

Чтобы вовремя заметить в работе устройства признаки возможного сбоя, операторам инфраструктурного мониторинга Naumen Network Manager (NNM) не нужно неотрывно наблюдать за каждой метрикой, которую он собирает. Система сама сообщит, если обнаружит, что полученные значения требуют внимания. Посмотрим, как это происходит.
Как система понимает, о чем сообщать
Мониторинг собирает заданные метрики с объектов инфраструктуры. Все, что с ними происходит при функционировании, и о чем говорят снятые метрики, классифицируется как событие. Например, изменение показателя занятой памяти на сервере. Если событие выходит за рамки нормативных показателей, оно переходит в разряд аварий, и система должна сообщить об этом пользователям: операторам мониторинга и специалистам, которые отвечают за оборудование.
Naumen Network Manager содержит шаблонные настройки для всех типов объектов мониторинга, которые позволяют системе распознавать аварии. Например, это:
- превышение допустимой утилизации ресурсов на сервере (CPU, RAM, HDD и т. д.);
- превышение показаний температуры устройства;
- выход значения частоты источника электропитания за пределы допустимого диапазона;
- превышение значения TX/RX утилизации сетевых интерфейсов;
- несоответствие оперативного и административного статуса сетевых интерфейсов и др.
Организации могут корректировать настройки исходя из особенностей управления своей
Каждому из них соответствует свой цвет. После того как системе заданы все нормы и ориентиры, она знает, о чем нужно сообщать.
Еще одна ценная возможность — настройка уведомлений об аварийных прогнозных показателях. Для любой измеряемой метрики в NNM применяются алгоритмы предиктивной аналитики — средства интеллектуального анализа и прогнозирования с использованием моделей ARIMA и RNN. Суть в том, что собирают показатели той или иной метрики за период, а система выявляет динамику и рассчитает прогнозные значения. Если этот прогноз содержит значения, которые не укладываются в норму, NNM оповестит. Это позволит заметить проблему раньше, чем она даст о себе знать, и предотвратить сбои в работе оборудования и предоставления сервисов.
Способы уведомления об авариях
Naumen Network Manager умеет отправлять информацию разными путями и учитывает, что решением пользуются разные специалисты. Операторы мониторинга — это своего рода оперативные дежурные, которые следят за работой системы, а также за состоянием происходящих аварий.
| Способ | Плюсы | Кому подходит |
| Вывод списка аварий | Настраиваемый список с различными параметрами | Оператору |
| Виджет «Топология» | Отображение в контексте локации и классификации объекта | Оператору | Виджет «ГИС» | Отображение объектов и связей между ними на карте с привязкой к географическим координатам | Оператору |
| Push-сообщения в системе | Моментальное оповещение в момент получения метрики | Оператору |
| E-mail, SMS, Telegram | Моментальное оповещение в момент получения метрики | Ответственному специалисту |
| Интеграция | Автоматизация всей цепочки заведения и обработки инцидента | Ответственному специалисту |
| Цепочки уведомлений | Комбинирование нескольких способов | Оператору, ответственному специалисту |
Вывод списка аварий
В NNM есть раздел «Аварии». В него списочно попадают все зафиксированные системой ненормативные события. Строка с каждым выделена цветом, который соответствует уровню критичности конкретной аварии.
Через контекстное меню списка с помощью пункта «Атрибуты» можно перейти непосредственно к компоненту, на котором зафиксирована авария, через пункт «Факты» — просмотреть и при необходимости отредактировать правило, по которому была зафиксирована авария. А пункт «Принять в работу» присваивает ей соответствующий статус и позволяет прописать произвольный комментарий,что удобно при многопользовательской обработке сообщений.
