

Чем раньше обнаружить вероятность возникновения сбоя в
Прогнозирование метрик: как ML рассчитывает будущее
Один из аналитических инструментов на базе ИИ, который используется в системе Naumen BSM, — это модель прогнозирования. Она анализирует значения метрик оборудования и определяет, как они будут меняться. Если сценарий неблагоприятный, то заранее предупреждает о возможной аварии. Рассмотрим, как обучить ИИ на данных конкретной метрики и учитывать прогнозы на уровне оборудования и сервисов.
Здоровье конфигурационной единицы (КЕ) зависит от одной или нескольких ключевых метрик. Разные показатели постоянно поступают в систему зонтичного мониторинга. Однако, чтобы заметить критичное изменение, нужно неотрывно следить за графиком либо настроить триггер, указав пороговое значение. Тогда важное изменение метрики получится заметить по возникшему событию (алерту).
Чтобы заранее узнавать о вероятных сбоях, нужно подключить
Как подключить к метрике модель прогнозирования:
- Добавить модель к выбранной метрике.
- Задать горизонт прогнозирования.
- Обучить модель на исторических данных.
Горизонт прогнозирования — это период, например, ближайшие несколько часов или дней, на который рассчитывается прогноз. Желаемый горизонт определяет пользователь.
Остальные параметры и коэффициенты, необходимые для выстраивания прогноза, ИИ рассчитывает автоматически: частоту дискретизации, объем истории, сезонность и другие. При этом учитываются свойства метрики и доступный объем истории. Обучение занимает несколько минут. Затем модель станет активна и будет периодически строить прогноз на нужный период.
Качество прогноза зависит от горизонта прогнозирования и объема исторических данных. Если в системе хранятся данные о поведении метрики лишь за сутки, то модель рассчитает прогноз на неделю с невысокой точностью. А когда данных уже накопилось за неделю или месяц, то прогноз за несколько часов вперед скорее окажется точнее.
Рассмотрим на примере. На здоровье сервера влияет метрика «Память на диске».
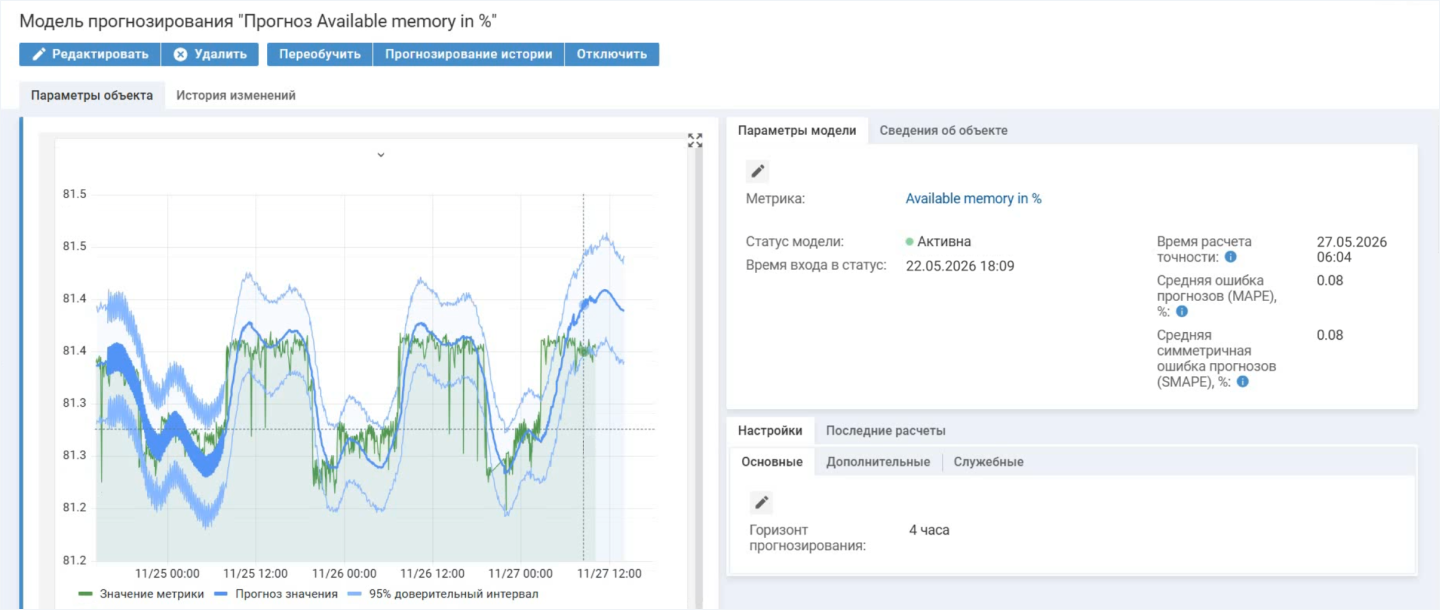
ИИ создает график, на котором отображаются прогнозные значения метрики в рамках заданного горизонта
Модель прогнозирования дает возможность предотвращать инциденты. В результате сокращается время простоев сервисов и снижаются издержки на восстановление систем.
