
Классический
Если в применяемую систему добавить алгоритмы искусственного интеллекта (ИИ), то появится возможность предсказывать проблемы в
Риски классического ИТ-мониторинга
В крупных компаниях для отслеживания работоспособности оборудования и других элементов
Если специалисты реагируют на критическую ситуацию в инфраструктуре только по факту, у такого способа есть ряд недостатков.
Нет времени для анализа и выбора решения. Если метрика уже приняла критическое значение, сервисные службы должны реагировать срочно. В таких условиях есть риски, что инженеры неверно интерпретируют ситуацию и подберут неоптимальный вариант для решения проблемы.
Сложные поломки оборудования. При выходе оборудования из строя ремонтировать его может оказаться дороже, чем своевременно обслуживать.
Перебои в предоставлении услуг. Чтобы после поломки восстановить работоспособность оборудования, потребуется время. А любой простой приводит к недоступности связанных услуг.
Скорость и своевременность реакции на неисправности максимально критична для
Как усовершенствовать ИТ-мониторинг
Классический мониторинг реагирует на эксплуатационные сигналы тревоги, когда показатели уже приняли критическое значение. Но если предсказывать ухудшение показателей заранее, у ответственного подразделения будет больше времени, чтобы проанализировать ситуацию и заблаговременно принять меры.
Это возможно, когда используется предиктивная аналитика, которая прогнозирует сбой уже при первых признаках отклонений в показателях. Такая функциональность работает на основе алгоритмов ИИ и машинного обучения. Чтобы предсказать значение показателей в будущем, берутся накопленные данные в
Иными словами, классический мониторинг анализирует текущее значение метрик, а предиктивная аналитика — прогнозируемое. Поэтому время до вероятной остановки работы оборудования увеличивается. Это дает возможность устранить неисправности до того, как они начнут оказывать на сервисы влияние, ощутимое для пользователей.
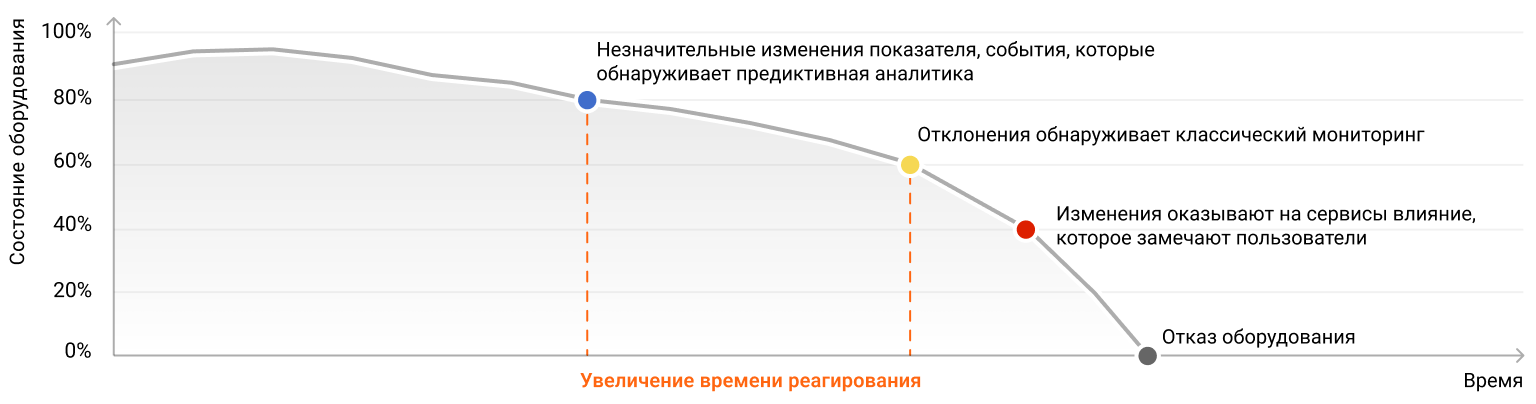
Классический мониторинг обнаруживает отклонения, когда производительность оборудования уже снижена. Предиктивный анализ поможет заранее оповестить о потенциальном снижении показателей. Благодаря этому у ответственных инженеров появляется запас времени, чтобы принять меры
Предиктивная аналитика позволяет не только прогнозировать события по историческим данным об инцидентах. Также механизм пригодится, чтобы оценивать требуемые объемы ресурсов на основании истории их потребления.
