
Перегрузки или отключения оборудования напрямую влияют на работу связанных
Какие уровни зонтичного мониторинга бывают
Naumen Business Service Monitoring подключается к внешним источникам, например, системам корневого мониторинга, и агрегирует различные данные. Процессы сбора и обработки данных каждого типа выделяются в отдельные уровни мониторинга:
- автоинвентаризация;
- управление событиями;
- мониторинг метрик.
Каждый уровень отвечает за свою задачу, а вместе они помогают получить комплексный срез состояния инфраструктуры. В результате
| Уровень мониторинга | Тип данных | Ценность |
| Дискаверинг | Объекты — оборудование и виртуальные среды | Сбор инвентаризационных данных Быстрое наполнение CMDB Полная и достоверная информация об объектах учета |
| Управление событиями | События, происходящие с объектами | Автоматическая регистрация инцидентов Предотвращение «шторма тревог» — регистрации инцидентов об одной и той же поломке Расчет здоровья объектов инфраструктуры, систем, услуг |
| Мониторинг метрик | Метрики состояния объектов | Автоматическое вычисление сложных показателей Различные сценарии реагирования на нетиповые значения Визуализация данных в удобном для анализа виде Прогнозирование значений и выявление аномалий с помощью |
Рассмотрим, какие задачи выполняются в рамках второго уровня.
Зачем управлять событиями в мониторинге
Системы инфраструктурного мониторинга собирают информацию о работоспособности
Например, администратор Zabbix изучает сообщения только от этого ПО. Администратор Naumen Network Manager — от соответствующей системы. В работающей инфраструктуре зачастую генерируется множество сообщений, поэтому проводить анализ вручную сложно. Кроме того, на основе разрозненных данных практически невозможно составить комплексное представление о происходящем.
Зонтичный мониторинг позволяет автоматизировать этот процесс: обработать сообщения, оценить здоровье оборудования и сервисов, а при необходимости — создать инцидент.
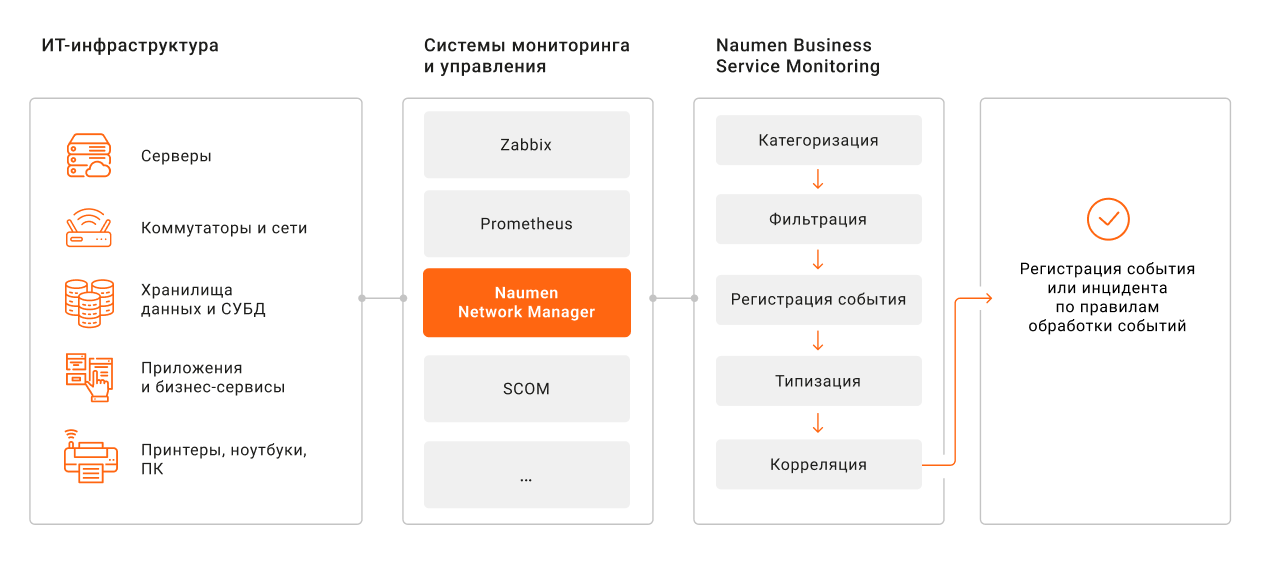
Процесс обмена данными о событиях в зонтичном мониторинге
Как обрабатываются события
В Naumen BSM используются правила типизации. Они помогают получить ответ на вопрос: что значит для инфраструктуры конкретное событие и как его оценивать?
