В инфраструктуре компании почти всегда работает несколько систем мониторинга. Каждая отвечает за свой участок. К примеру, первая собирает метрики по серверной инфраструктуре, вторая — по сетевому оборудованию, третья — по другим сегментам.
Задача Naumen Business Service Monitoring (BSM) — объединить эти данные. В этом обзоре разберем 15 возможностей продукта, которые помогают получить полную картину инфраструктуры, прогнозировать сбои и эффективно управлять бизнес-сервисами.
Содержание
Интеграции и сбор данных
Интеграция с внешним ПО
Сбор метрик и событий из разных источников
Приоритизация источников
Обработка событий
Фильтрация и обогащение данных
Корреляция событий
Обработка событий кластера
Управление инцидентами мониторинга
Регистрация инцидентов мониторинга
Расчет здоровья сервисов
Дополнительные инструменты
Анализ причин недоступности
Визуализация и аналитика
Дашборды «из коробки»
Настройка персональных панелей
Анализ метрик
Предиктивная аналитика и ML
Прогнозирование метрик
Обработка событий прогнозов
Интеграции и сбор данных
Чтобы система зонтичного мониторинга работала корректно, ей нужны полные и непротиворечивые данные из разных источников. Рассмотрим, как Naumen BSM собирает метрики и события в единую модель и управляет их качеством.
Интеграция с внешним ПО
В Naumen BSM предусмотрен широкий набор инструментов интеграции — от готовых коннекторов до гибких способов подключения к системам любых типов.
В коробочной поставке доступны готовые коннекторы к популярным платформам мониторинга и управления инфраструктурой: Zabbix, Prometheus, vCenter, Naumen Network Manager и другим. Они автоматически разворачивают необходимые объекты, получают сырые данные и сразу начинают с ними работать — без долгой ручной настройки или сложных интеграционных работ. Список коннекторов постоянно расширяется.
Помимо готовых решений, Naumen BSM предлагает разные способы подключения к внешним источникам. На практике чаще всего используют:
API-интеграции — подходят для современных систем и дают быстрый доступ к данным.- Подключение напрямую к базе данных — гибкий способ, если клиент может предоставить к ней доступ.
- Получение данных через файлы — когда прямое подключение невозможно, но внешняя система умеет формировать выгрузки.
- Получение данных через почтовый сервис — удобный вариант, если в подключаемой системе реализован такой механизм.
Благодаря такому набору инструментов Naumen BSM вписывается в любой
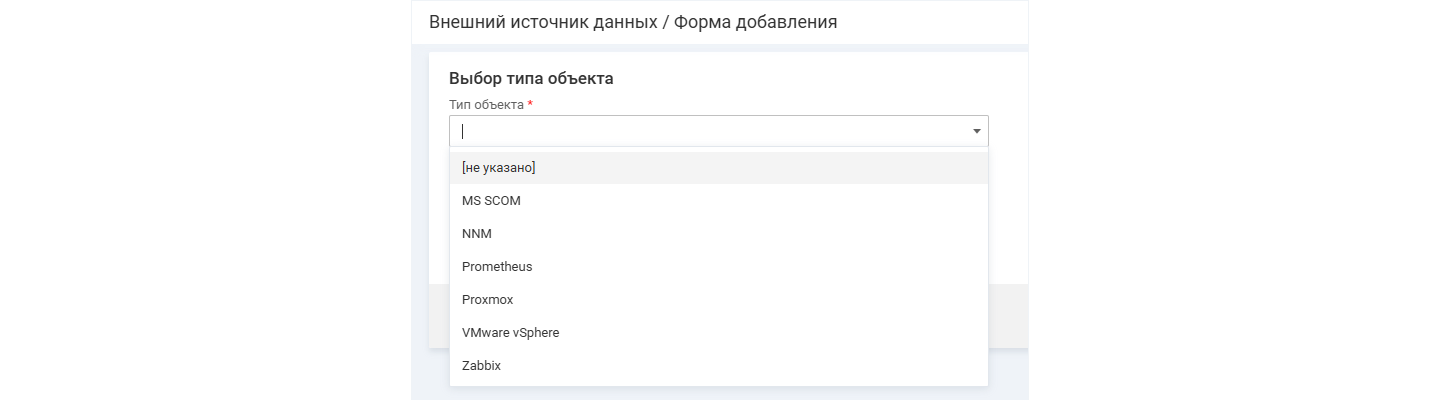
Naumen BSM предлагает готовые коннекторы и множество способов подключения новых систем
Сбор метрик и событий из разных источников
Чтобы объединить данные, Naumen BSM связывает информацию из внешних систем мониторинга с одной конфигурационной единицей (КЕ)
- получить полное представление о состоянии КЕ на всех уровнях;
- аккумулировать все метрики и события, относящиеся к одной сущности;
- исключить ситуацию, когда один и тот же объект учитывается в мониторинге несколько раз.
В дальнейшем эта информация используется для расчетов состояния сервисов, визуализации, аналитики и автоматизации реакции.
Приоритизация источников
Когда Naumen BSM получает информацию об одном и том же объекте из разных внешних систем, важно избежать конфликтов и дублирования данных. Это возможно благодаря функции приоритизации атрибутов.
Это работает так. Для каждого подключенного источника и каждого атрибута задается свой приоритет. Система сравнивает эти параметры и выбирает информацию от самого значимого из них.
Приоритизация источников дает возможность управлять точностью сведений, определять, какие данные попадут в CMDB. Например, серийный номер или модель оборудования можно получать из системы дискаверинга, названия — из
Если приоритеты необходимо пересобрать, Naumen BSM автоматически поменяет правила заполнения. Атрибуты с более высоким весом система возьмет из нужного источника, даже если остальные данные приходят из другого.