В крупной компании при наличии обширной
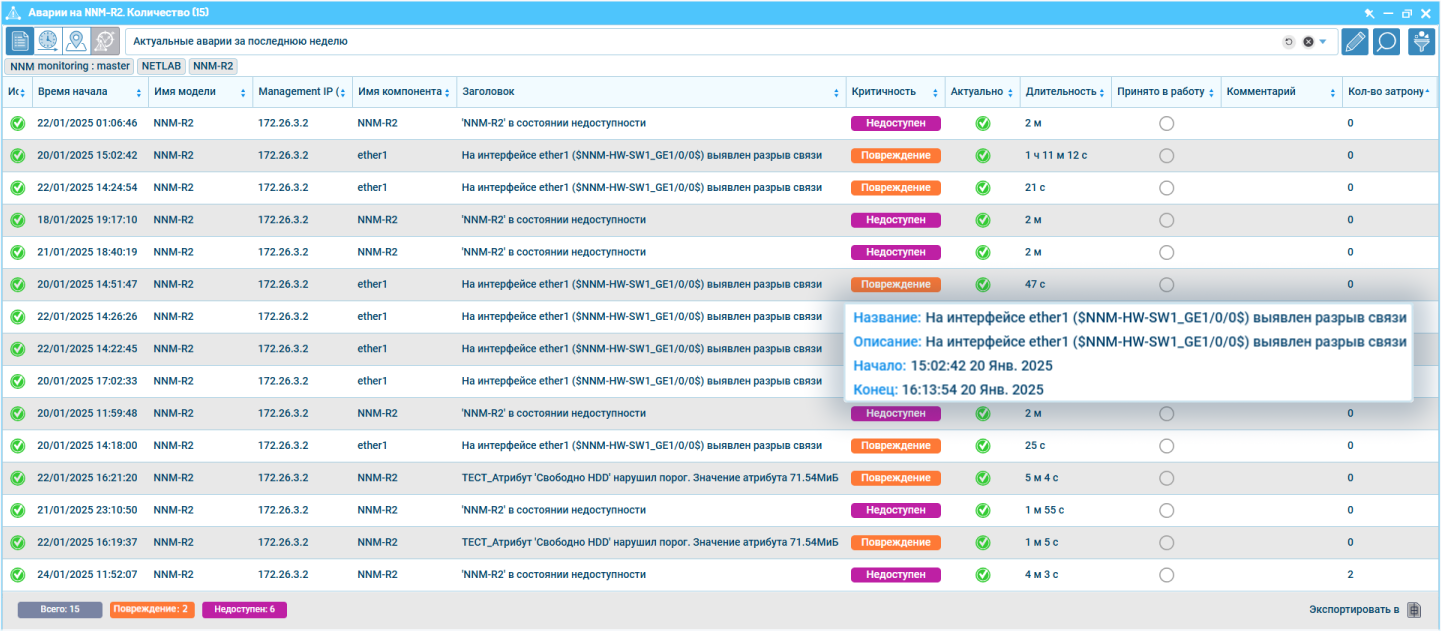
С каждой строки можно перейти в карточку аварии, узнать подробности, взять в работу, изменить статус, оставить комментарий
На основании списка активных аварий или истории аварий пользователь может оперативно создавать свои правила корреляции, которые впоследствии станут основанием для группировки различных аварий, позволяя быстрее понять первопричину.
Виджет «Топология»
NNM содержит схему инфраструктуры, на которой иконками отмечены все ее объекты. Если они в норме, то иконки зеленого цвета. Если на
Данный интерфейс дает возможность классифицировать объекты по признаку: типу, местоположению, ответственному и др. — и разложить их в разные папки. Эти папки в NNM называют контейнерами. Каждый содержит список элементов, которые к нему относятся, и обозначается иконкой. Например, зеленой, если с содержимым папки все в порядке.
