

Массив «сырых» данных мониторинга содержит огромное количество полезной информации, но обработать ее силами только человека — нереально. Слишком много оборудования, метрик и событий постоянно фиксируется в системах корневого мониторинга. Зонтичная система Naumen BSM умеет собирать и анализировать информацию из внешних источников, а затем автоматически инициировать нужные процессы.
В статье рассмотрим, как действует система при возникновении отклонений в инфраструктуре и проведении
Как связан мониторинг событий и плановые работы
Собираемые с оборудования метрики — это источник информации о состоянии
Системы зонтичного мониторинга, такие как Naumen BSM, консолидируют сведения из внешних источников (различных систем корневого мониторинга) и обрабатывают их в соответствии с заложенными настройками. Например, собирают пассивные метрики — характеристики объектов мониторинга: серверов, виртуальных машин, ноутбуков и других устройств. Если система выявляет отклонения, срабатывают триггеры.
Триггер — это объект в Naumen BSM, который автоматически фиксирует отклонения. В правиле триггера настраивается, какие именно значения метрик считать аномальными. Для этого отмечаются, например, верхняя и нижняя границы допустимых значений. Триггер активируется, если значение метрики выходит за эти пределы.
В системе настраиваются различные сценарии реагирования на случай запуска триггера. Главное — довести до нужного сотрудника информацию о том, что устройство работает не так, как должно.
Доступны варианты: отправить уведомление на почту ответственному сотруднику или создать событие. Следующий шаг отличается для событий разных типов. Если произошла авария, то автоматически регистрируется инцидент. Если отклонение еще не привело к сбою, тогда
В ходе профилактики зачастую возникает необходимость отключить технику. При этом внешний источник продолжает собирать метрики и события, чтобы передавать в зонтичный мониторинг информацию о недоступности устройства. Обычно это приводит к активации триггеров и созданию инцидентов. В результате наступает «шторм уведомлений», когда
Все это позволяет
Как работает процесс на практике
В зонтичный мониторинг регулярно поступают пассивные метрики из внешних источников. В результате анализа метрик Naumen BSM выявляет отклонения.
Допустим, система собирает информацию с сервера и фиксирует на накопителе отклонение метрики «Температура SSD». Ее значение выше допустимого. Срабатывает триггер «Допустимая температура», и инженер получает уведомление о событии на почту.
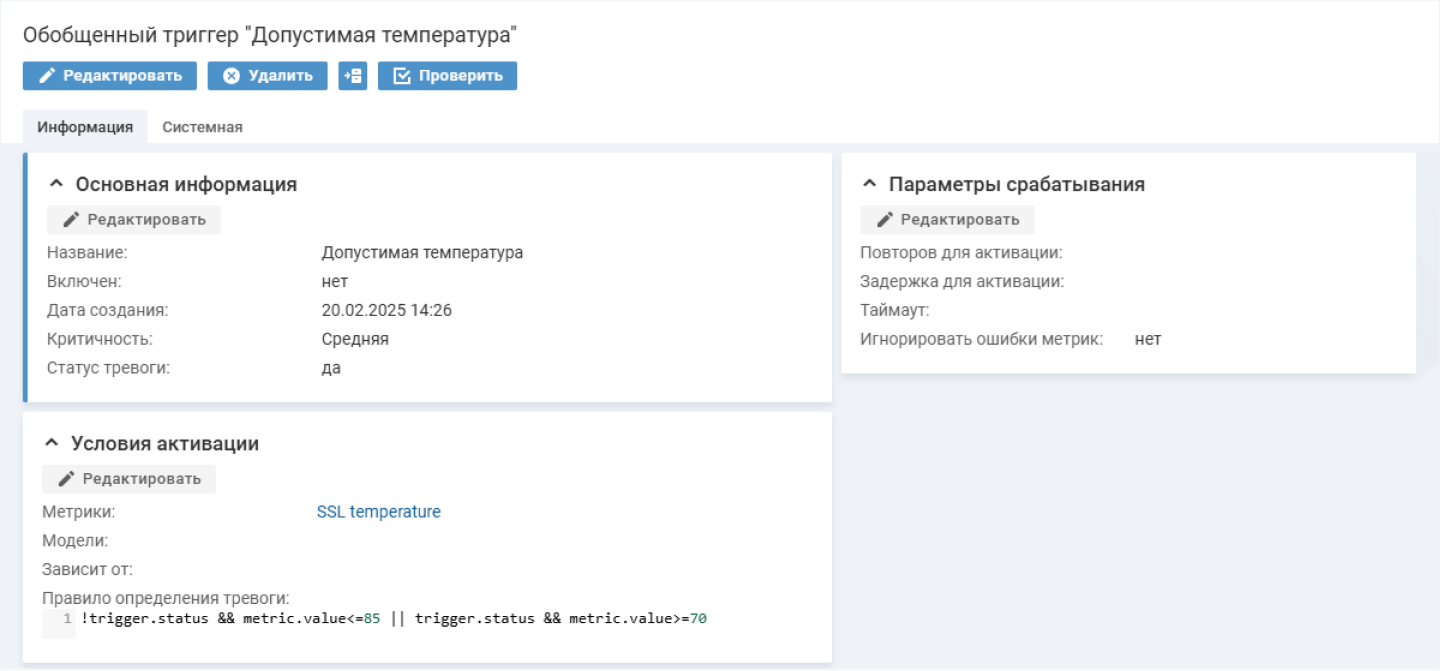
Система мониторинга зафиксировала аномальное значение метрики «Температура SSD»
Далее инженер анализирует ситуацию и понимает, что для нормализации температуры SSD потребуется заменить термопасту. Через систему Naumen Service Desk он выбирает услугу «Обслуживание серверного оборудования (внутреннее)». Затем создает плановую профилактическую работу «Замена термопасты у накопителя SSD».