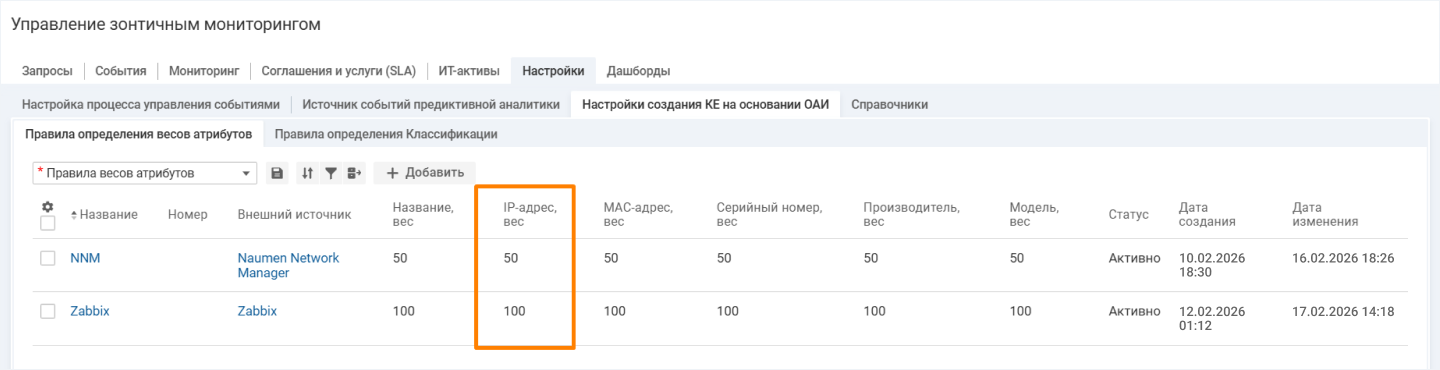
Приоритизация атрибутов задается в настройках создания КЕ по данным из подключенных систем
Обработка событий
Когда статус события определен, начинается этап обработки. Рассмотрим, как он проходит.
Фильтрация и обогащение данных
Чтобы вычленить из многочисленных данных и событий полезные, система применяет к ним фильтрацию и обогащение.
Фильтрация позволяет не рассматривать лишние и нерелевантные объекты, например, второстепенные характеристики, информационные сообщения или устройства без изменений. Такая функция снижает нагрузку на
Обогащение приводит оставшиеся данные в осмысленный вид. Метрики и события привязываются к конфигурационным единицам, сопоставляются с
Комбинация фильтрации и обогащения обеспечивает Naumen BSM прозрачность и точность мониторинга, позволяя принимать решения на основе данных.
Корреляция событий
Когда возникает сбой, системы корневого мониторинга могут продолжать присылать аварийные события до тех пор, пока инцидент не решится. Если авария затронула связанные элементы, количество таких уведомлений возрастает в разы.
Чтобы этого не происходило, в Naumen BSM есть правила корреляции. Они анализируют ситуацию, тип события, услугу и решают, нужно ли создавать инцидент или достаточно зафиксировать состояние. Система создает только первый инцидент, а последующие связанные события группирует вокруг него. Интервал связывания настраивается. Например, от 15 минут до нескольких часов или суток.
Если в течение этого интервала оборудование не восстановилось, система зарегистрирует новый инцидент по новому событию и сгруппирует с ним последующие. При закрытии инцидента автоматически закроются и все связанные события.
Также правила корреляции учитывают важность услуги: по критичным сервисам система поднимет инцидент сразу. Кроме того, они позволяют автоматически назначать сроки устранения инцидентов с учетом SLA.
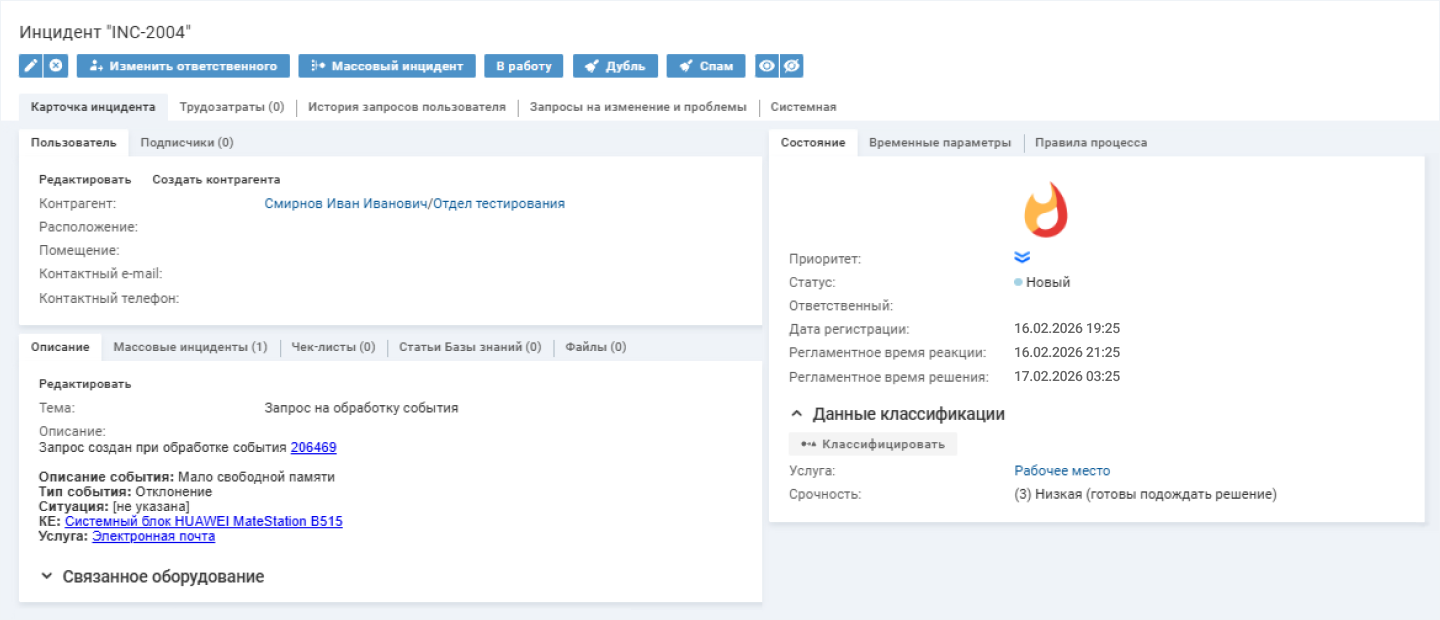
Система регистрирует как инцидент только первое аварийное событие за период, остальные группирует на отдельной вкладке
Обработка событий кластера
В
Active—Passive . В работе участвует одна активная нода. Если она выходит из строя, кластер считается неработоспособным.Active—Active . Нагрузка распределена между несколькими нодами. Кластер продолжает работу, пока число отказавших нод не превысит заданный порог. Это определяется атрибутом «Предел отказоустойчивости».
