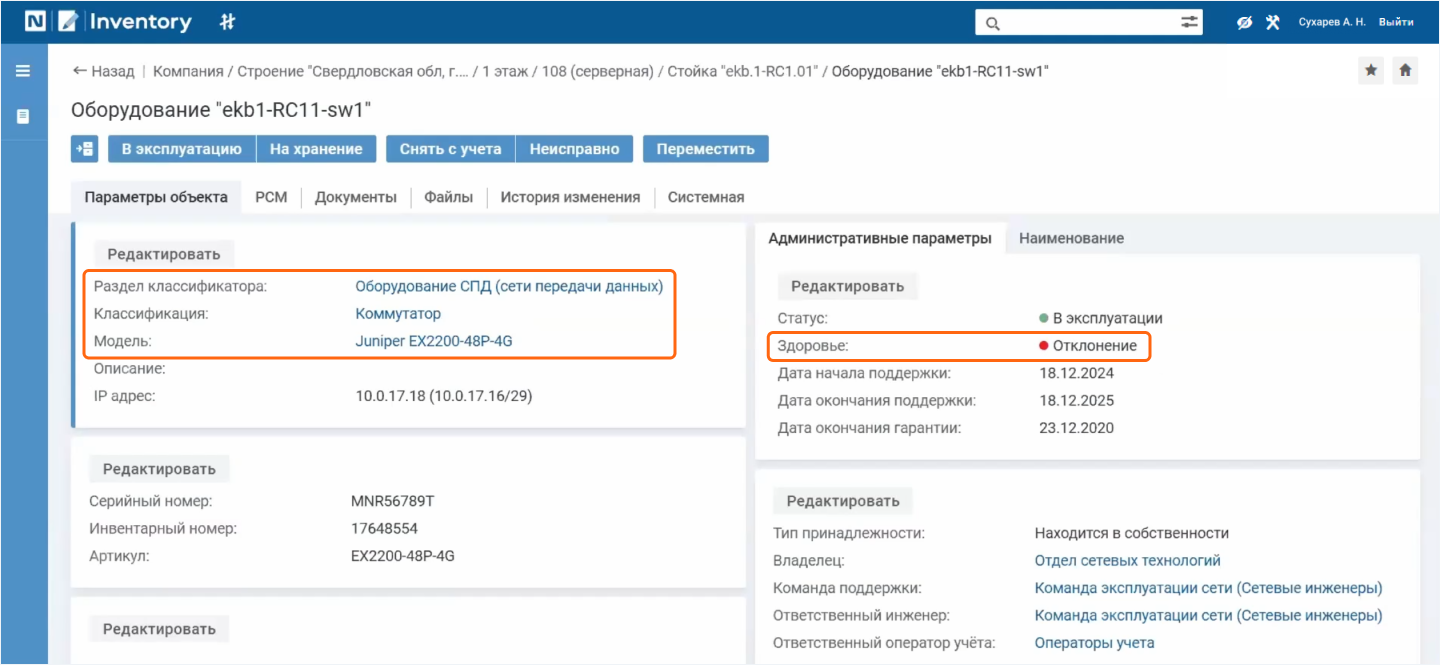
В карточке отражено, что от системы мониторинга пришло событие об отклонении здоровья оборудования
Чтобы понять, какие сервисы и приложения могут пострадать
В схеме можно включить режим «Здоровье», основанный на данных из систем мониторинга. Коммутатор отмечен красным, а серверное оборудование, которое к нему подключено, — желтым. Это значит, что медлить с решением проблемы нельзя.