Какие задачи решает предиктивная аналитика
Рассмотрим, как работает предиктивная аналитика на примере функциональных возможностей Naumen BSM — решения для комплексного мониторинга
Выявление аномалий в метриках оборудования
Допустим, система мониторинга отслеживает состояние серверного и сетевого оборудования. Если все нормально, то показатели колеблются в рамках определенного значения. Когда метрика резко увеличивается или уменьшается — это свидетельствует о нетипичном поведении. Такое отклонение называют выбросом или аномалией.
Существуют разные способы обнаружения аномалий на основе ИИ. В Naumen BSM используются статистические модели, которые автоматически определяют коридор типичных значений метрики по поведению ряда и детектируют выбросы. Чтобы система корректно выявляла аномалии, нужно предварительно настроить параметры, по которым она будет анализировать поступающие значения метрик. Например:
- сколько раз подряд метрика должна выйти из коридора типичных значений;
- какое отклонение допустимо, чтобы показатель считался типичным;
- за какой срок анализировать данные, чтобы увидеть типичное поведение метрики.
Если метрика вдруг принимает аномальное значение, это может сигнализировать, что компонент инфраструктуры работает нештатно и пора искать причину, чтобы предотвратить дальнейшее ухудшение ситуации. В зависимости от критичности аномалии задаются разные варианты: можно отправлять предупреждающие уведомления либо регистрировать события и настраивать последующие действия, в том числе создавать инциденты.
Представим, что в системе мониторинга для тестового стенда отслеживается свободное место на диске, чтобы стенд всегда оставался работоспособным. Значение метрики обновляется каждые 30 секунд. Мы знаем, что объем свободной памяти может быстро меняться, но в обычном рабочем режиме эти колебания всегда остаются в некоторых рамках. То, как используется и освобождается память, также зависит от времени суток. Поэтому для анализа может быть задана глубина истории 30 минут. На графике видно, что в момент 00:14 было детектировано аномальное снижение памяти, нетипичное для