Если одна из нод выходит из строя, система проверяет настройки кластеризации и решает, должен ли измениться статус кластера и, как следствие, состояние услуги.
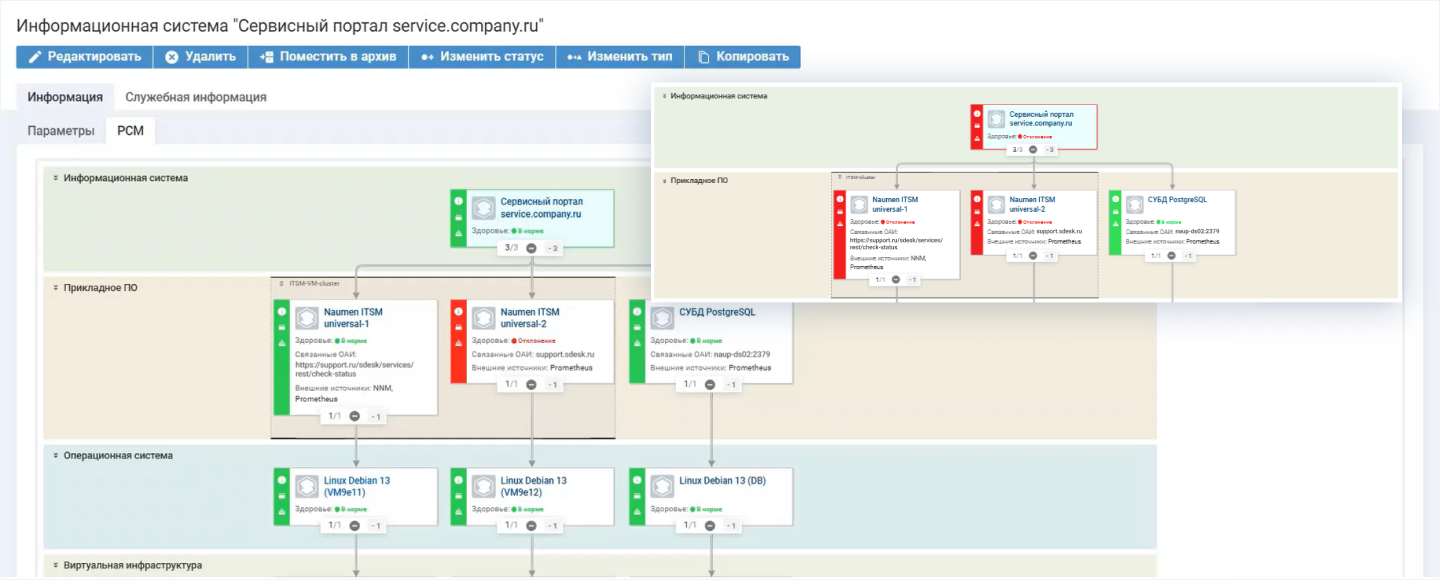
Если из строя выходит одна нода, сервис остается работоспособным, если обе — становится недоступным
Управление инцидентами мониторинга
Когда система обнаруживает значимое (критичное) событие, она реагирует на событие по определенным правилам и автоматически отправляет заявку с необходимым контекстом в соответствующее
Регистрация инцидентов мониторинга
Naumen BSM интегрируется с экосистемой инфраструктурных продуктов Naumen, включая Naumen Service Desk. Возможна интеграция с продуктами этого класса от других вендоров. Описанная ниже работа с заявкой будет аналогичной.
Если событие признается критичным, решение автоматически создает карточку инцидента, где указывает:
- исходное событие и его тип;
- затронутую конфигурационную единицу;
- описание и вложенные параметры.
Система сразу назначает приоритет, ответственного и сроки решения проблемы. Если событие совпадает с плановой профилактической работой (ППР), событие ставится в статус «Отложено» и связывается с нужным запросом, а состояние оборудования остается без изменений.