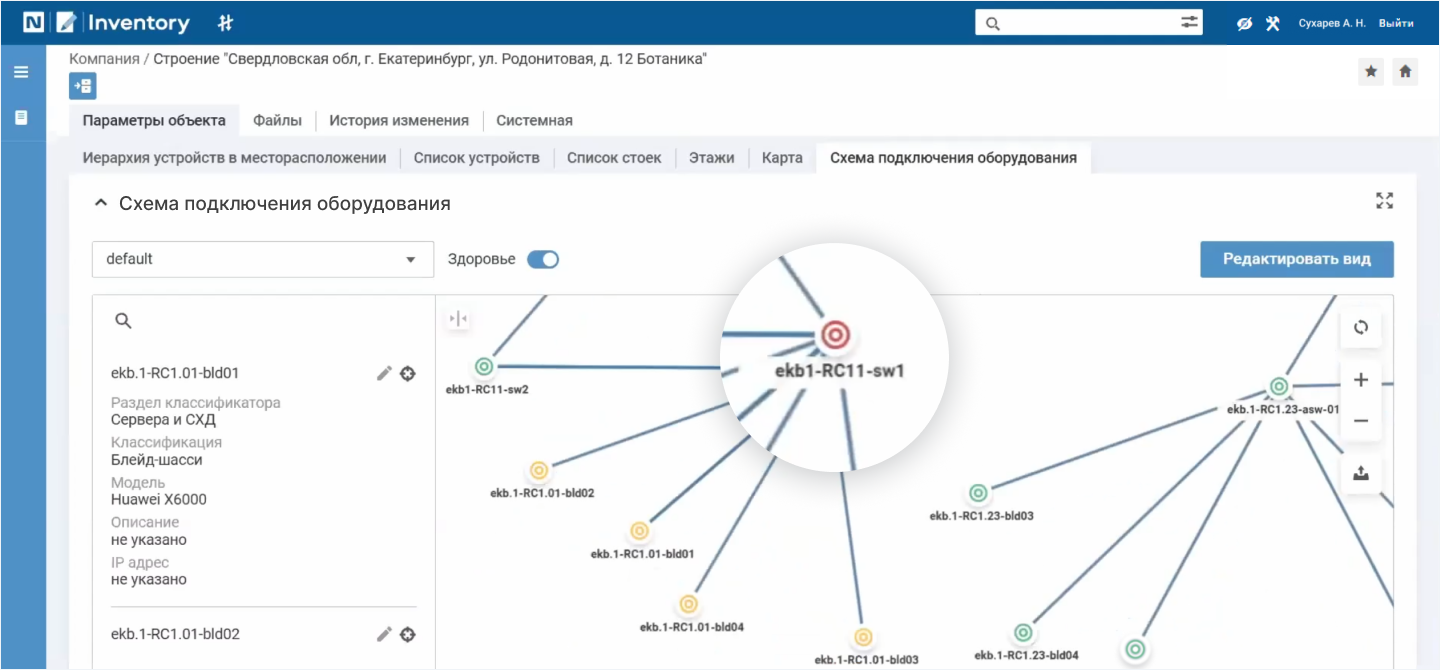
Индикатор неисправного коммутатора выделен красным цветом, а затронутого оборудования — желтым
Этап 2. Выбор решения
После анализа влияния аварийной ситуаций на связанную инфраструктуру и сервисы необходимо провести быструю замену оборудования. Это позволит сохранить доступность серверов, в том числе виртуальных кластеров и корпоративных приложений.
Inventory позволяет вести учет оборудования, доступного на складе, содержит информацию о моделях, включая характеристики, структуру компонентный состав, изображение и графическое представление фасадов, а также портовую емкость.