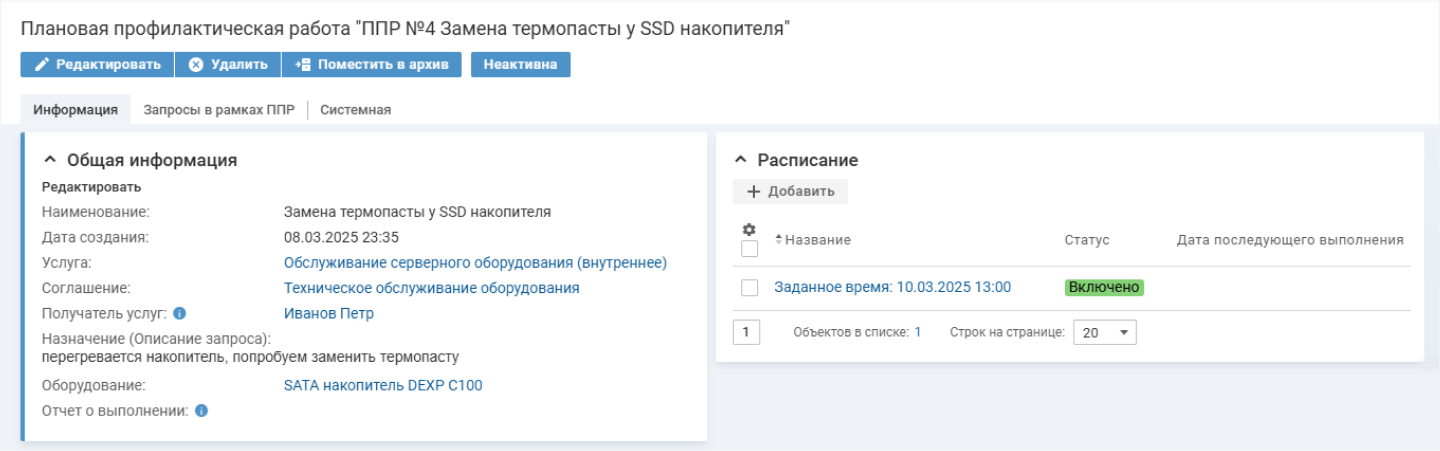
Детальная информация о плановой профилактической работе
Далее необходимо отметить устройство, на котором будет проводиться ремонт, и время выполнения. Узнать, какое именно оборудование нуждается в починке, можно с помощью данных из карточки метрики. В карточке содержится ссылка на объект автоматизированной инвентаризации (ОАИ) — физическое устройство, которое характеризует эта метрика.
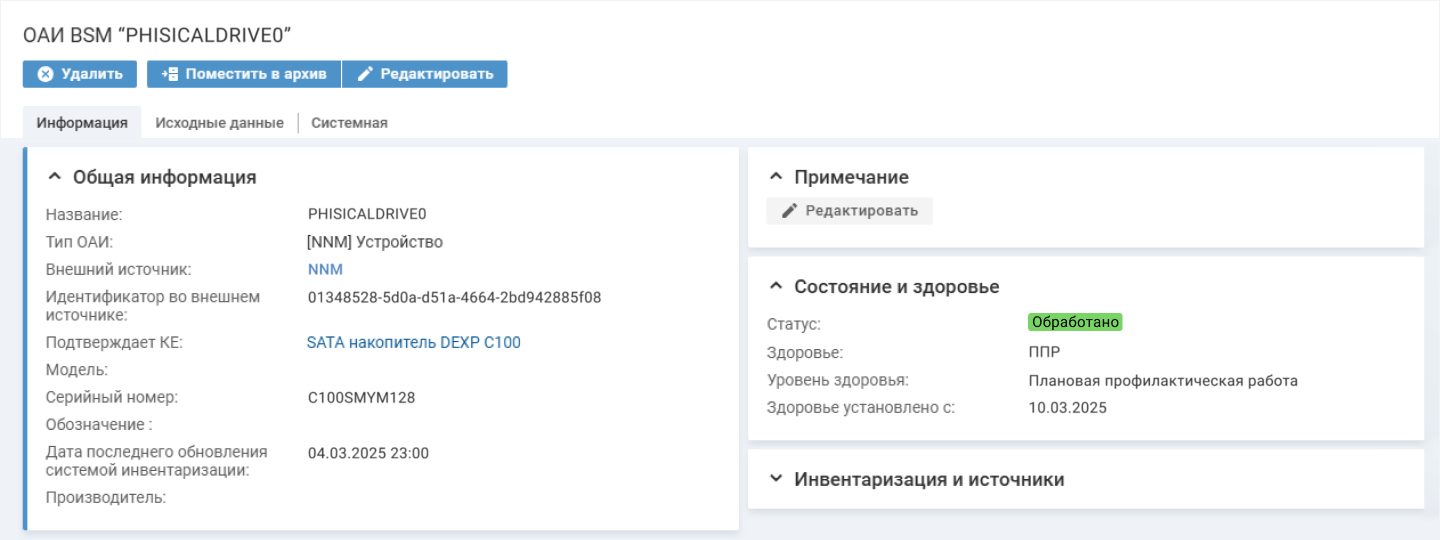
В карточке ОАИ отображаются данные сервера и его актуальное состояние здоровья
При наступлении времени, указанного в плановой профилактической работе, в системе автоматически создается запрос на обслуживание оборудования, а здоровье оборудования меняется на «Плановая профилактическая работа». Это значение будет сохраняться все время, пока открыт запрос. Что это дает? Всем событиям, которые поступят о недоступности обслуживаемой техники в этот период, будет присвоен статус «Отложено». Так Naumen BSM помогает исключить регистрацию лишних инцидентов во время профилактики, например, при отключении техники.