последнего времени. При этом мы указали в параметре «Повторов для активации» значение 4, чтобы не считать аномальными отдельные пиковые значения, после которых метрика возвращается к типичному поведению. При такой настройке аномалией будет считаться четыре следующих подряд нетипичных значения. После обнаружения аномального поведения метрики система оповещает ответственных сотрудников об этом. В данном случае — о нетипичном падении свободной памяти на диске тестового стенда.
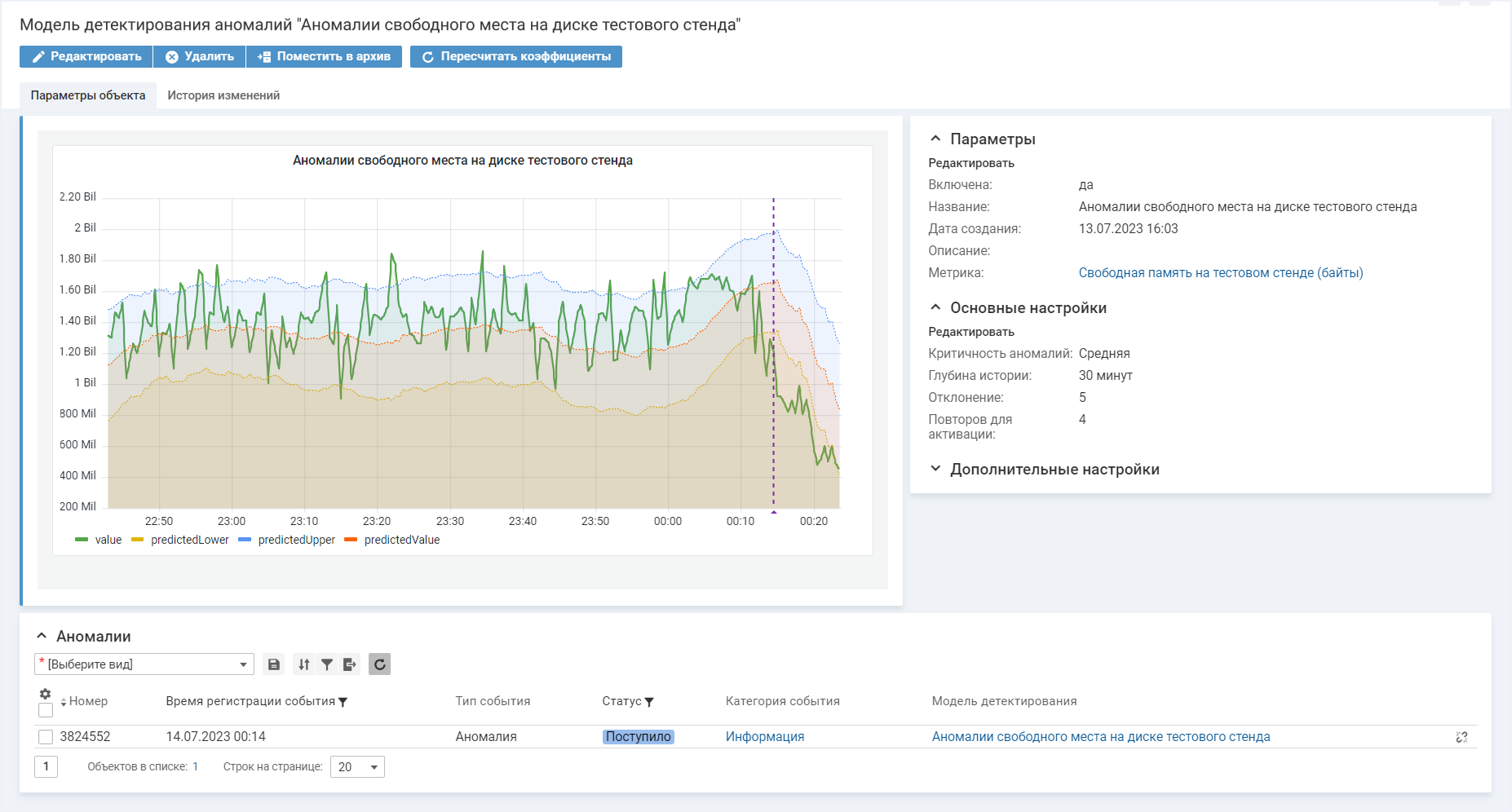
Модель выявила аномалию при оценке свободного места на диске тестового стенда
Прогнозирование поведения метрик инфраструктуры
Любые показатели меняются с течением времени: уменьшаются или растут. Тенденцию движения метрики к более высоким или низким значениям в
В Naumen BSM для определения тренда применяется предиктивная модель. Для ее работы пользователь задает горизонт. Чтобы установить его корректно, нужно учитывать не только желаемую дальность прогноза, но и другие факторы:
- свойства оборудования, с которым связана метрика. Например, как часто обновляется значение метрики, насколько сильно оно меняется в нормальном режиме;
- особенности
бизнес-процесса компании. Например, как настроен SLA и за какое время инженеры сервисной службы должны среагировать, когда приходит уведомление о прогнозируемой тревоге.
Остальные параметры автоматически рассчитываются системой исходя из свойств конкретной метрики, таких как частота обновления, разброс значений, сезонные колебания и других.
Также для прогноза можно установить пороговое значение в триггере. Если график пересечет порог, это будет означать, что ожидается недопустимое значение. Например, на графике падения свободной памяти на диске в течение ближайшего часа можно указать отметку критически низкого объема памяти. Дальше это будет работать так: модель получает новые значения метрики и периодически пересчитывает прогноз на ближайший горизонт. Если в один из прогнозов модель предсказала, что вскоре значение метрики выйдет за пределы допустимых значений, то сработает триггер, а пользователь получит уведомление.