Система автоматически проверяет наличие экземпляров коммутаторов аналогичной модели на складе. Если аналогичного устройства нет, система позволяет подобрать альтернативу из списка моделей по необходимым характеристикам.
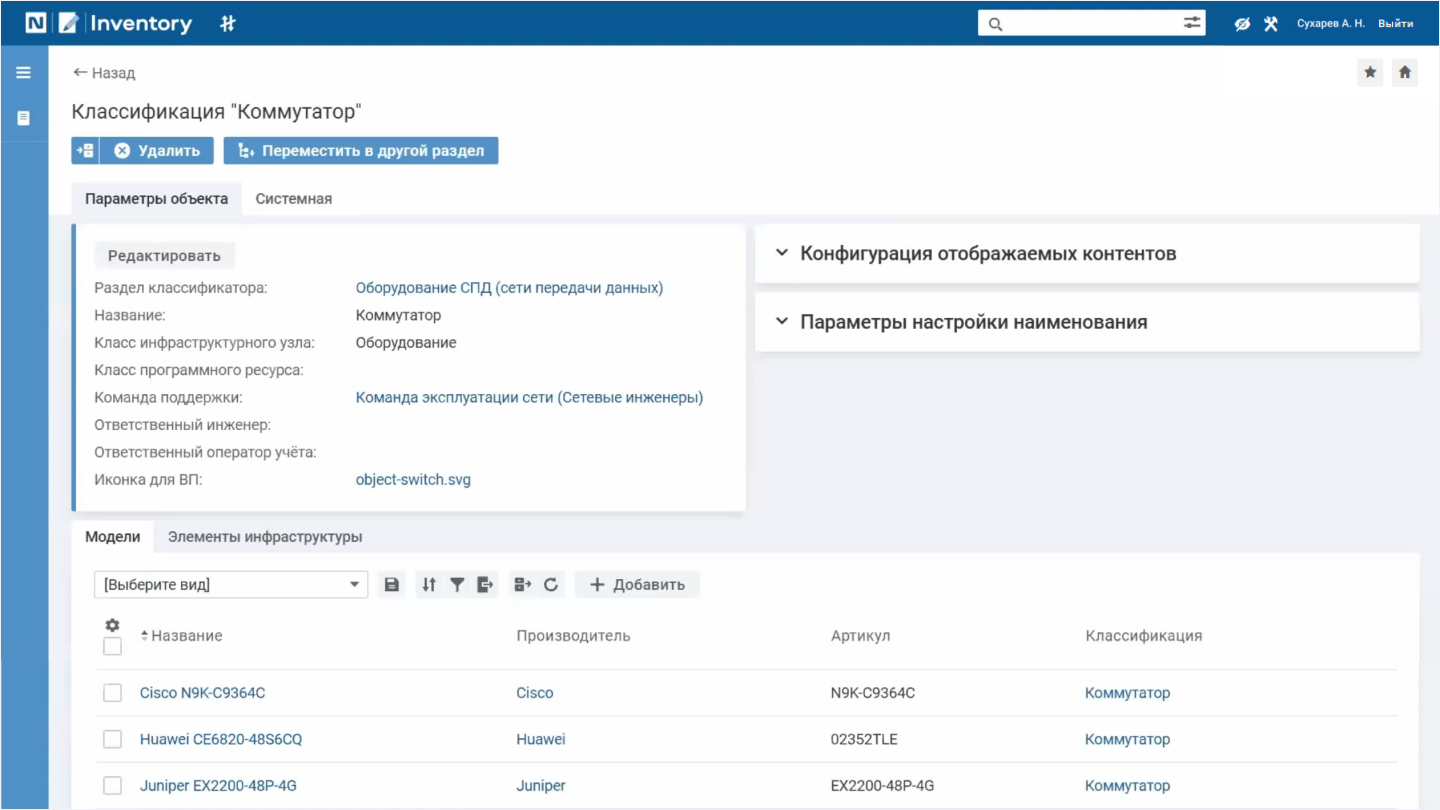
Список включает все коммутаторы на балансе организации
Перейдя в раздел «Элементы инфраструктуры модели», можно убедиться, что выбранное устройство есть на складе, и сразу забронировать оборудование для проведение ремонтных работ.
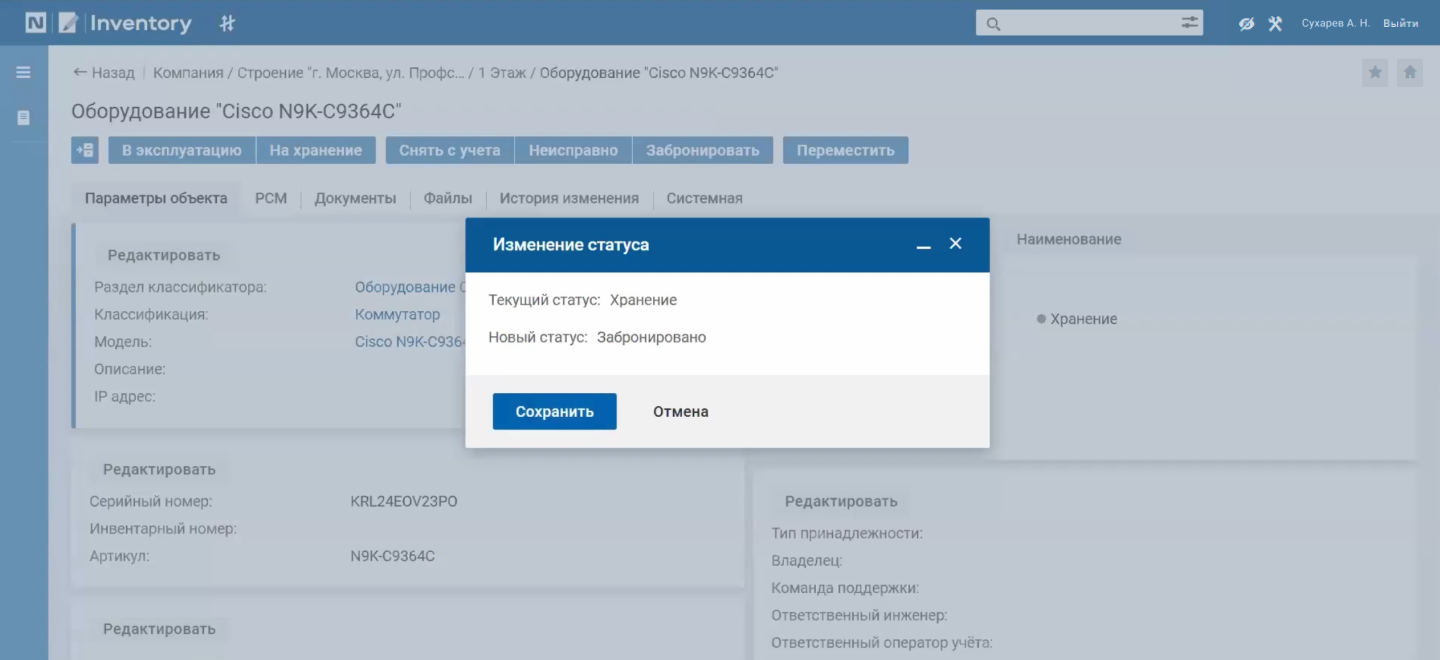
Система позволяет бронировать не только оборудование, но и другие ресурсы
Также необходимо оценить габариты новой модели. Она больше той, что сломалась, и занимает два юнита вместо одного. В нашем случае это не проблема.