Детектирование аномалий в ИТ-инфраструктуре
Детектирование аномалий — это инструмент интеллектуальной аналитики в Naumen BSM для обнаружения отклонений в значениях метрик. Он используется для выявления возможных аварий на ранних стадиях, особенно если для данной метрики не настроен триггер с пороговым значением.
Также аналитику по аномалиям можно использовать при настройке триггеров, как на уровне зонтичного, так и в системах корневого мониторинга. Статистика аномалий поможет при определении актуальных порогов, которые могут меняться в разные периоды.
ML-модель обнаружения аномалий не требует устанавливать границы типичных значений. Она обучается на исторических данных и затем автоматически определяет, какие значения считать аномальными для метрики, учитывая заданный период обучения. Качество анализа зависит от свойств метрики и доступных данных.
В Naumen BSM предусмотрены несколько моделей детектирования аномалий, в основе которых лежат разные математические алгоритмы, наиболее подходящие для анализа метрик инфраструктуры. При одинаковых входных данных лучший результат может показать любая из них. И только на практике определяется, какой алгоритм будет эффективнее работать с конкретной метрикой. Для этого необходимо обучить модели и сравнить результаты.
Как подключить модель детектирования аномалий к метрике:
- Добавить одну из моделей к нужной метрике.
- Задать частоту расчета.
- Обучить модель на исторических данных.
- Повторить процедуру с одной и несколькими другими моделями.
- Сравнить результаты разных моделей и выбрать оптимальный вариант.
Модели обучаются на исторических данных, которые хранятся в системе. При этом для настройки не требуется множество сложных параметров. Пользователю достаточно указать частоту расчета — интервал, в рамках которого алгоритм будет анализировать поступившие данные по конкретной метрике. Например, раз в минуту.
Итог обучения — график с историческими данными, на котором красным выделены точки с нетипичными значениями. Пунктирная линия показывает момент обучения модели.
Например,
В дальнейшем алгоритм будет анализировать значения метрики с периодичностью, заданной пользователем. Можно настроить, чтобы система автоматически отслеживала частоту отклонений, тогда при ее повышении (если за короткое время возникает много аномалий)
Результаты анализа отклонений от модели Moving Z-Score и Isolation Forest
ИИ помогает организовать контроль за частотой возникновения аномалий в метриках. Это позволяет заблаговременно узнавать о риске возникновения сбоя и вовремя реагировать на подобные ситуации. Также
Как результаты ML-моделей превращаются в статусы, события и инциденты
Результаты работы
Разберем, как
1. От ML-анализа к событию
На первом этапе результат работы
Пример.