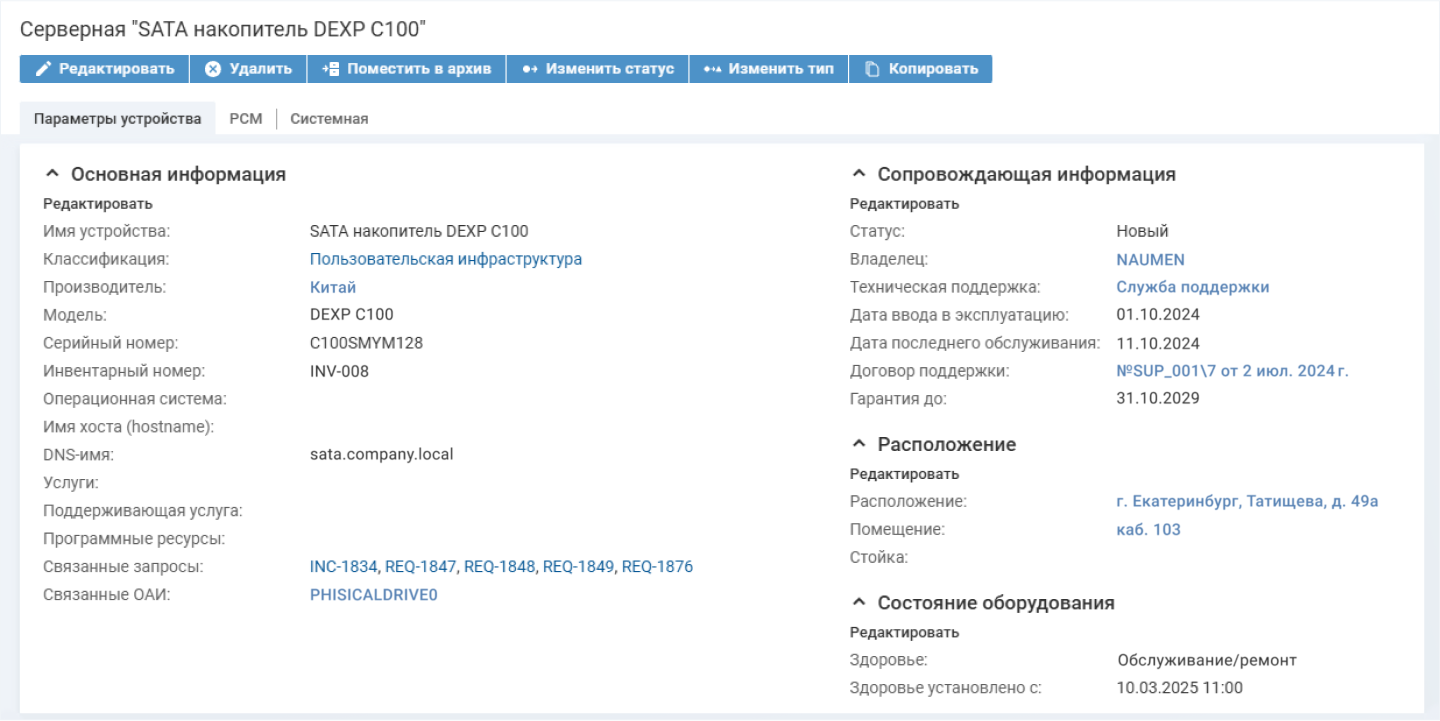
При отключении оборудования система инфраструктурного мониторинга фиксирует аварийные события. Благодаря плановой работе зонтичная система понимает, что из внешнего источника приходят ложные аварии, и игнорирует их
К выводам
Naumen BSM позволяет обрабатывать данные мониторинга и запускать триггеры — соответствующие механизмы реагирования. Так, при обнаружении отклонения система автоматически уведомляет технических специалистов.