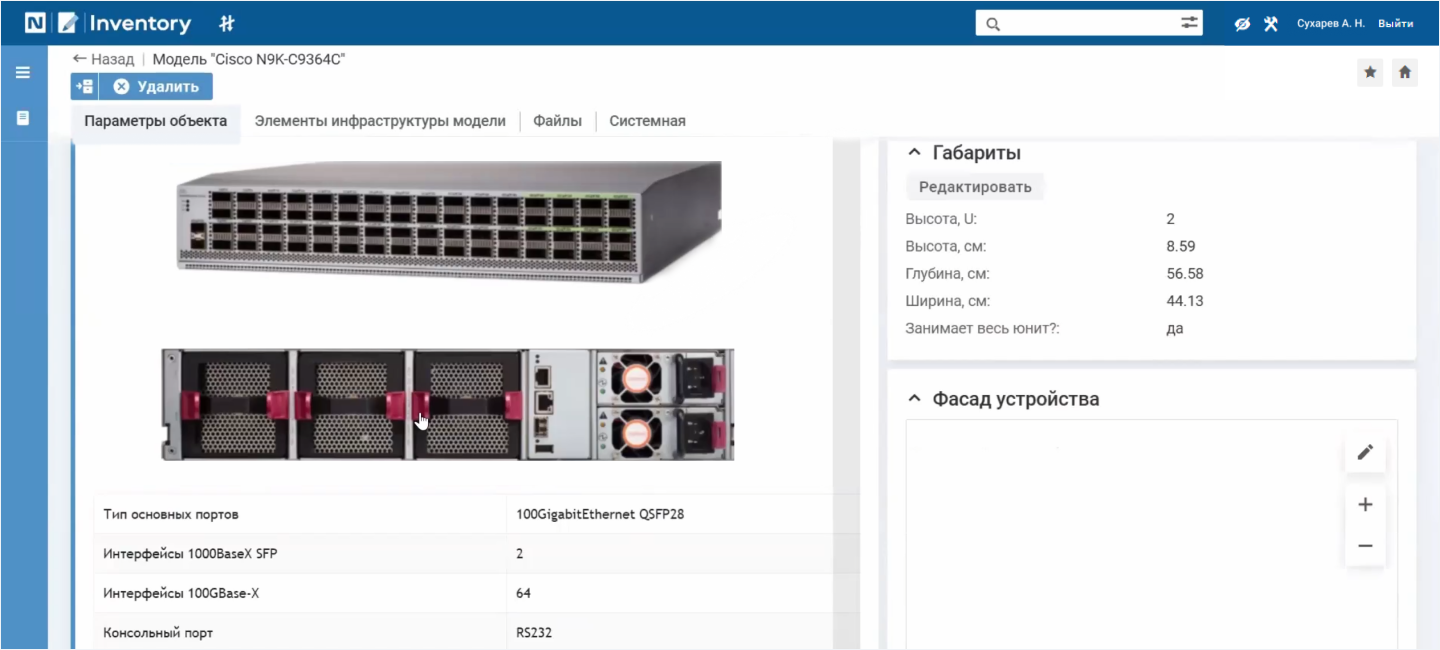
В карточке модели отражены все необходимые параметры, включая фото, типы основных портов и габариты
Этап 3. Настройка плановой конфигурации
Для настройки плановой конфигурации подключения нужно освободить юниты для нового оборудования. Для этого в карточке стойки в графическом представлении извлекаем неисправный коммутатор и бронируем два юнита для нового устройства.
После согласования отправляем устройство в точку эксплуатации. Для этого в карточке коммутатора выбираем опцию «Переместить». После заполняем адрес, где располагается неисправное оборудование. Техника автоматически перемещается в эту точку. Все изменения остаются в статусе «Запланировано».
