

Искусственный интеллект пишет тексты, рисует картинки, знает ответы на любые вопросы и выглядит почти всемогущим. Посмотрим, для каких задач он полезен в процессах, связанных с техподдержкой.
Основные понятия
Для начала сверимся в понимании базовых понятий.
Искусственный интеллект (ИИ) — это алгоритмы (модели), созданные под определенные задачи. Они работают на основе данных. Нет данных — нет работы и результата.
Данные — информация и сведения, которые по количеству, формату и качеству отвечают определенным требованиям. Требования формулируются, исходя из задач конкретного алгоритма.
GhatGPT, YandexGPT, GigaChat и другие —
В контексте конкретных прикладных задач речь обычно не идет о применении
- очень дорого. В данный момент такие решения требуют больших вычислительных ресурсов либо подписки на API с таким
чат-ботом ; - противоречит правилам информационной безопасности. Многие компании работают в закрытом контуре, обращения во всемирную паутину в них строго регламентируется.
Поэтому в таких случаях используются алгоритмы определенного поставщика, настроенные под
Для классификации заявок
Как это выглядит: модель классифицирует новую заявку, то есть по тексту определяет, к какой услуге она относится. Затем обращение автоматически уходит к нужному исполнителю.
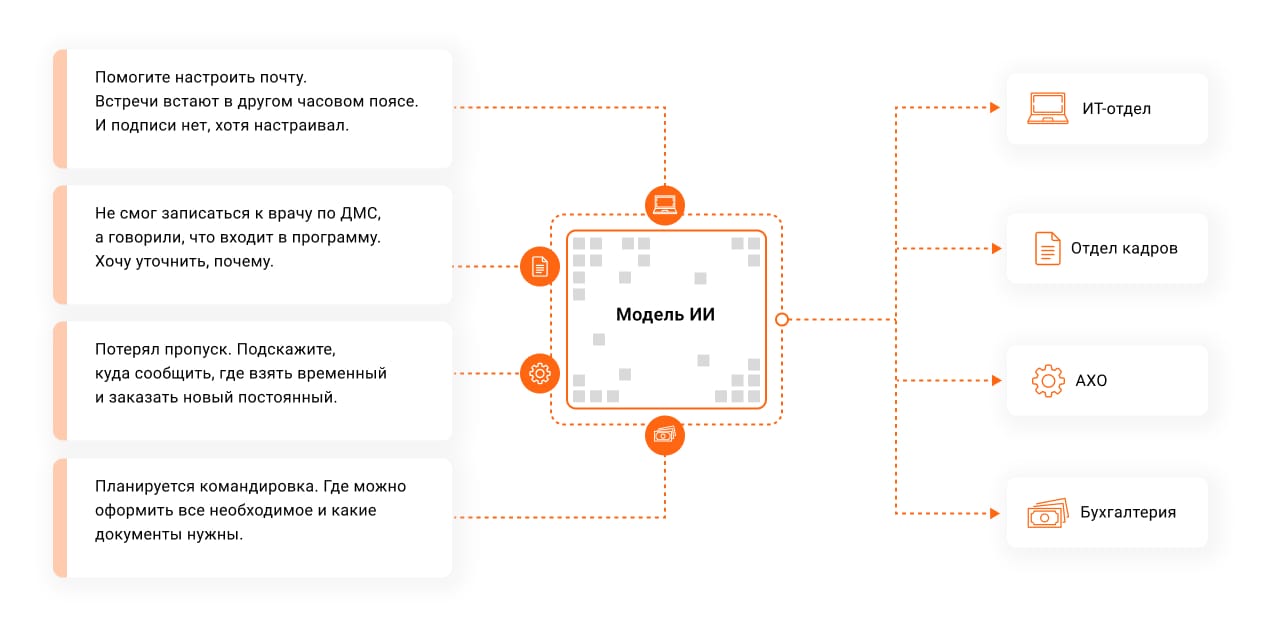
Что это дает:
- заявки обрабатываются быстрее;
- снижается потребность в операторах первой линии, которые только классифицируют обращения, но не занимаются решением проблемы.