Благодаря автоматизации команда
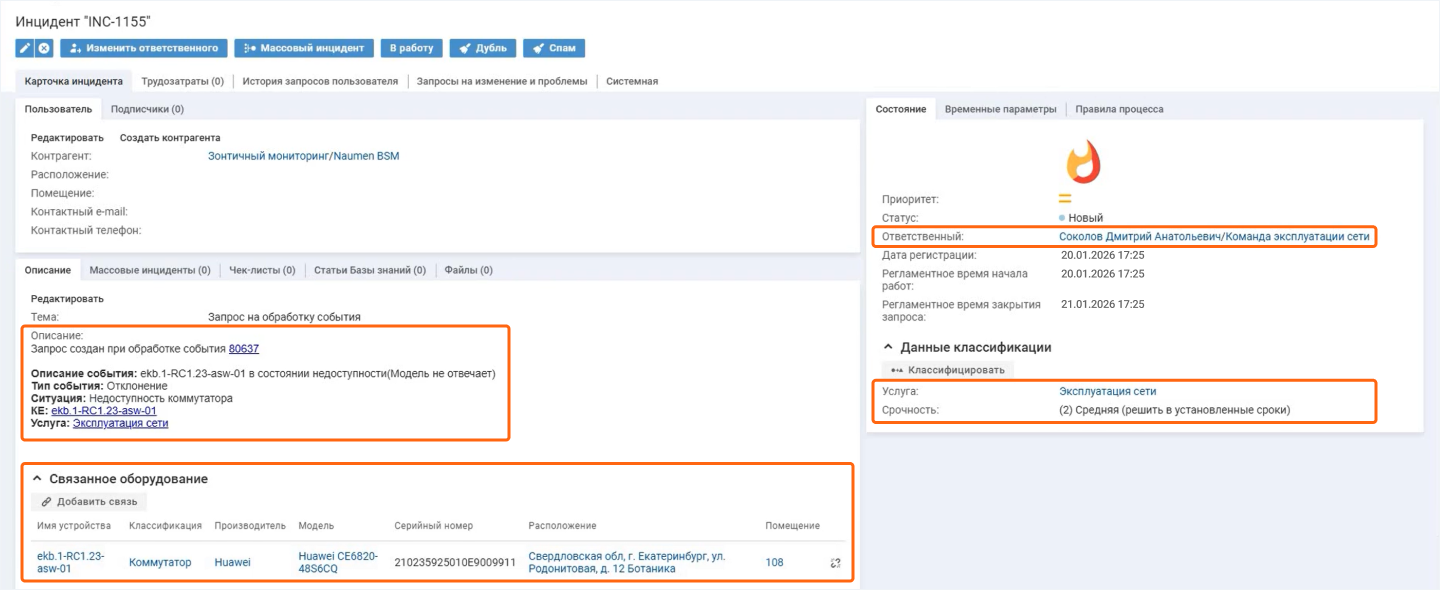
Когда Naumen BSM автоматически создает заявку в Service Desk, то обязательно передает туда данные, полезные для последующих действий со стороны техподдержки
Расчет здоровья сервисов
Зонтичный мониторинг позволяет оценивать состояние бизнес-сервисов и ключевых компонентов
На дашбордах визуально отображается статус критичных систем и сервисов с понятными индикаторами. Зеленый цвет — нормальная работа, желтый и серый — возможная недоступность, красный — критическое состояние. Это помогает команде ИТ быстро увидеть проблемные участки и приоритетно реагировать на сбои.
При этом возможности системы гибко настраиваются под особенности инфраструктуры. Например, можно учитывать не только само оборудование, но и зависимости между сервисами.
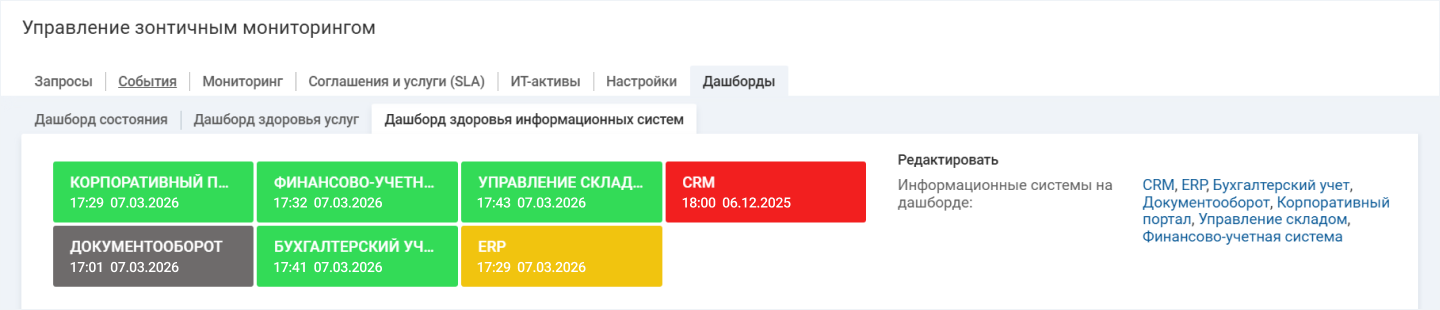
Зеленым цветом обозначены сервисы, которые работают в штатном режиме. Желтым, красным и серым — те, что требуют внимания технических специалистов
Дополнительные инструменты
Чтобы принимать решения и видеть общее состояние
Ресурсно-сервисная модель
Каждая конфигурационная единица и сервис отображаются как узлы на РСМ. Этот инструмент позволяет видеть, какие устройства и приложения поддерживают конкретные
При обработке событий система учитывает связи между сервисами и оборудованием, что помогает понимать, как отказ данного компонента повлияет на разные сервисы. РСМ показывает прямое влияние каждого элемента, а также учитывает кластерные и резервные решения, чтобы корректно оценивать доступность сервисов даже при отказе части инфраструктуры.