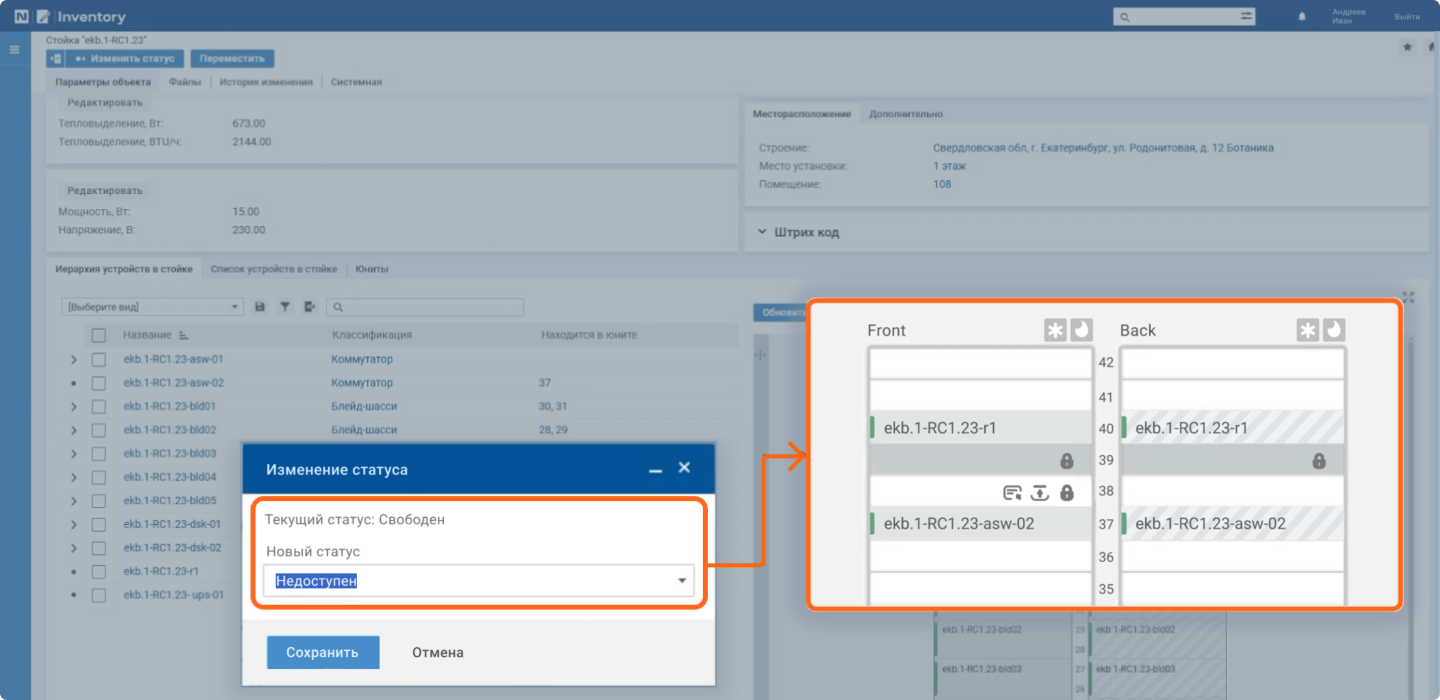
Система позволяет выполнять операции с оборудованием используя графическое представление фасада стойки
Далее в карточке нового устройства осуществляем перемещение со склада на место будущей установки. Выбираем опцию «Переместить» и заполняем адрес, где располагается неисправное оборудование. Техника автоматически перемещается в эту точку. Все изменения остаются в статусе «Запланировано».