Если на
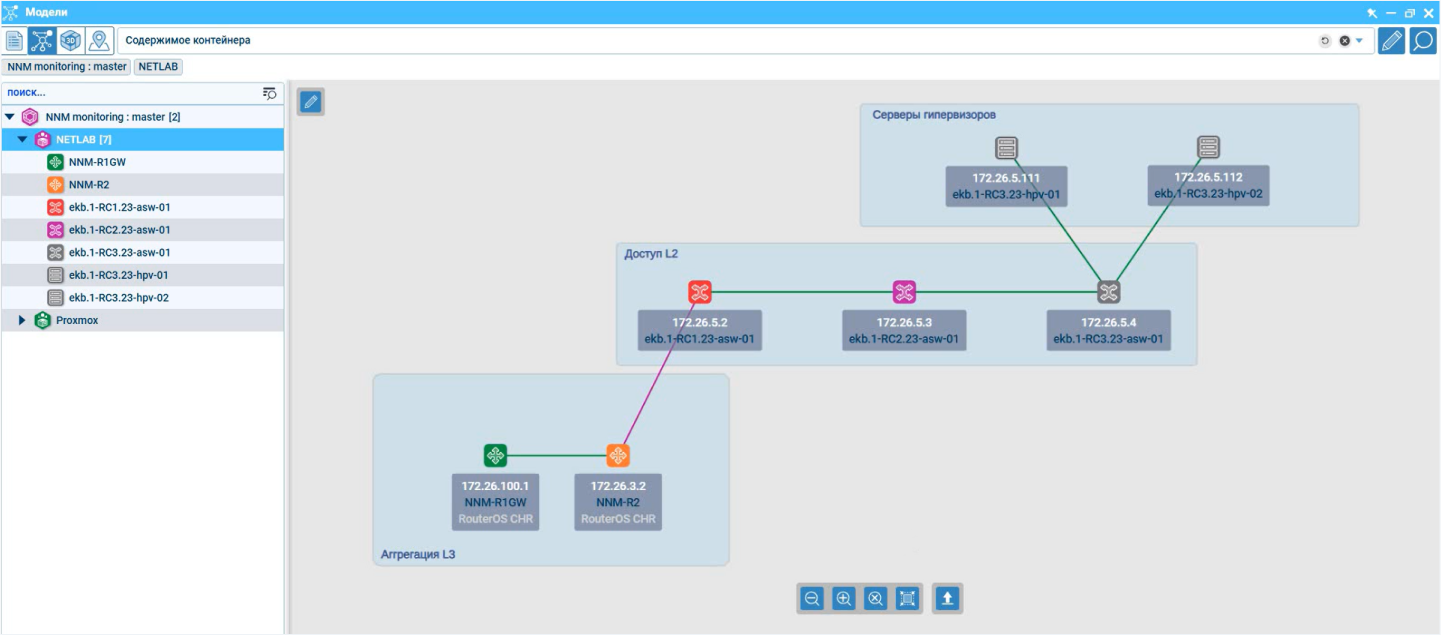
Уже по списку контейнеров и цвету иконок можно получить представление о состояние внутренних объектов
Виджет «ГИС»
Виджет предназначен для отображения на карте объектов мониторинга, в атрибутах которых определены широта и долгота. При уменьшении масштаба карты устройства группируются, и отображается сколько их в данной области карты, цветовая индикация в соответствии с текущей аварийностью и статистика по их состоянию.
Таким образом виджет «ГИС» наглядно отображает здоровье инфраструктуры в той или иной геолокации. Видно, сколько в ней устройств, на круговой диаграмме кластеров показано процентное соотношение здоровых и аварийных объектов, а при наведении курсора на геокластер можно получить детальную информацию по количественным показателям.