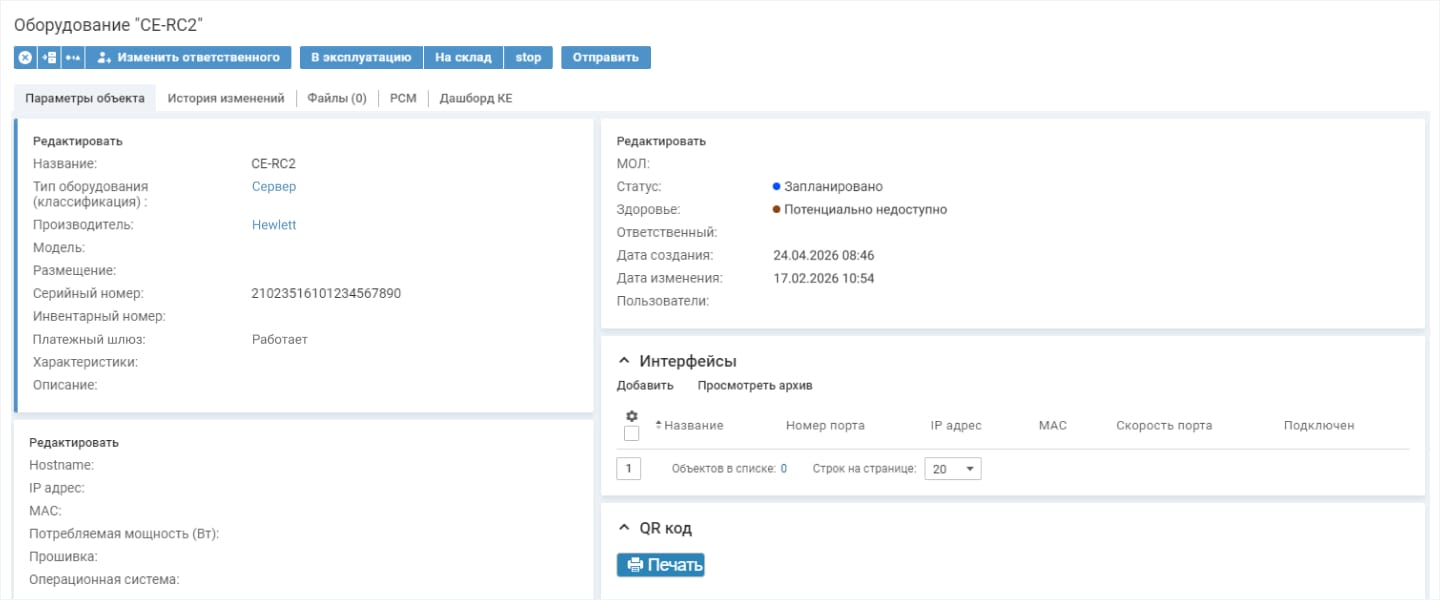
Сначала ИИ замечает событие и отмечает в журнале. На этом этапе инцидент не создается
2. От события к статусу здоровья оборудования
Оценка здоровья конфигурационной единицы (КЕ) — сервера, коммутатора, базы данных — формируется на основе совокупности событий, связанных с данной КЕ. В расчет принимаются как уже произошедшие сбои или отклонения, так и прогнозы
Правила влияния прогнозов на статус здоровья настраиваемы. Например, может быть задано правило: при получении от
Пример.