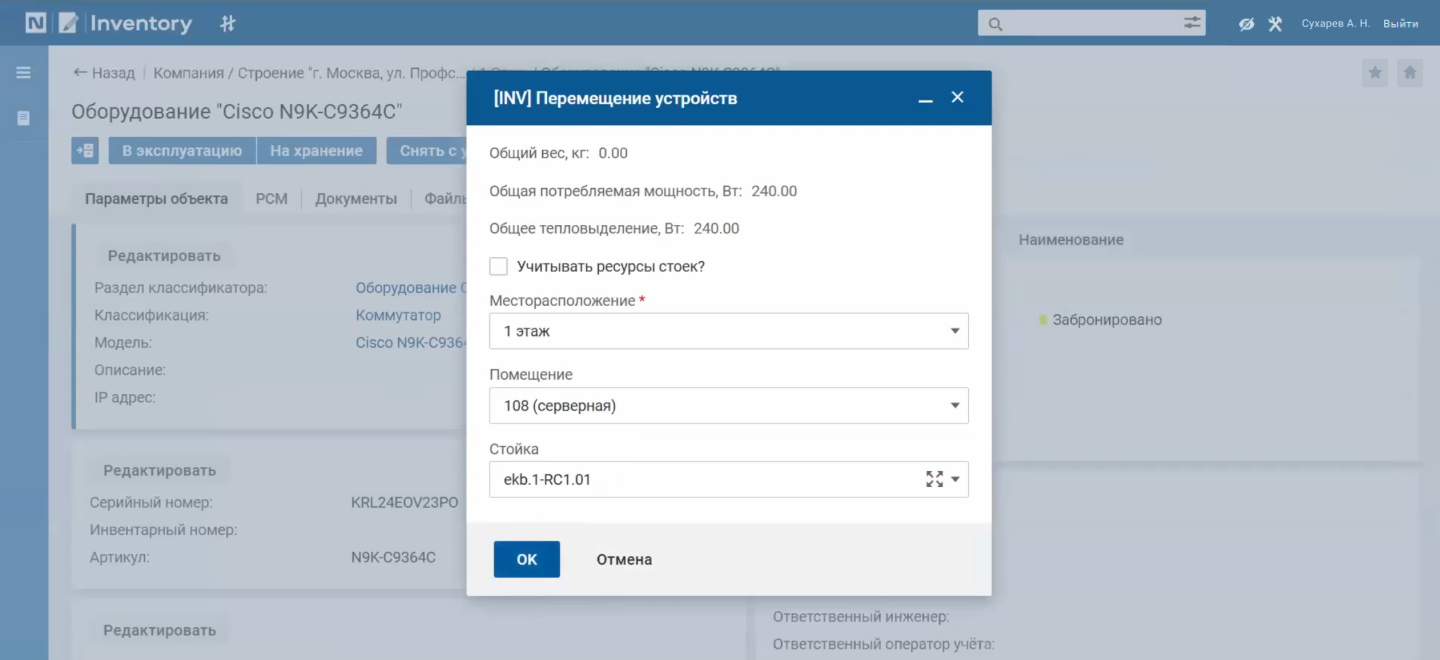
При перемещении устройства достаточно ввести часть адрес. Далее система предложит подходящие варианты
Затем размещаем коммутатор в стойке, используя забронированные ранее юниты. После этого можно перенести все подключения в новое устройство. Если на данном этапе критично сохранить условия коммутации в соответствии с подключениями на неисправном устройстве, лучше выполнить подключения точечно непосредственно в карточке устройства. Сделать это можно из списка подключений или в графическом представлении фасада коммутатора.
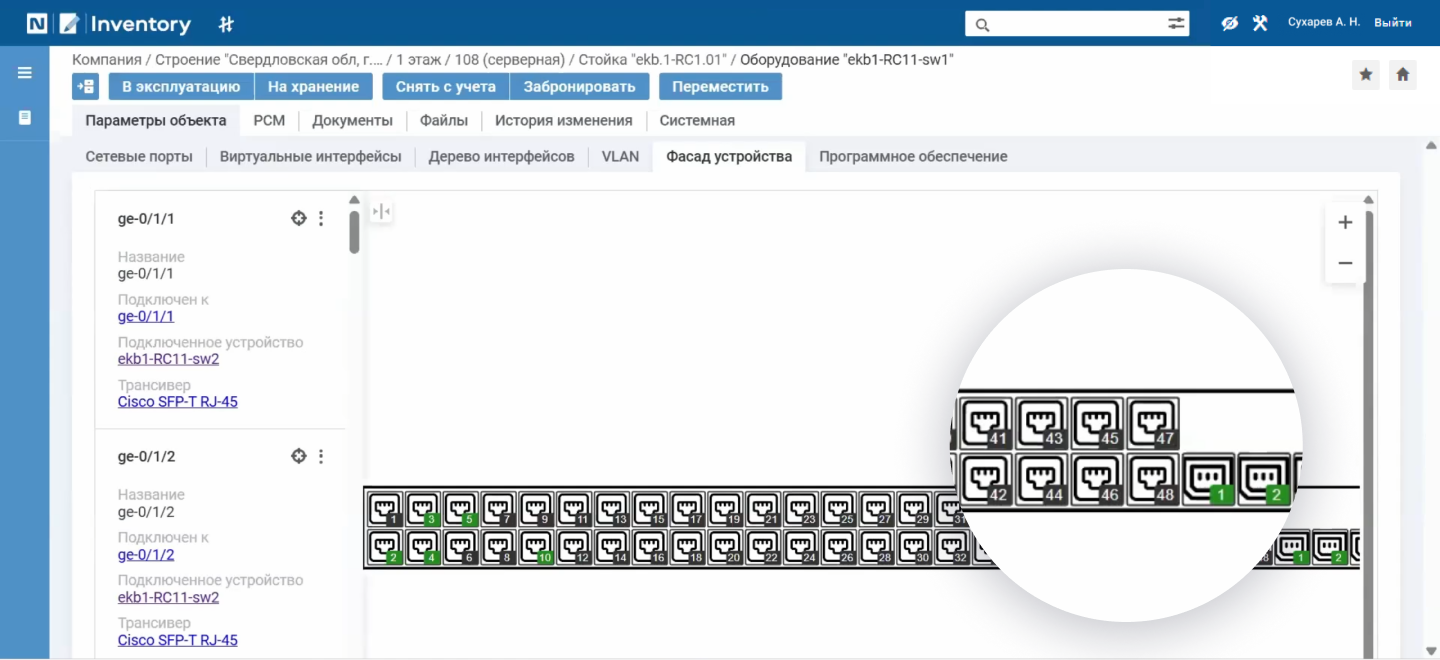
Перенос подключений на новое устройство
Если такой необходимости нет, можно прибегнуть к опции массового перемещения: выбрать разъемы, извлечь все трансиверы и переподключить их в новое устройство. Эта функция значительно ускорит процесс и сэкономит время.