Какие данные нужны: накопленный массив заявок в поддержку в цифровом формате. Сначала их нужно разметить, то есть отнести к различным категориями. Например, не работает принтер — в ИТ-службу, вопрос по отпуску или зарплате — в бухгалтерию, сломался стул — в АХО. На основе этих данных алгоритм обучается классифицировать обращения сам.
Если данных нет: так бывает, если компания пока не выстроила систему сервисной поддержки. Одни пользователи пишут обращения напрямую нужному сотруднику, потому что знают, что тот поможет. Другие звонят секретарю, который передает заявку по назначению. А в самих сервисных подразделениях очередь обращений — это список на доске.
В этом случае преждевременно задумываться о применении моделей ИИ. Сначала нужно накопить массив заявок. Лучший способ сделать это — внедрить систему Service Desk. Заявки в ней аккумулируются автоматически, более того — в уже размеченном виде. Например, компания, которая пользуется Naumen Service Desk и накопила в системе данные, может сама периодически запускать алгоритм в один клик. Если информации ему достаточно, он начнет работать. Если нет, то сообщит об этом.

Для определения спама
Как это выглядит: алгоритм классифицирует новое обращение как спам и автоматически перемещает в соответствующую папку.
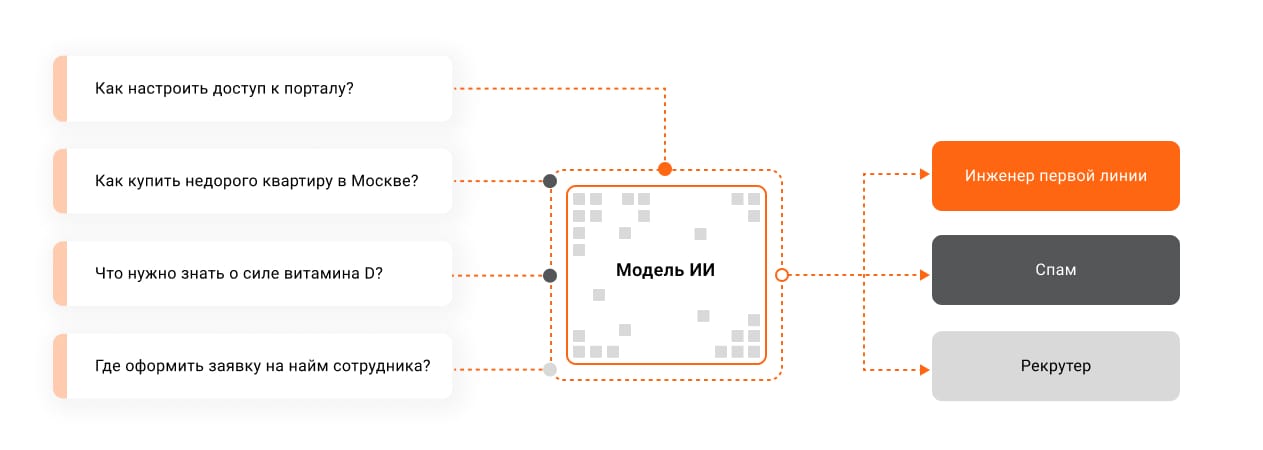
Что это дает:
- возможность снять непродуктивную загрузку со специалистов поддержки;
- экономию времени на отфильтровывании спама.
Какие данные нужны: накопленный массив обращений в цифровом формате, которые определены как спам. На основе этой информации модель научится распознавать их.
Если данных нет: как и в предыдущем случае, их нужно накопить. И оптимальным инструментом для этого станет система Service Desk.