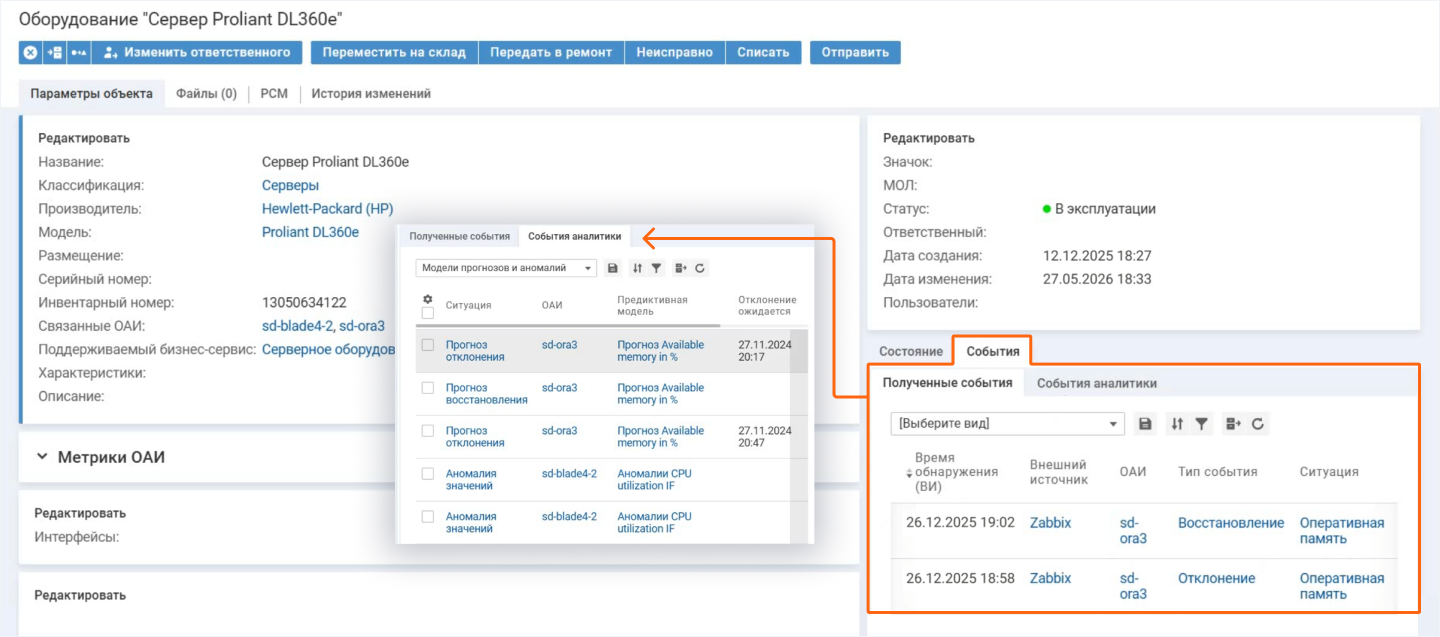
При оценке состояния устройств учитываются события, сформированные на основе прогнозных данных от ML-моделей
3. От критичности к событию или инциденту
Не каждый предиктивный сигнал требует оперативного вмешательства. Для предотвращения нецелевого использования ресурсов
Разберем, как эта логика реализуется Naumen BSM.
Настройка условий срабатывания триггера. В отличие от обычных пороговых значений, в Naumen BSM можно задать сложное условие реакции на событие, объединяющее несколько метрик. Например, создавать инцидент только в том случае, если для этого сработали 2 фактора. Это позволяет отсеивать ложные срабатывания, вызванные единичными отклонениями.
Приоритизация по критичности инцидента. Результаты анализа
Пример.
Но если модель наблюдает устойчивый тренд роста температуры, а прогноз показывает превышение критического порога через 30 минут, это уже квалифицируется как инцидент с приоритетом «Высокий». Система уведомляет дежурного инженера для принятия мер.