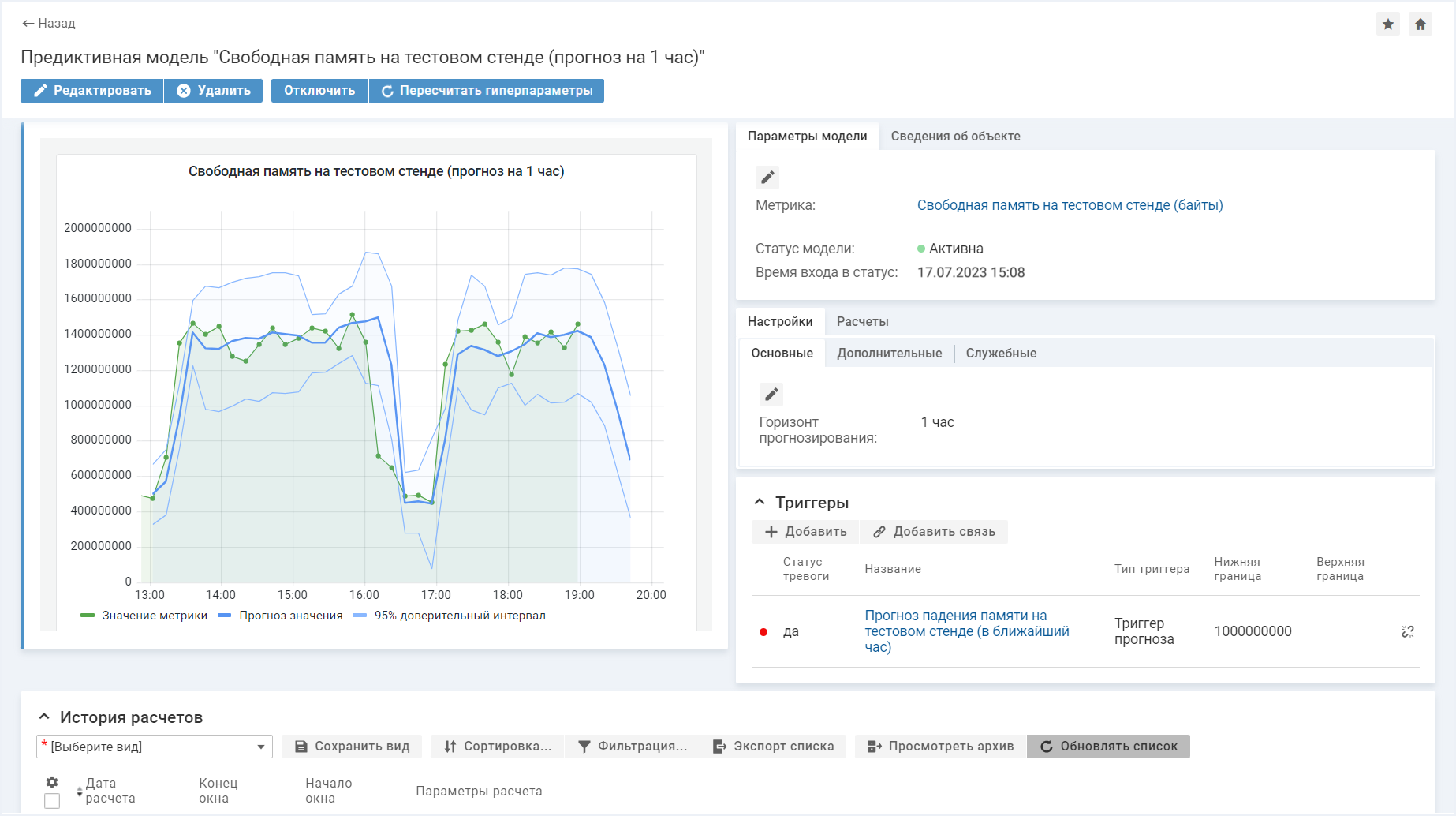
Модель предсказывает свободный объем памяти тестового стенда на ближайший час
Уведомление об аномалии и прогнозируемой тревоге
Система с предиктивной аналитикой только детектирует нетипичное поведение метрики и предупреждает о нем. Оценкой критичности ситуации и подбором необходимых мер занимаются сервисные специалисты. Поэтому важно, чтобы они своевременно узнавали о наступлении аномалии.
В Naumen BSM можно настроить необходимый процесс при срабатывании триггера. Например:
- отправлять ответственному специалисту
пуш-уведомление ввеб-клиенте или оповещение по почте; - регистрировать инцидент, создавать задачи;
- выполнять другую последовательность действий.
Если настроено предупреждение, то в нем указывается, какой триггер сработал, к какой метрике он относится, когда прогнозируется событие и сколько времени до него осталось.