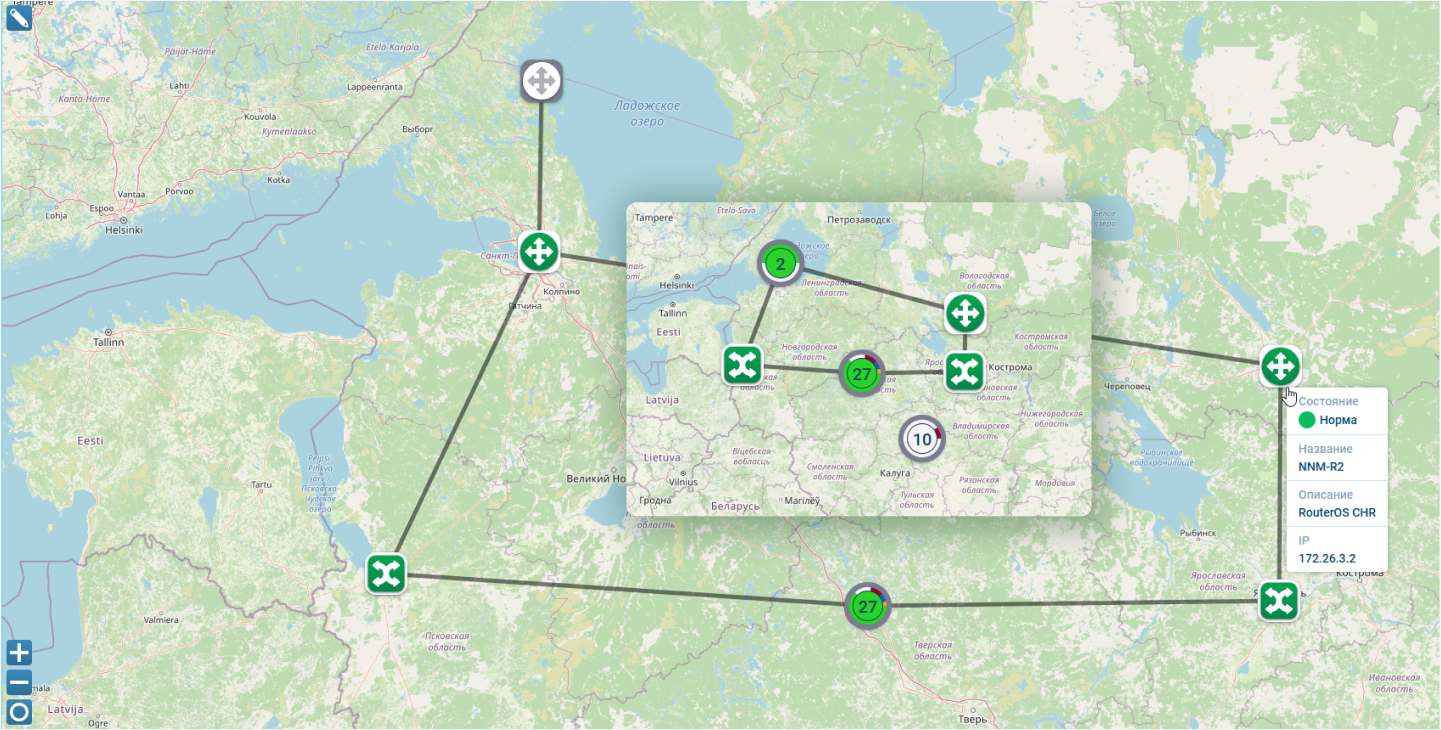
На виджете «ГИС» доступны все основные показатели инфраструктуры на определенной локации
Push-сообщения
В этом случае сообщения приходят в виде всплывающих окон на мониторе оператора и сопровождаются звуковым сигналом. Они уже содержат основные сведения о происшедшей аварии.
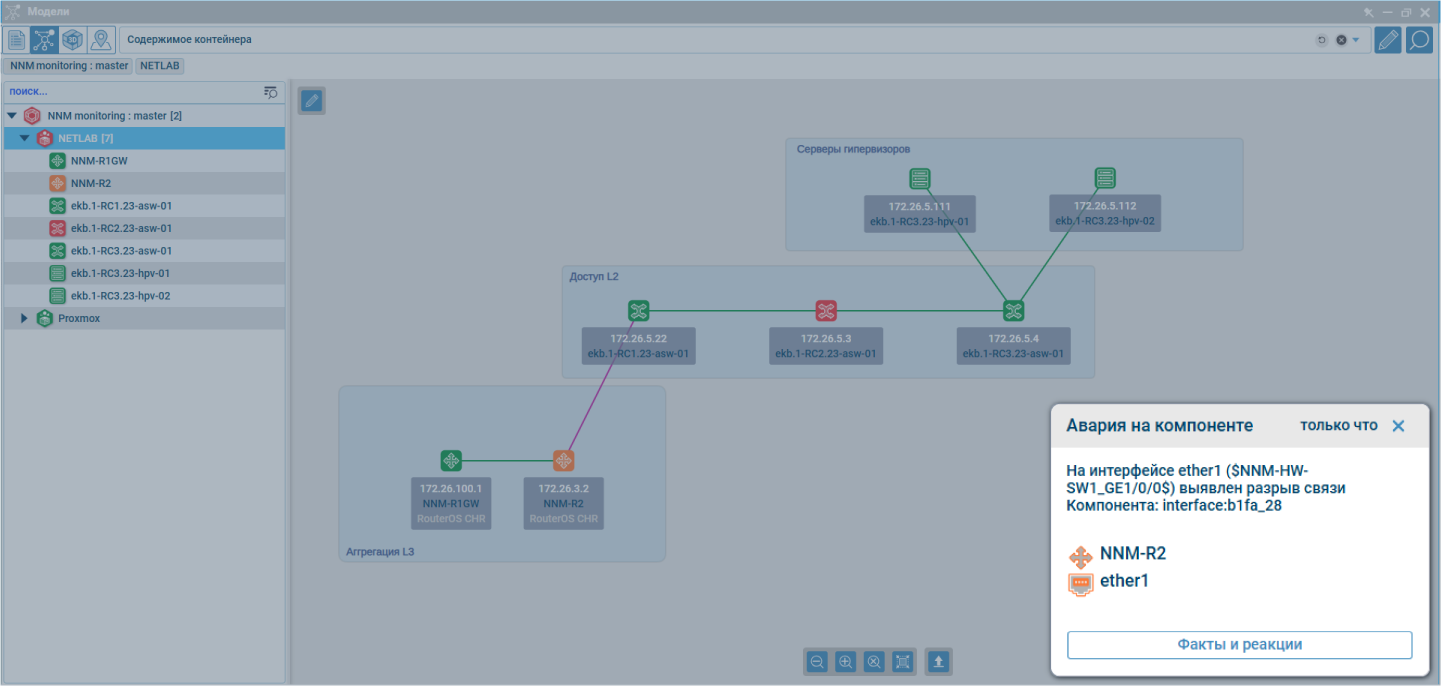
Благодаря push-сообщениям оператор узнает об аварии сразу, как только она случилась
Это не происходит по умолчанию при любой аварии. Всплывающие уведомления можно настроить на те события, о которых важно узнавать сразу, как они происходят, — раньше, чем оператор будет проверять список аварий в системе.