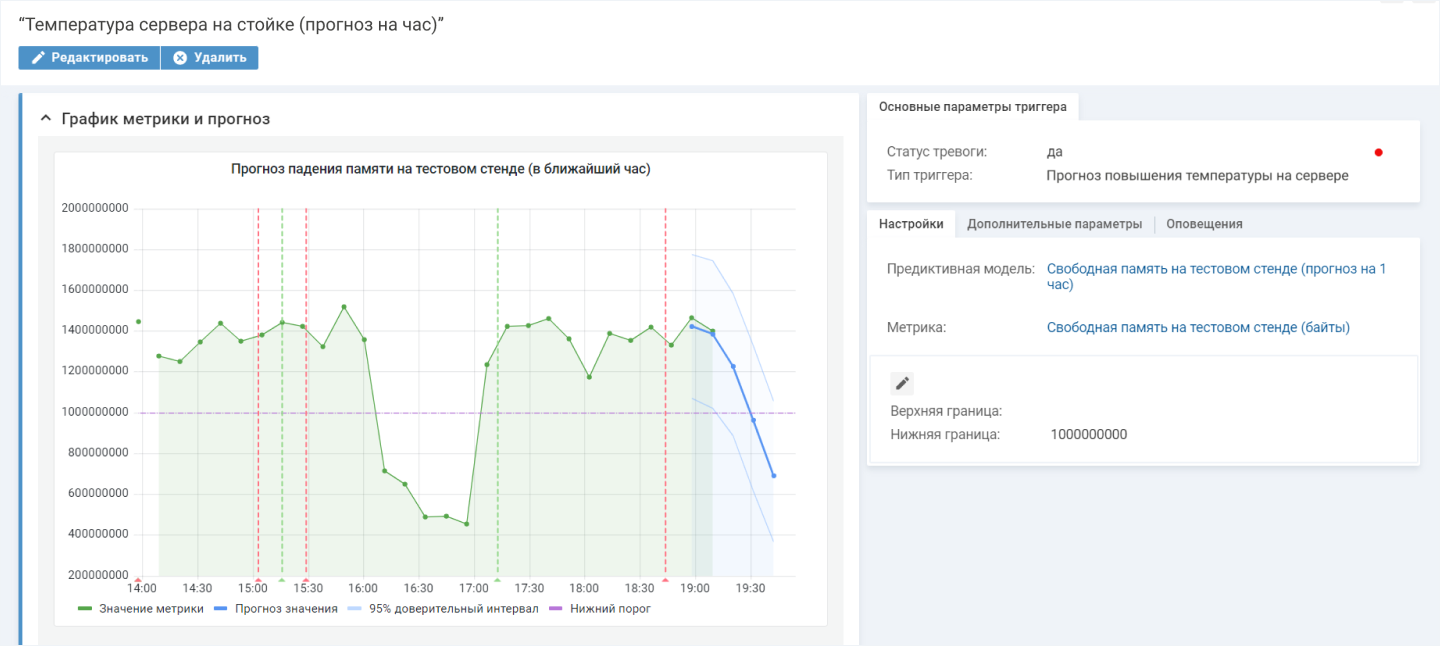
Триггер настраивается прямо на метрике и срабатывает при выполнении всех условий
4. Бизнес-контекст инцидента: от оборудования к сервису через РСМ
Ключевой принцип целостного подхода — переход от технического восприятия («отказал сервер») к
Инструментом для этого служит
Благодаря РСМ система мониторинга на основе прогноза сбоя конкретной КЕ автоматически определяет, какие
Пример. РСМ показывает, что в стойке, где произойдет перегрев, находятся серверы платежного шлюза. Система добавляет в инцидент необходимый контекст: «Под угрозой платежный шлюз».