Ресурсно-сервисная модель показывает расчет здоровья сервиса, работающего в кластере
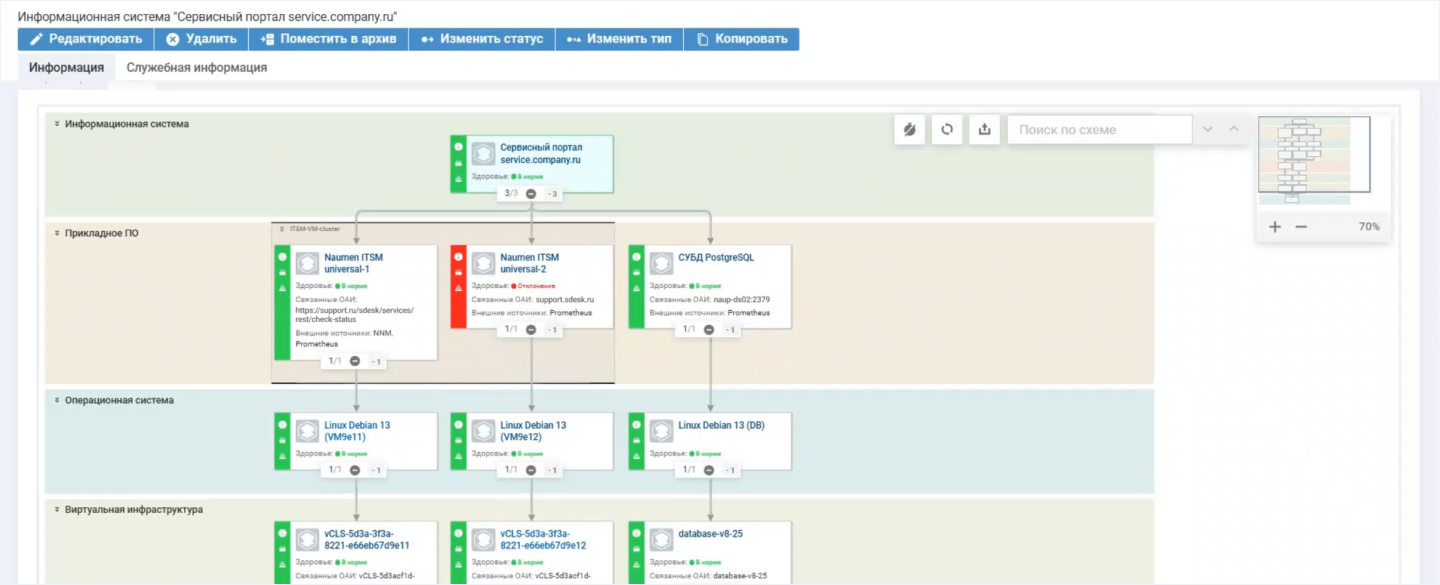
Анализ причин недоступности
Naumen BSM оценивает доступность
Так получается вычислять критические элементы, которые могут стать причиной недоступности, на основе следующих факторов:
- статус компонентов;
- характер и степень влияния на сервисы;
- тип кластера (
Active—Active илиActive—Passive ) и настройки отказоустойчивости.
На
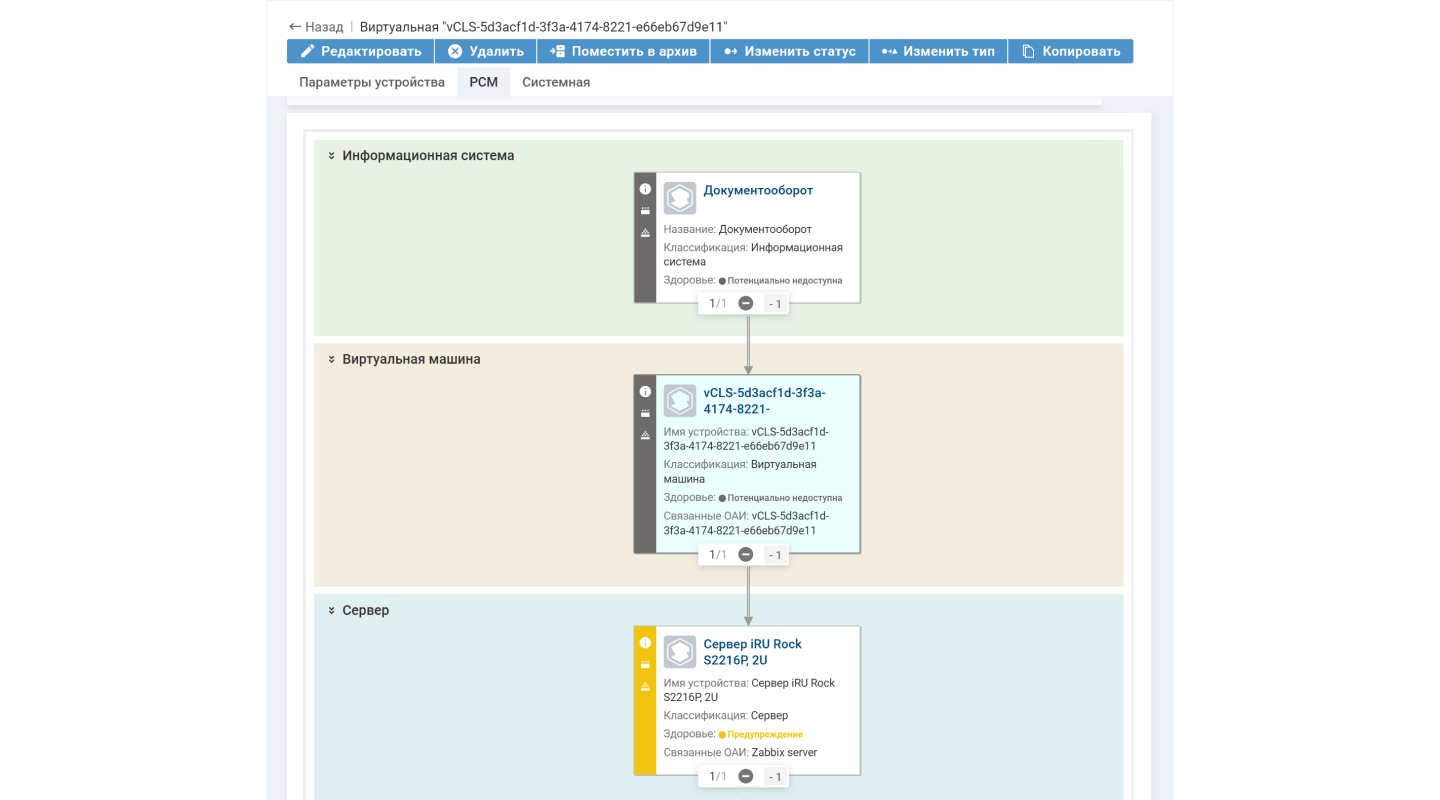
РСМ показывает, что сервер требует внимания. Например, сбой приведет к отключению сервиса «Документооборот»
Визуализация и аналитика
Для структуризации, обработки и представления информации в Naumen BSM представлены визуальные панели. Они легко настраиваются и кастомизируются. Рассмотрим, что и как на них можно вывести.