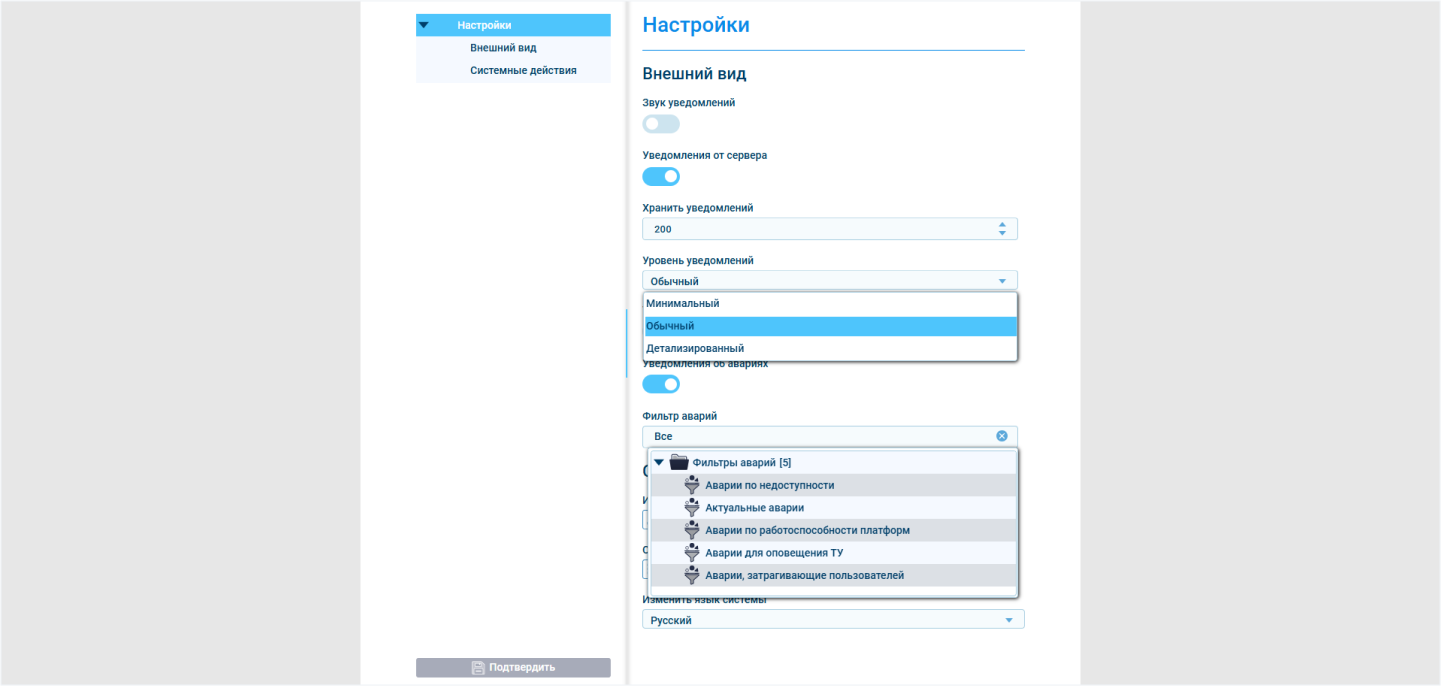
Параметры всплывающих сообщений гибко настраиваются
По e-mail, SMS или в Telegram
Преимущества уведомлений по этим каналам связи в том, что пользователи получат их в любом месте и в любое время. Для этого необязательно быть у компьютера или в системе. Как и в случае со всплывающими сообщениями, их можно настроить на нужные типы аварий, а также задать получателя или группы получателей.
Уведомления содержат стандартный текст. В Naumen Network Manager предлагается шаблонный вариант, в котором содержится основная информация об аварии: объект, время, критичность. Но его можно редактировать под потребности пользователей, а также составить свой текст.