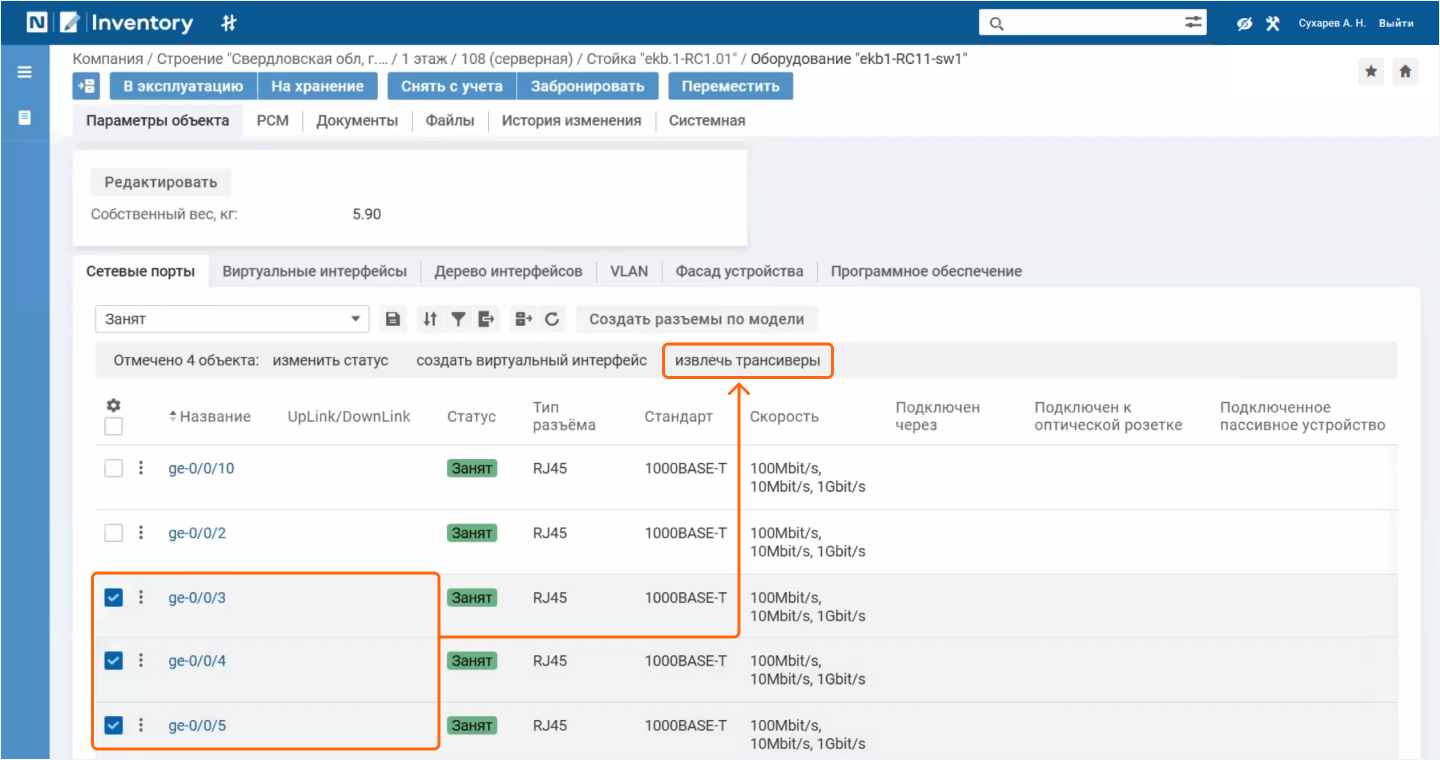
Переподключение можно выполнить не только непосредственно из фасада коммутатора, но и из списка
Этап 4. Перевод конфигурации в эксплуатацию
Далее остается дождаться согласование плановой конфигурации, разработанной для решения инцидента и выполнить работы на месте аварии. После проведения замены оборудования и проверки настроенного нового подключения, в системе появляется подтверждение от системы мониторинга, что новое устройство работает корректно и все сервисы восстановлены.