Дашборды «из коробки»
«Коробочная» версия Naumen BSM содержит готовый набор дашбордов, которые помогают быстро оценить состояние инфраструктуры и сервисов без необходимости вчитываться в карточки отдельных объектов.
Дашборд здоровья инфраструктуры отражает текущее состояние оборудования. Преднастроенные виджеты на дашборде текущего состояния визуализируют:
- аналитику событий по услугам — какие события и по каким сервисам происходили;
- список проблемных услуг — выделяет сервисы с наибольшим количеством негативных событий;
- динамику событий разных типов за выбранные периоды;
- инциденты, созданные на основе прогнозных моделей.
Каждый дашборд можно изменить под задачи компании: скорректировать фильтры, поменять логику отображения или добавить дополнительные показатели.
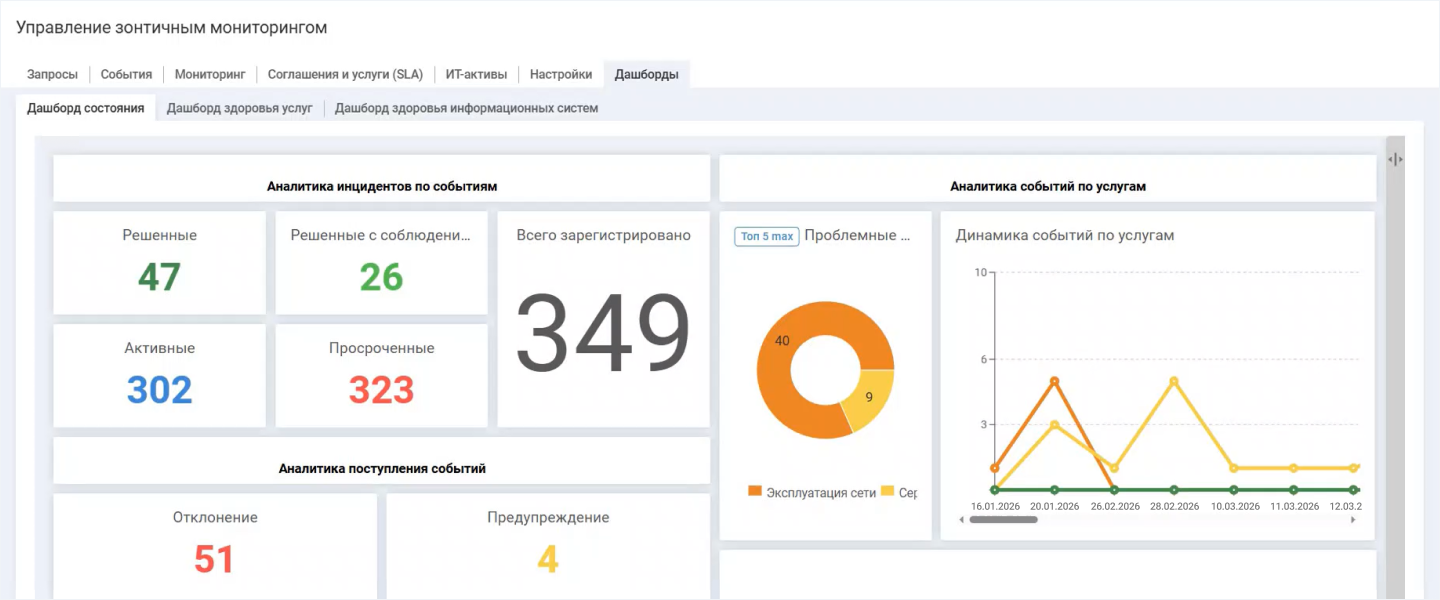
Дашборд показывает базовую аналитику по событиям зонтичного мониторинга. Например, сколько инцидентов мониторинга зарегистрировано за период, по каким услугам чаще регистрируются критичные события по обеспечивающей их инфраструктуре
Настройка персональных панелей
Собирать индивидуальные дашборды можно прямо в интерфейсе Naumen BSM, без разработки и привлечения инженеров. Для этого достаточно выбрать тип визуализации, задать объект отображения, настроить фильтры и группировки. Затем подобрать формат представления данных. Процесс занимает считанные минуты.