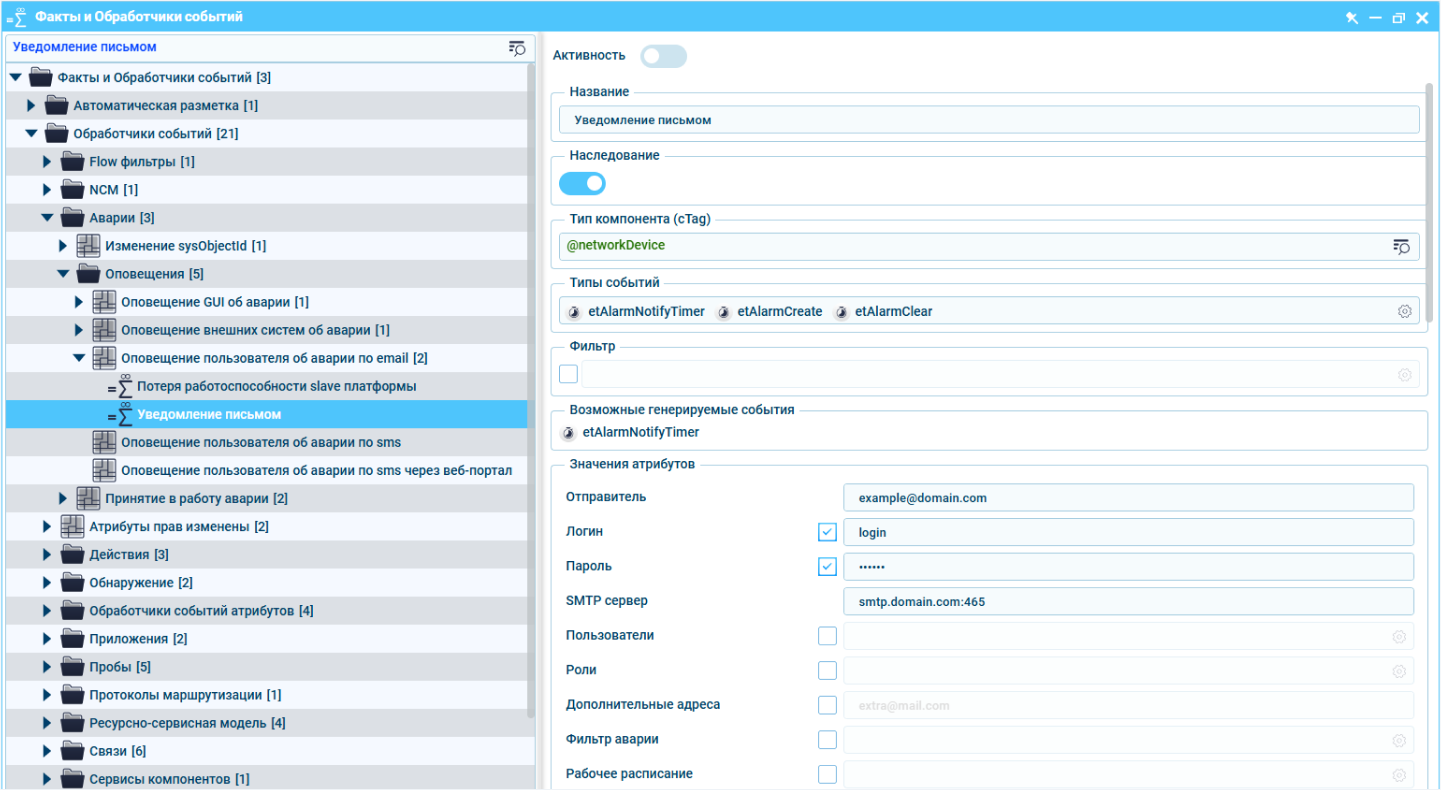
Оповещения по внешним каналам связи позволяют пользователям узнавать об авариях вне системы мониторинга
Через интеграцию
Этот способ работает через интеграции Naumen Network Manager с зонтичным мониторингом Naumen Business Service Monitoring (BSM) и системой автоматизации управления
Зонтичный мониторинг не контактирует напрямую с объектами инфраструктуры, но получает данные от NNM. Также он имеет доступ к
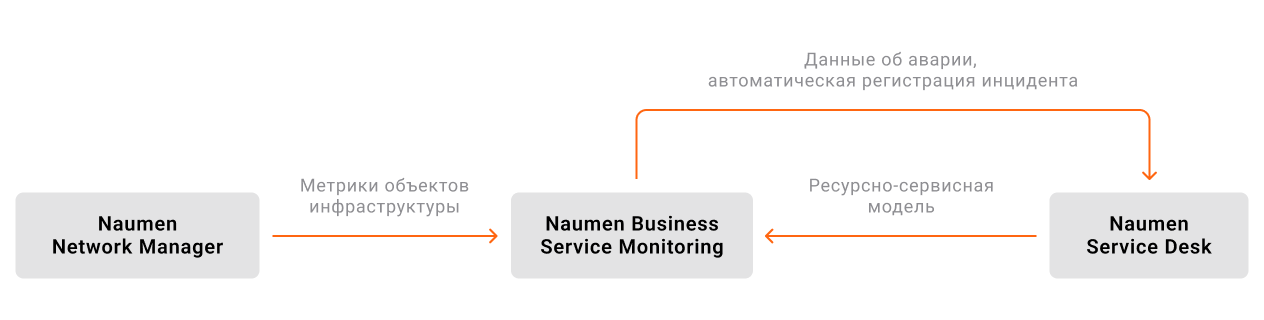
Связка трех решений позволяет полностью автоматизировать цепочку обнаружения и обработки инцидентов
Цепочки уведомлений
Инфраструктурный мониторинг Naumen Network Manager позволяет выстраивать целые цепочки последовательных реакций на аварии.
Например, как только система зафиксировала аварию, уходит сообщение пользователю в Telegram. Если спустя заданный промежуток времени, допустим, через полчаса, авария не принята в работу, о чем сделана отметка в системе, уведомление отправляется повторно — уже в виде SMS. Шагов в цепочке может быть несколько в зависимости от конкретных задач и аварии.
Последовательность также может включать автоматические действия: запуск скрипта или перезагрузку устройства, если есть уверенность в их необходимости и безопасности для работоспособности инфраструктуры.