В этот момент плановую конфигурацию можно перевести в эксплуатацию, изменив статус в системе, указав тип принадлежности оборудования вручную, либо автоматически поставить на ответственность команды, курирующей площадку.
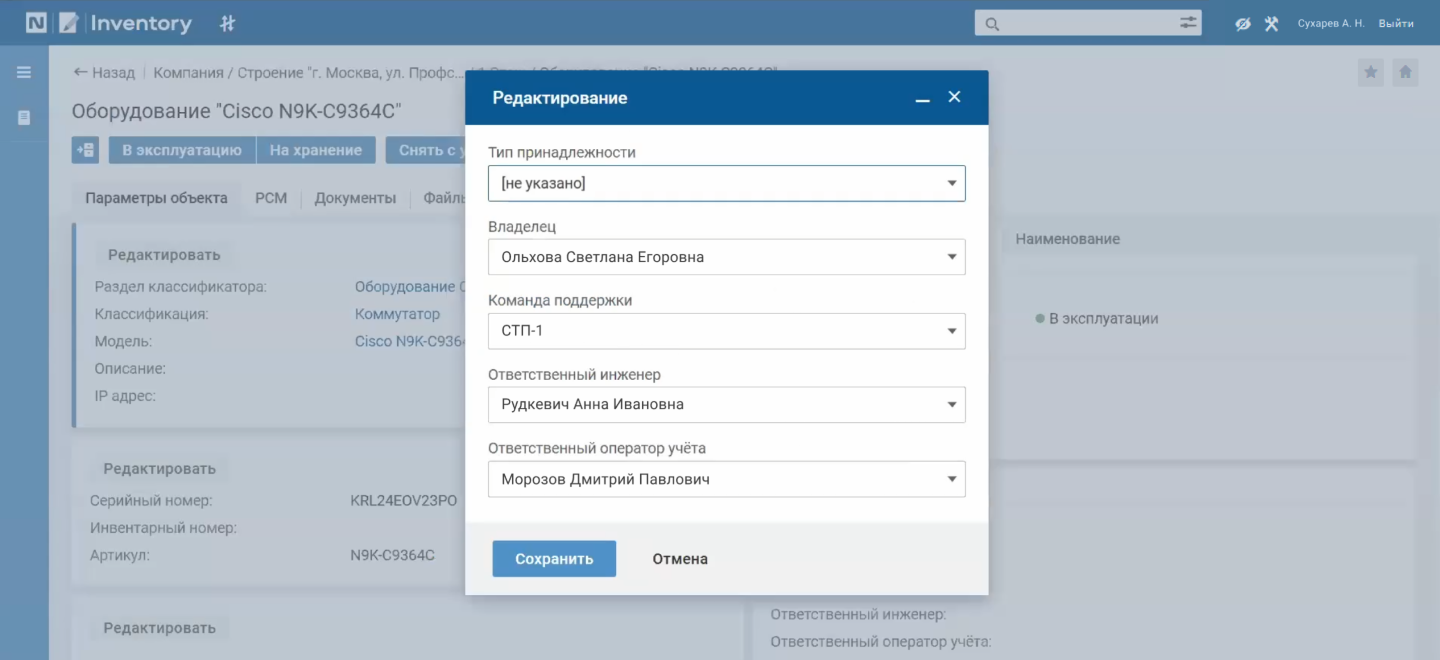
Система позволяет указывать разные типы принадлежности
Таким образом, централизованная система технического учета позволяет решать инциденты, происходящие в сети.
Главное
Naumen Inventory дает четкий алгоритм работы с аварией — от первичного анализа до ввода обновленной конфигурации в эксплуатацию. Система помогает быстро оценить последствия, выбрать оптимальное решение, найти и забронировать нужные ресурсы, а затем безопасно перенести подключения в новое оборудование. Таким образом время устранения инцидента сокращается, что снижает риски для бизнеса. Это особенно актуально в сложной распределенной инфраструктуре, где на счету каждая минута простоя.