Для быстрых ответов на типовые запросы
Как это выглядит: алгоритм классифицирует новый запрос и выдает на него ответ. Например, «Как оформить заявление на день без содержания?». Типовым ответом будет ссылка на инструкцию или путь к ней на сервере. «Кому написать про сломанную кофемашину?» — в АХО
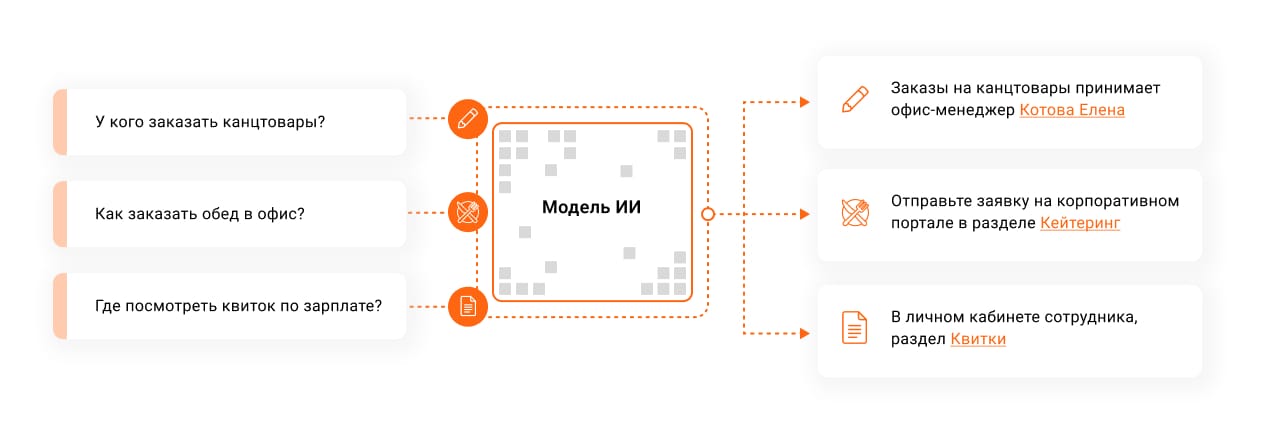
Что это дает:
- возможность решить ряд обращений без участия сотрудников;
- экономия времени на решении типовых вопросов.
Какие данные нужны: накопленная обширная база знаний компании в виде вопросов и ответов. Чем больше в ней информации, тем больше вопросов сможет решить алгоритм.
Разберем модели, которые можно использовать для такой задачи:
- Вопросно-ответная система — алгоритм учится находить в вопросах и базе знаний определенные паттерны и за счет этого отвечает пользователям.
- Векторный поиск — для этой модели данные преобразуются в числовые представления — векторы. Поиск по векторам позволяет алгоритму подобрать на вопрос более релевантные данные с большей контекстуальной глубиной. Например, запросы «Как заказать справку
2-НДФЛ » и «Как отправить заказное письмо» содержат однокоренные, сходные по значению, слова. Тем не менее смыслы запросов разные. Векторный поиск умеет их различать и давать корректные ответы. - Чат-боты на основе больших языковых моделей GhatGPT, YandexGPT, GigaChat и другие — в их основе тот же векторный поиск. Он насыщает запрос пользователя информацией из базы знаний, а затем отправляет ее в большую языковую модель, которая формирует ответ. Но такое решение вызывает вопрос о целесообразности. Как уже было сказано выше, оно дорогостоящее и противоречит принципам информационной безопасности большинства компаний.
Если данных нет: тогда нужно формировать корпоративную базу знаний. Кропотливо, день за днем пополнять ее. Именно на данном этапе многие компании отказываются от мысли применять ИИ для быстрых ответов на типичные вопросы. Формирование и ведение базы знаний — отдельная большая ежедневная работа, которая требует времени и ресурсов.
Для исключения обсценной лексики
Как это выглядит: алгоритм обрабатывает текст заявки и выделяет в ней обсценную лексику. Дальнейшие действия зависят от настройки конкретной системы. Она может просто заблюрить слова, а может заблокировать отправку запроса и вернуть его отправителю с просьбой переформулировать.
Что это дает: такая настройка исключит оскорбительные высказывания в корпоративном общении.
Какие данные нужны: в данном случае дополнительная информация от компании больше не понадобится.
К итогам
При внедрении ИИ ключевой момент — информация, на основе которой работает решение. Это может быть накопленный пул обращений пользователей в техподдержку, корпоративная база знаний компании или другие сведения — все зависит от конкретной задачи. Сбор этой информации и преобразование ее в нужный формат — всегда на стороне компании.
Да, это большая работа. Но такая база позволяет не только внедрять алгоритмы ИИ, но и решать другие задачи бизнеса: адаптировать новых сотрудников, предоставлять специалистам срез необходимой информации по
Хотите узнать, какие задачи вашей компании можно решить с помощью ИИ и Naumen Service Desk? Оставьте заявку, и мы ответим на ваши вопросы, а также покажем, как это работает в системе.