Внешние источники передают в систему сообщения с десятками разных статусов. По каждому сообщению регистрируется событие. Правила типизации позволяют определить тип каждого. В стандартной версии Naumen BSM это «Отклонение», «Восстановление», «Информация» и «Предупреждение».
На этапе работы с правилом типизации также может быть определена ситуация, исходя из той информации, которая пришла из внешнего источника.
Как события влияют на оценку здоровья оборудования и услуг
Данные, выявленные при типизации, используются для расчета здоровья оборудования и услуг. При этом определяется не только состояние устройства, по которому зафиксировано событие, но и оценивается влияние на связанные объекты и сервисы.
Например, по серверу создано событие типа «Предупреждение». Это значит, что устройство, вероятнее всего, скоро отключится. В системе автоматически устанавливается состояние здоровья «Предупреждение». На сервере развернута виртуальная машина, по которой никаких критичных сообщений не поступало. Но при определении здоровья учитываются взаимосвязи, поэтому состояние виртуальной машины определяется как «Потенциально недоступное». Такой же статус получит информационная система, которая развернута на виртуальной машине.
Информацию об уровне здоровья и взаимосвязях одного оборудования с другим удобно отслеживать с помощью
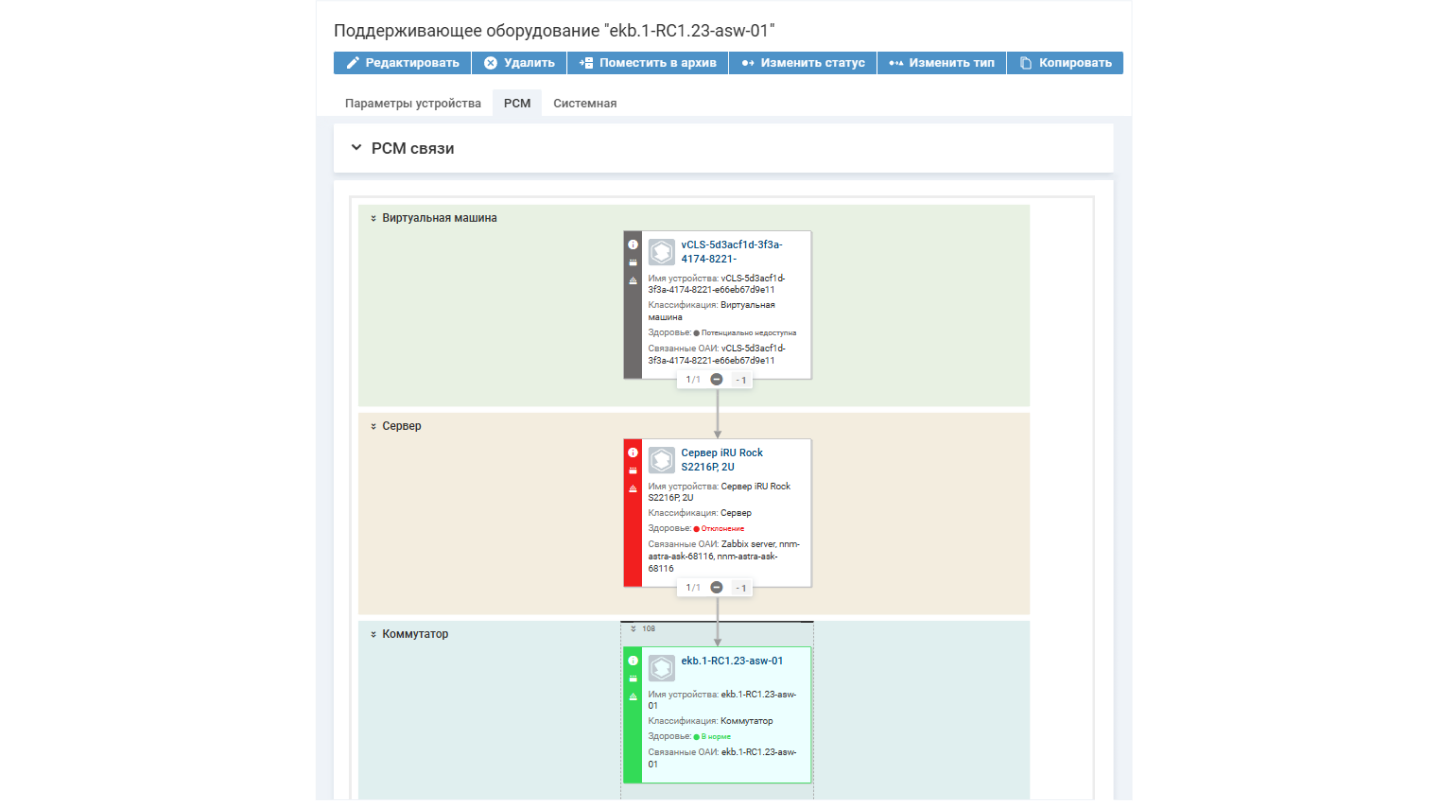
Ресурсно-сервисная модель в Naumen BSM отображает взаимосвязи между разными устройствами и сервисами
Для оперативного контроля сервисов удобно использовать дашборд «Здоровье информационных систем». Он помогает быстро понять, доступен определенный сервис или нет. Состав информационной панели настраивается пользователем: именно он определяет, что нужно отображать на экране. С дашборда можно перейти на
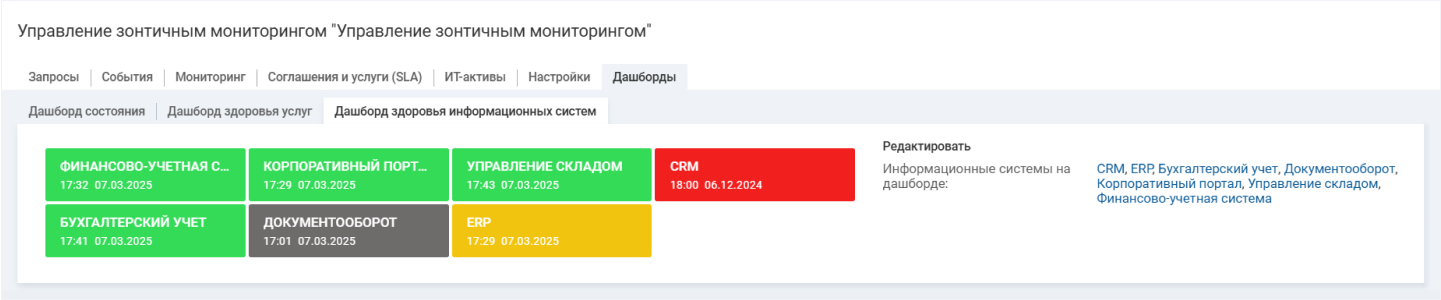
Специальный дашборд в Naumen BSM помогает контролировать здоровье разных сервисов
Как создаются инциденты
После типизации события оцениваются с помощью правил корреляции. С их помощью уточняется ответ на вопрос: нужно ли регистрировать инцидент? При этом учитывается тип, ситуация, связанная услуга. Например, может быть автоматически создан инцидент по событию с типом «Отклонение», если оно затрагивает критически важную
Также правила корреляции дают возможность предотвращать «шторм тревог» — создание множества инцидентов по одной и той же аварии. Допустим, две системы инфраструктурного мониторинга зафиксировали сбой на сервере и отправили сообщения в зонтичный мониторинг. В Naumen BSM регистрируются два события с типом «Отклонение» по одной и той же конфигурационной единице. И по каждому из них нужно регистрировать инцидент.