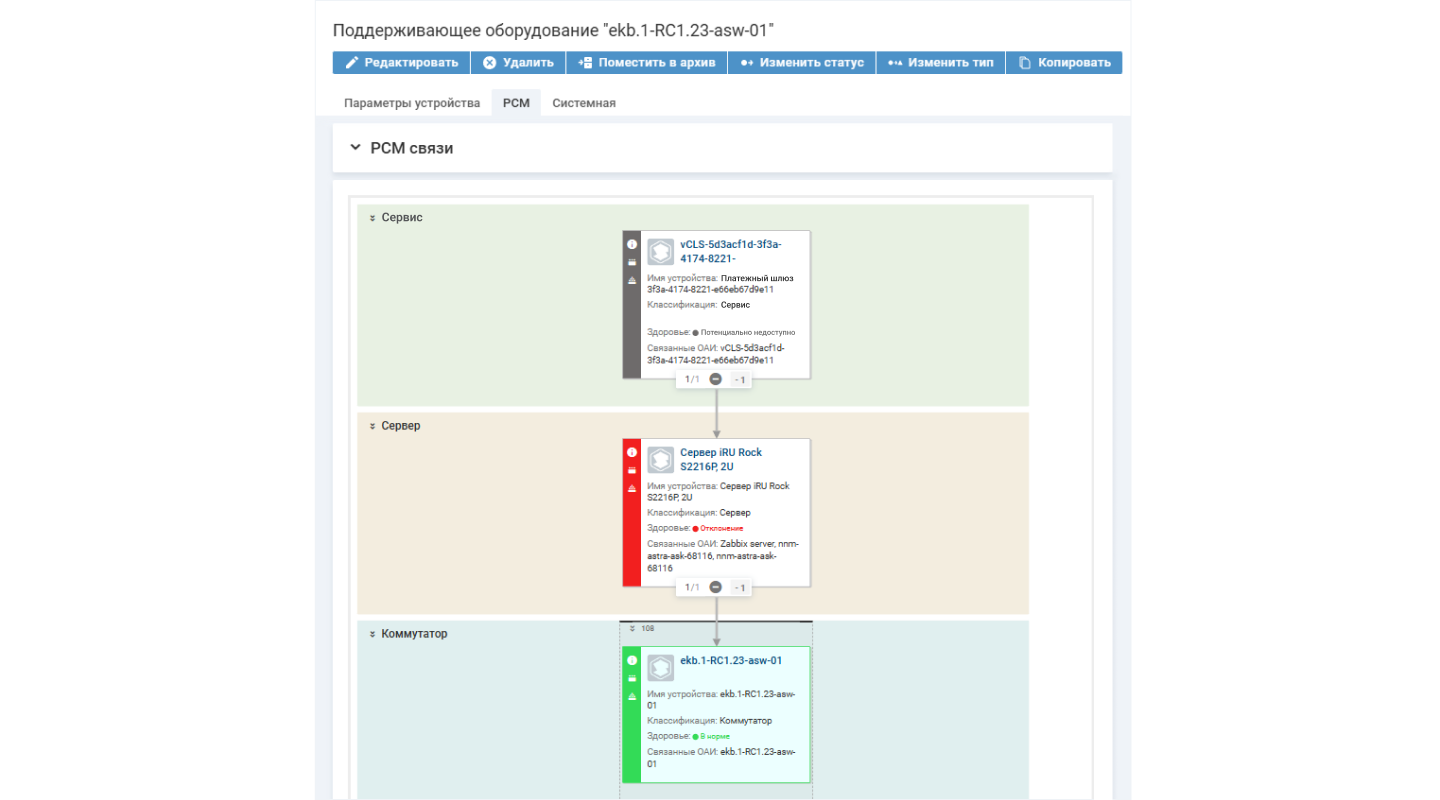
Потенциальное отклонение повлияет на критически важный сервис, поэтому система зонтичного мониторинга определяет событие как инцидент
Интеграция с Naumen Service Desk
Финальный этап работы
- Для событий с низкой критичностью регистрируется запрос на обслуживание.
- Для событий с высокой критичностью регистрируется инцидент с автоматической привязкой к услуге и изменением статуса здоровья услуги.
- Определяются каналы и получатели уведомлений о вероятном сбое для принятия упреждающих мер.
В результате
Живой пример: как ML-модели работают на реальных данных
Чтобы исправить ситуацию, в Naumen BSM организовали сбор метрик состояния дисков: количество переназначенных секторов, частоту ошибок, температуру. К этим показателям подключили
В результате внедрения ИИ за следующий месяц получили измеримый результат.
| Показатель | Результат | Предотвращенные инциденты | 2 (диски заменены планово, без остановки сервиса) | Снижение аварийных работ по восстановлению серверов | 80% | Сокращение времени от обнаружения до замены | В 3 раза, исключен этап диагностики |
Бизнес перешел к предиктивному управлению одного сегмента
К выводам
Прогнозы могут влиять на статус здоровья конфигурационной единицы (компонента инфраструктуры) и связанных сервисов, а также на создание запросов и инцидентов в системе класса Service Desk. Таким образом, благодаря предиктивной аналитике