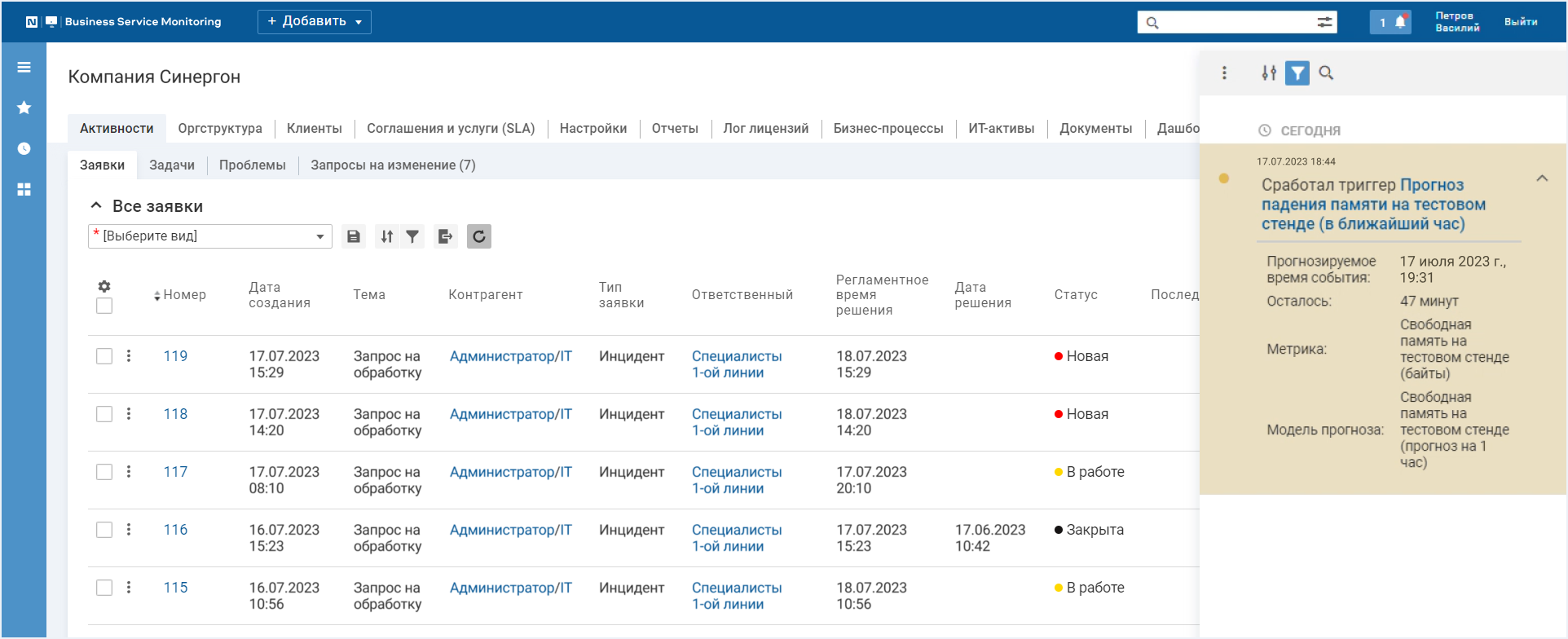
Уведомление содержит всю основную информацию о событии активации триггера
По клику на уведомление пользователь попадает на карточку события с окном прогноза,
В карточке триггера представлен график последнего прогноза и линия порогового значения — граница допустимых значений метрики, а также все предыдущие значения этой метрики, которые были учтены моделью при его построении. В системе регистрируются как отклонения триггера прогноза, так и события его восстановления. Восстановление происходит, если последующее окно прогноза показало, что значение метрики вскоре вернется в допустимые пределы. Важно отслеживать оба эти момента, чтобы не тратить ресурсы на выполнение лишних работ по анализу ситуации, когда поведение метрики уже вернулось в норму.
События восстановления и отклонения отражаются на карточке триггера. Эта информация позволяет проанализировать историю активации триггера, например, чтобы скорректировать его настройки, такие как пороговые значения.
В нашем примере уведомление придет инженеру, ответственному за работоспособность тестовых стендов подразделения. Согласно прогнозу, критичное снижение памяти ожидается в течение часа (через 47 минут). Это означает, что инженер успеет освободить место на диске стенда, проанализировав загрузку и выполнив очистку от невостребованных данных. Так благодаря предиктивному анализу в мониторинге будет обеспечена стабильная работоспособность стенда.