Правила корреляции позволяют избежать регистрации нескольких одинаковых инцидентов. Инцидент регистрируется только по первому событию за период, а информация о последующих добавляется в комментарий к инциденту.
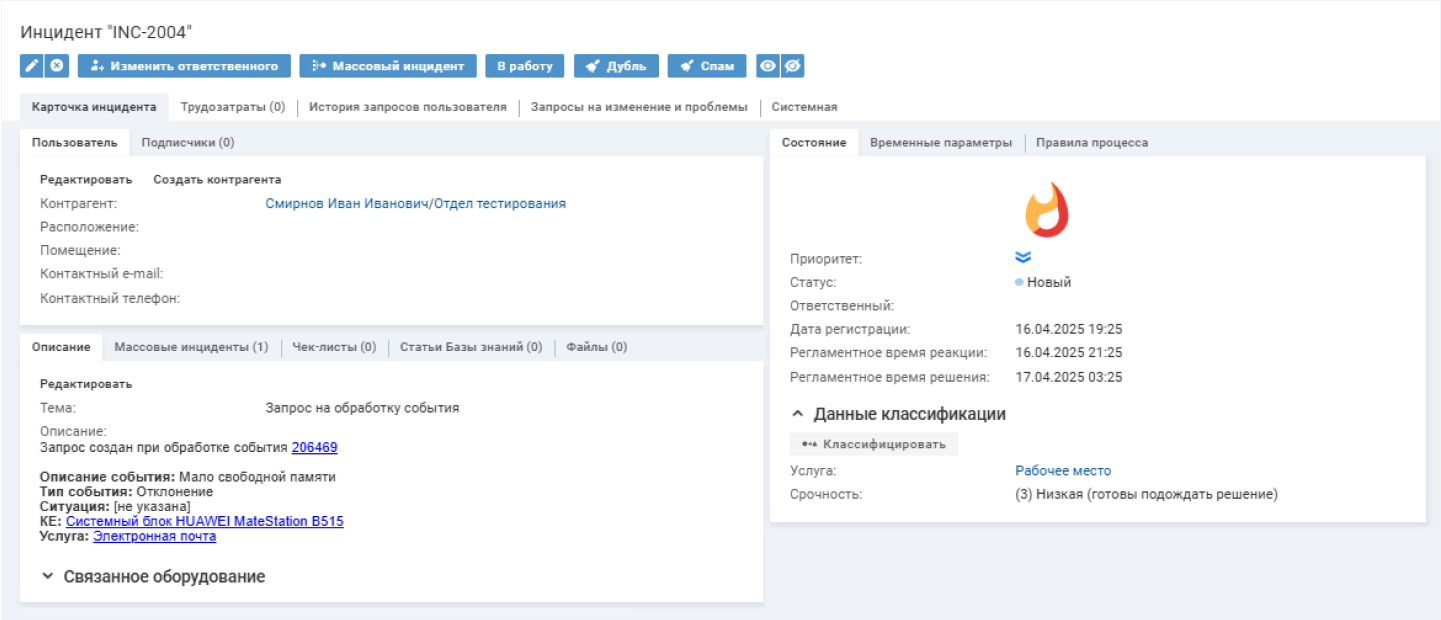
В Naumen BSM инцидент регистрируется по первому аварийному событию за определенный период
К выводам
Управление событиями в зонтичном мониторинге позволяет автоматически рассчитывать текущее состояние здоровья оборудования и услуг, а также регистрировать инциденты. За счет этого проще отслеживать аварийные ситуации в