Графический редактор сценариев помогает в интерактивном режиме создавать логические структуры правил для автоматического оповещения пользователей по результатам выполнения системных действий, включая детектирование любых комбинаций событий на объектах мониторинга.
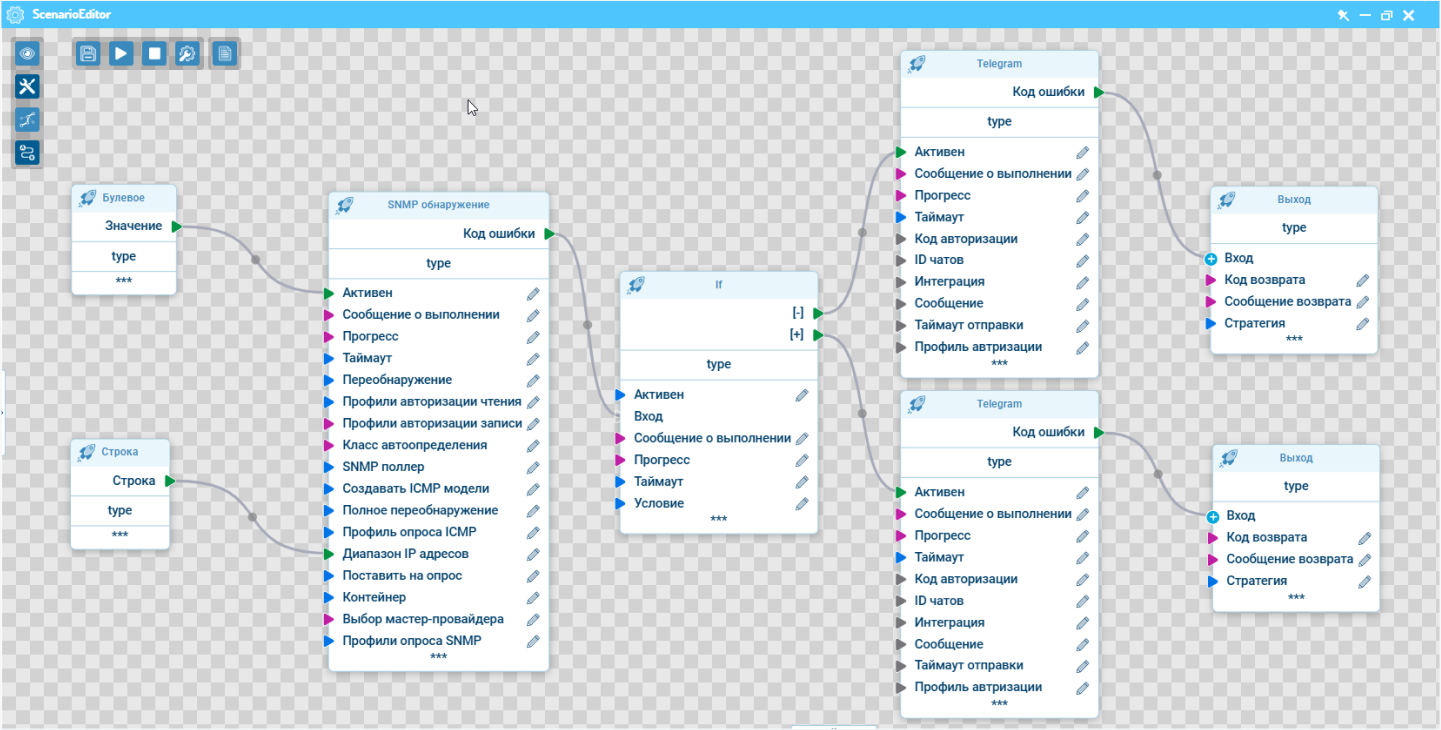
Построение цепочки правил в графическом редакторе
К выводам
Naumen Network Manager располагает гибкой системой уведомлений об авариях. Решение позволяет настраивать как признаки аварий, так и способы оповещения о них. В комплексе эти меры помогают своевременно замечать отклонения в работе объектов, оперативно устранять сбои и тем самым поддерживать стабильность и надежность инфраструктуры.