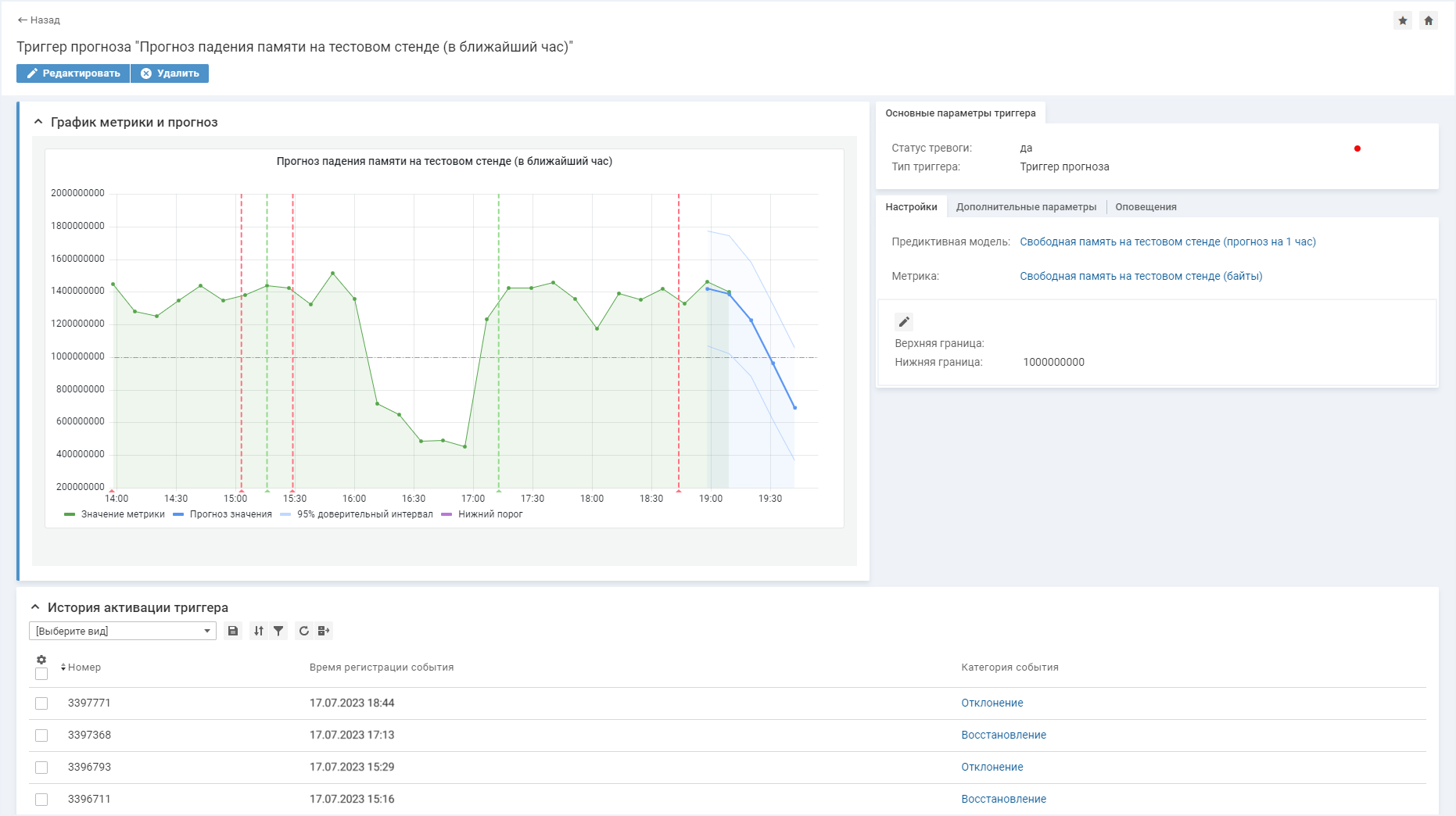
Срабатывания и восстановления отражаются в списке событий на карточке триггера и на графике в виде вертикальных линий. Красная линия обозначает тревогу по прогнозу, зеленая — отмену тревоги
Комплексный анализ набора метрик
На практике элементы инфраструктуры действуют связно, поэтому есть показатели, изменения которых важно отслеживать в комплексе. Зачастую для этого необходимо получать метрики из нескольких систем мониторинга.