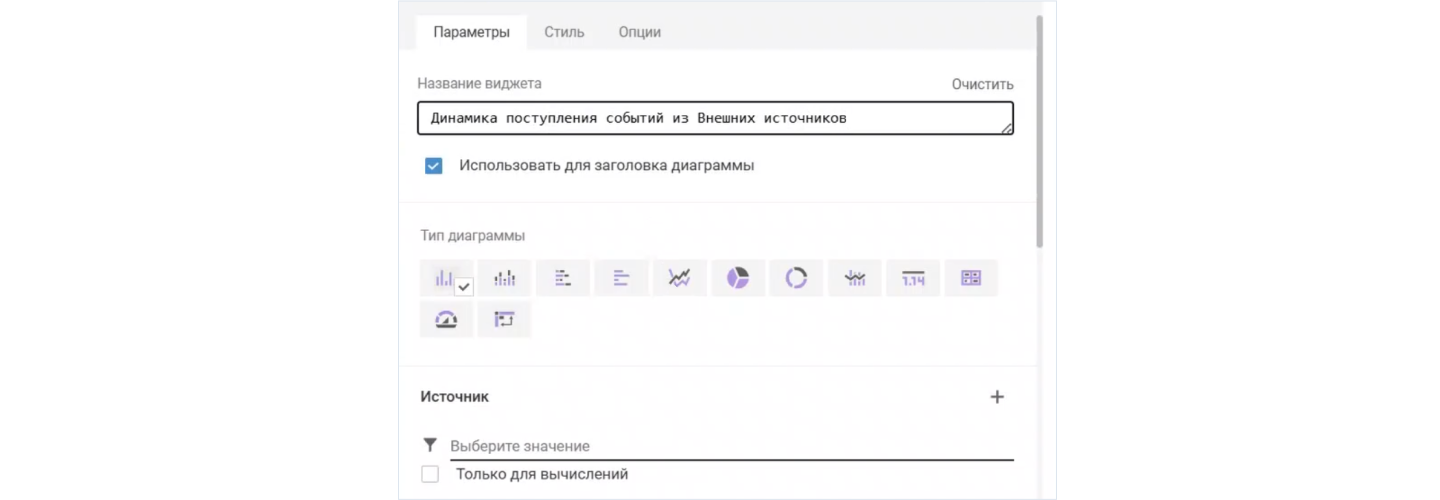
Если нужно отобразить динамику поступления событий из внешних систем, пользователь открывает дашборд, включает режим редактирования и добавляет новый виджет
Анализ метрик
В продукте представлено три типа инструментов аналитики:
- Триггеры зонтичного мониторинга — сравнивают значения метрик с порогами, анализируют одновременное поведение метрик из нескольких систем и фиксируют отклонения от заданных условий.
- Активные метрики — скриптовые вычисления, которые позволяют собирать сложные показатели и выводить их на графики или виджеты.
- Встроенное прогнозирование — предсказывает значения метрик и заранее предупреждает о рисках.
Прошедшие через анализ метрики автоматически могут вызывать последующие действия: регистрацию инцидентов и оповещения. Еще их можно посмотреть на специальных графиках, где видно фактические и прогнозируемые значения, точки срабатывания триггеров и связанные события. Наглядно представленная аналитика позволяет быстро замечать отклонения и реагировать на них до того, как показатели перейдут в критическую зону.
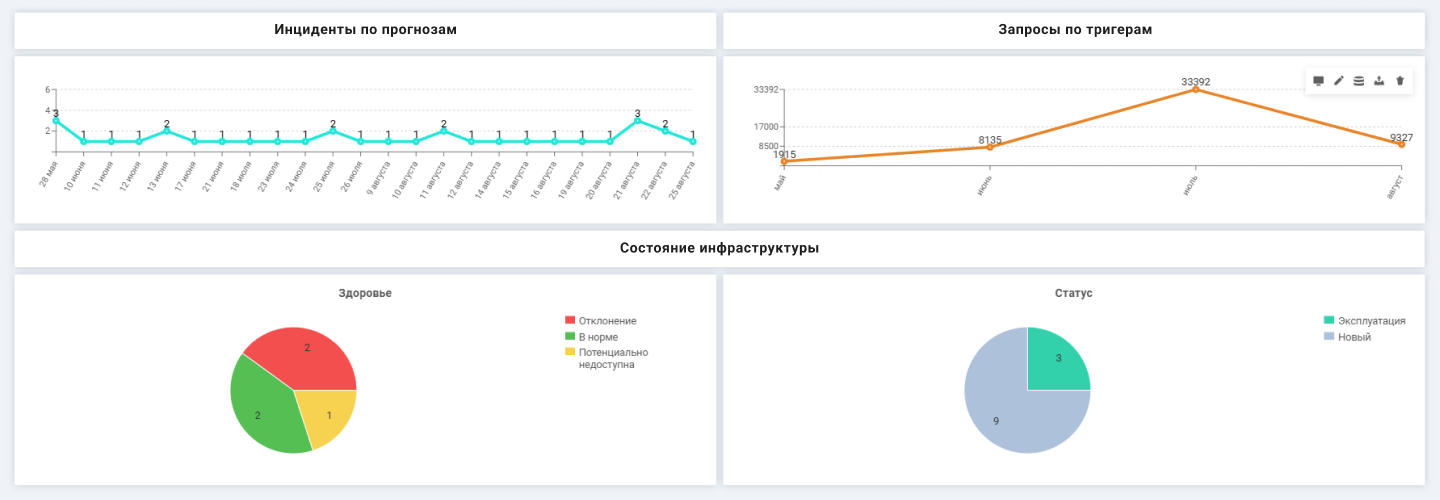
На дашборд выводится количество запросов в месяц, созданных при активации триггера, статистика инцидентов, количество оборудования с разным состоянием здоровья
Предиктивная аналитика и ML
В продукт встроены
Прогнозирование метрик
Доступна фиксация не только текущего состояния инфраструктуры, но и возможных рисков. Для этого анализируются исторические данные, тренды метрик и используются
Анализ метрик осуществляется по двум основным схемам:
- Метрики → триггеры → события. Триггеры отслеживают текущие значения метрик и формируют событие, когда показатель выходит за допустимые рамки.
- Метрики → модель прогнозирования → триггеры → события.
ML-модель с автоматически подобранными параметрами строит прогноз на выбранный горизонт и регулярно обновляет предсказание. Если ожидаемое значение метрики приближается к критическому порогу, триггер создает событие еще до фактического сбоя.
Прогнозные события обрабатываются аналогично другим. Для визуализации доступны дашборды по событиям, а также отдельные графики, где отображаются фактические значения метрик, прогнозные кривые и точки срабатывания триггеров.
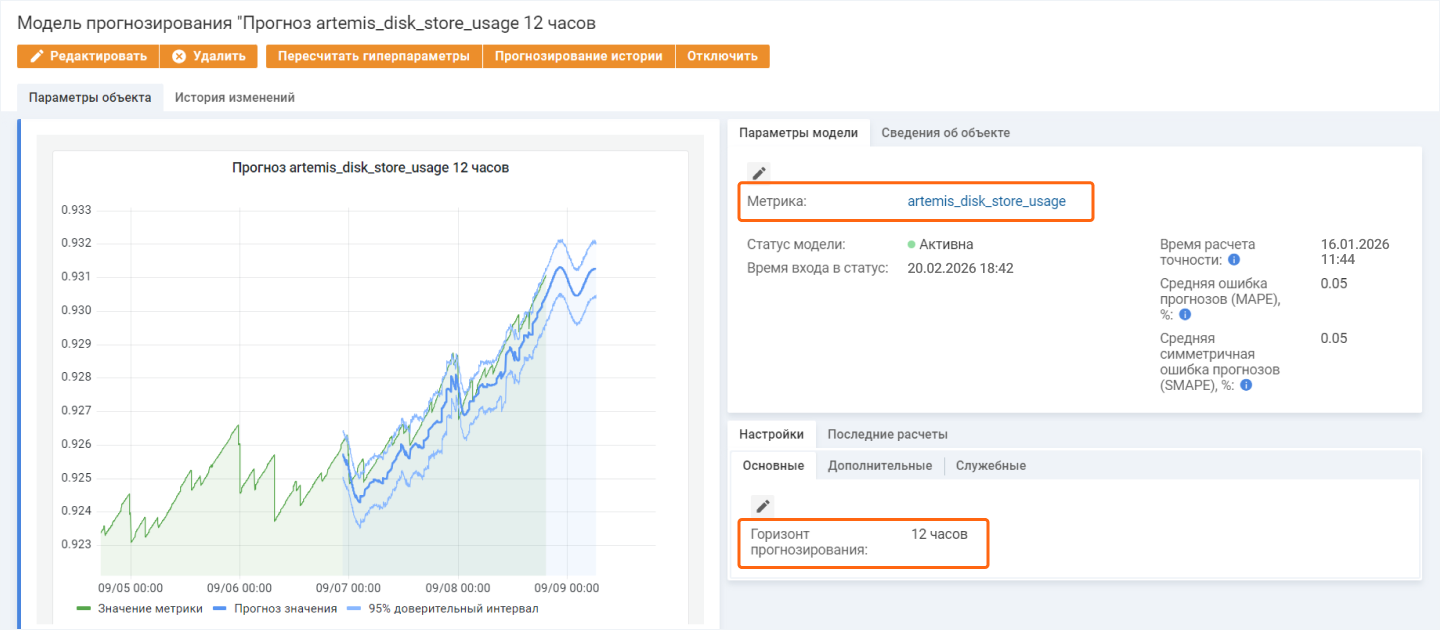
Система зонтичного мониторинга прогнозирует события, которые могут произойти с оборудованием и сервисами
Обработка событий прогнозов
Полученные на основе предиктивной аналитики и анализа метрик встраиваются в общий поток обработки событий как обычные алерты. Это значит, что система рассматривает прогнозируемые аномалии наравне с реальными сбоями — с возможностью автоматической генерации инцидентов.
ИИ позволяет обнаруживать ранние признаки сбоя — например, рост загрузки, ухудшение метрик, нестабильность — и реагировать до возникновения в реальности. Это помогает предоставлять сервисы с минимальными перерывами и снижает риск аварий.
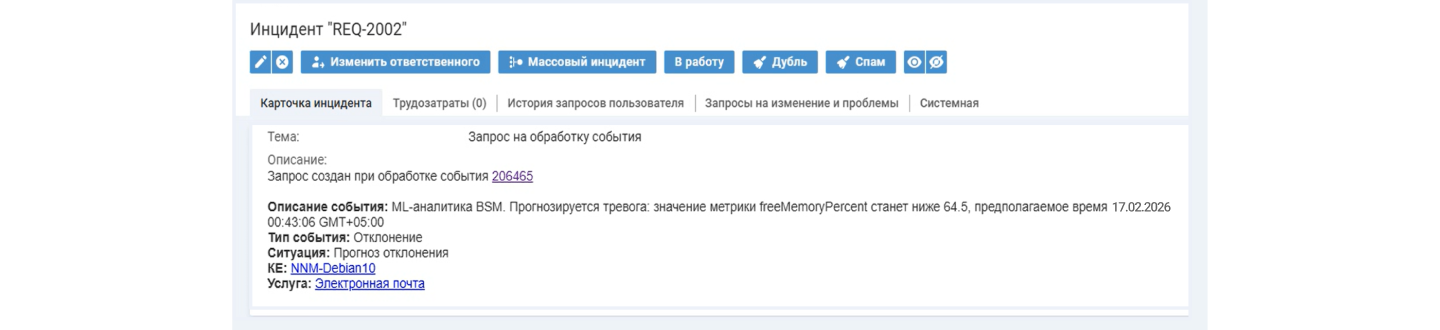
Naumen BSM фиксирует будущее отклонение как инцидент или запрос на обслуживание. Далее создает заявку до наступления отказа оборудования
К выводам
Naumen BSM обеспечивает контроль всей инфраструктуры, объединяя данные из различных систем, помогает в фильтрации и обогащении событий, расчете состояния сервисов и автоматическом создании инцидентов. Гибкие дашборды, аналитика по метрикам и возможности предиктивного анализа позволяют
Хотите оценить преимущества автоматизированного мониторинга бизнес-сервисов? Оставьте заявку, и мы проведем показ системы.