В Naumen BSM предусмотрена возможность анализировать комплекс из нескольких метрик с помощью обобщенного триггера. Зонтичный мониторинг позволяет собирать показатели из разных систем, а механизм обобщенного анализа — описывать сложные критерии для набора метрик и создавать для них правила реагирования. В обобщенном триггере настраивается:
- критичность — высокая, средняя, низкая или предупреждение;
- метрики, которые учитывает триггер;
- правило определения тревоги, задающее критерий тревоги по совокупности метрик в различных соотношениях;
- число повторов события или задержка до активации триггера;
- зависимости между триггерами.
В обобщенном триггере задаются сложные правила мониторинга и объединяются различные метрики, технические и
Допустим, создается триггер, который одновременно отслеживает текущее значение свободной памяти на диске и число активных пользователей. Свободная память на диске поступает из Zabbix, а количество подключений из Prometheus. Данный триггер будет активироваться, когда свободной памяти уже немного и при этом наблюдается увеличение числа активных пользователей, что может говорить о риске скорой нехватки памяти.
Другой пример использования обобщенного триггера — отслеживание статистики тревог по конкретному объекту мониторинга. В правиле определения тревоги можно наблюдать число связанных аномальных событий за период и их динамику. Если аномалии стали регистрироваться чаще, это может говорить о нестабильной работе оборудования и необходимости его профилактического обслуживания.
Аналогично обобщенный триггер можно связывать не только с метриками, но и с предиктивными моделями, и учитывать их прогнозы в сложных правилах определения тревог.
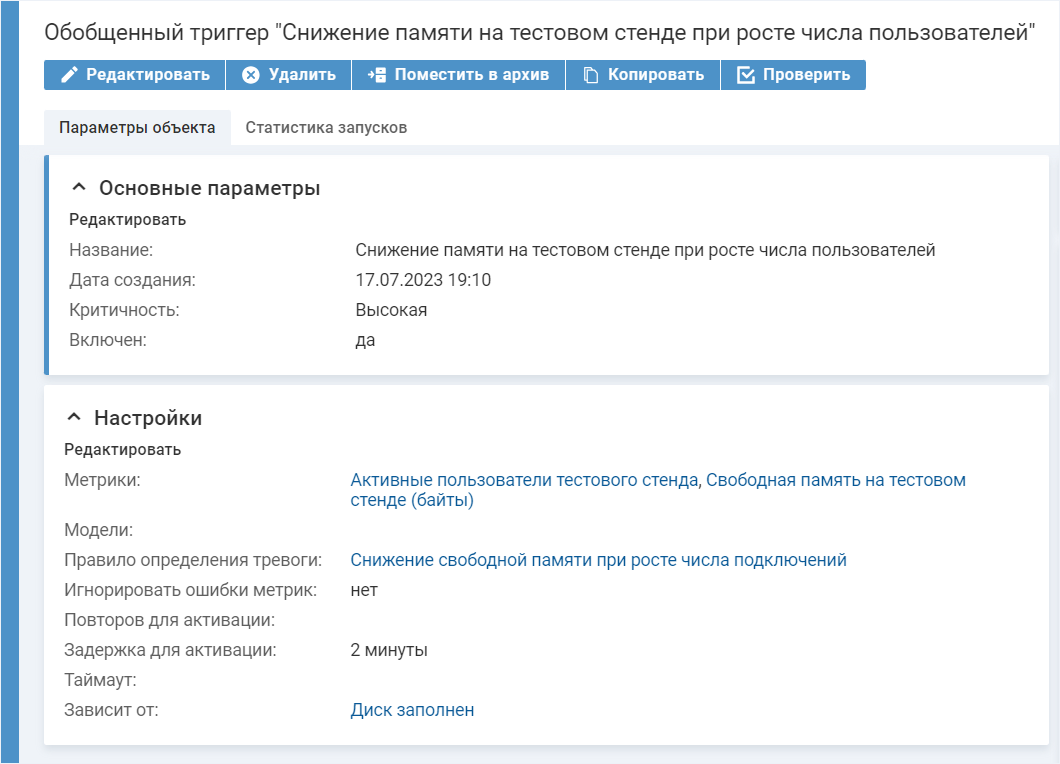
Обобщенный триггер объединяет метрики свободной памяти на тестовом стенде и число активных пользователей
В заключение
Использование в
Действуйте на опережение с Naumen BSM. Узнавайте об инцидентах раньше, чем они произойдут. Покажем, как это работает.








