

При масштабировании бизнеса нагрузка на первую линию поддержки продолжает расти, а ожидания пользователей по скорости и точности ответов повышаются. Справиться с этими вызовами помогает искусственный интеллект в Service Desk.
Эффективность ИИ зависит от проработки решения с точки зрения сложности и критичности функционала, а также от понимания ожиданий пользователя и пути клиента. Классический запуск простых
Naumen предлагает альтернативную модель: ИИ как инструмент поддержки оператора. В статье разбираемся, как устроены
Сложные задачи первой линии поддержки: взгляд изнутри
Представим обычный день оператора техподдержки. В основном это похожие задачи: предоставить информацию, отправить инструкцию, устранить неполадки, проконсультировать клиента. Чтобы решить каждую, нужно вникнуть в описание, обратиться к базе знаний или внешним источникам, а потом оформить ответ.
Теперь все это можно автоматизировать с помощью ИИ. Но чтобы выбрать подходящие
Классификация и маршрутизация обращений
Когда заявка поступает на рассмотрение, оператор учитывает несколько потенциальных рисков.
Заявитель может неправильно указать услугу в заявке. Например, при запросе дополнительного доступа пользователь регистрирует инцидент вместо запроса на обслуживание или выбирает слишком общую категорию — «Прочее» или «Ошибка сервиса».
Ошибка на входе приводит к тому, что заявка уходит не тому специалисту, SLA считается некорректно, а автоматические процессы не запускаются. Это связано с тем, что услуга в запросе влияет на другие параметры работы с обращениями: назначение ответственной команды, сроки по SLA, автоматические процессы создания согласований, запросов на изменения и задач, запускаемых
Решение. Оператору нужен инструмент, который проанализирует описание заявки, сопоставит с каталогом услуг и предложит корректную классификацию с учетом типа обращения (инцидент или запрос), SLA и
Работа с неструктурированными данными заявки
Описание запроса может содержать недостаточно данных для анализа и решения. Оператору на первом этапе сложно заранее спрогнозировать, чего именно не хватает. Это ведет к простою: нужно запрашивать дополнительную информацию у заявителя и ждать ответа.
Другая потенциальная проблема — избыточность данных. Описание может быть неструктурированным, содержать много лишней информации, среди которой оператор рискует не понять суть запроса или пропустить важные детали инцидента.
Решение. Оператору нужен инструмент, который структурирует описание, выделяет ключевые факты (что случилось, на каком оборудовании, какие действия предпринимал пользователь) и автоматически формирует список уточняющих вопросов, если информации недостаточно.
Поиск решений в распределенных источниках знаний
Когда оператору поступает запрос, ему нужно понять, какой регламент применяется к данному обращению (например, с кем согласовывать доступ) и обращались ли пользователи ранее с подобной проблемой и как она решалась.
Для этого приходится вручную анализировать большой объем информации: статьи базы знаний, историю похожих инцидентов и запросов, внутренние регламенты, файлы в корпоративных системах. Без анализа специалист рискует потратить время на решение, которое уже реализовано, или ошибиться при обработке запроса, тем самым увеличив время обработки обращения.
Решение. Оператору нужен инструмент, который автоматически ищет наиболее релевантные ответы в распределенных источниках знаний и выдает готовый текст со ссылкой на источник.
Формирование отчетов о решении
Если отчеты о решении постоянно формируются вручную, то зачастую они не имеют единой структуры и не формализованы. Впоследствии по таким отчетам сложно собирать базу знаний и переиспользовать опыт для устранения подобных инцидентов.
Решение. Оператору нужен инструмент, который формирует стандартизированный отчет, пригодный для пополнения базы знаний.
Ограничения базовой автоматизации
Классическая автоматизация строится на фиксированных правилах и маршрутах. У нее нет гибкости: любое отклонение от прописанного сценария приводит к сбою или остановке процесса.
Возникает вопрос, как оптимизировать процесс по управлению запросами таким образом, чтобы решения подбирались корректно с учетом контекста и внутренней базы знаний.
Решение. AI в управлении запросами помогает с такими задачами.
Ограничения чат-ботов и простых цифровых помощников
Кроме того, у таких ботов слабая связь с корпоративными знаниями. Они не умеют в реальном времени обращаться к базе знаний, истории инцидентов или регламентам. А без доступа к актуальным знаниям бот не даст корректное решение проблемы.
Возникает риск ошибочных или общих ответов, которые не закрывают задачу пользователя. Виртуальный помощник вынужден переписывать запрос
Решение. Дообучение AI в управлении инцидентами и на сложных сценариях, в отличие от базовых
AI-ассистенты и AI-агенты : единая модель поддержки
AI для первой линии поддержки — это инструментарий, который позволяет вести диалог с пользователем и на основании настроек (источников знаний, промптов, LLM, скриптовых модулей инструментов) помогают решить задачу.
При внедрении ИИ в Service Desk важно различать эти инструменты.
| Критерий | ||
| Роль | Советник, консультант | Исполнитель, оператор действий |
| Что делает | Ищет информацию, предлагает ответы, генерирует гипотезы | Классифицирует обращения, находит информацию, закрывает заявки, отправляет ответы и отчеты |
| Пример задачи | «Найди решение в базе знаний» | «Восстанови пароль и доступ к аккаунту» |
| Кто принимает решение | Оператор | Агент — после подтверждения оператора |
| Соблюдение информационной безопасности | Нет риска изменения данных | Риск уязвимости в безопасности ИТ без предварительной валидации действий оператором |
В Naumen Service Desk реализованы как ассистенты, так и агенты. Ключевое условие — любое их действие происходит только после подтверждения оператором. Таким образом ИИ не заменяет человека, а берет на себя рутинную исполнительскую работу — ответственным за заявку и финальное решение остается оператор.
Как устроены AI-ассистенты и агенты в Naumen Service Desk
При внедрении AI в Service Desk нужно учитывать архитектуру, на которой строится решение. В основе
Поддержка облачных и локальных LLM. Система поддерживает подключение облачных LLM через OpenAI API, а также использование локальных
Работа с корпоративными знаниями через RAG.
RAG-пайплайн содержит локальные модели:
- эмбеддер — преобразует текст в числовые векторы;
- реранкер — ранжирует результаты векторного поиска;
- модель доступа к векторной базе данных.
LLM получает наиболее подходящие результаты из источников знаний, отбрасывая нерелевантные документы и тем самым уменьшая объем контекста. Это повышает точность ответов и снижает риск галлюцинаций.
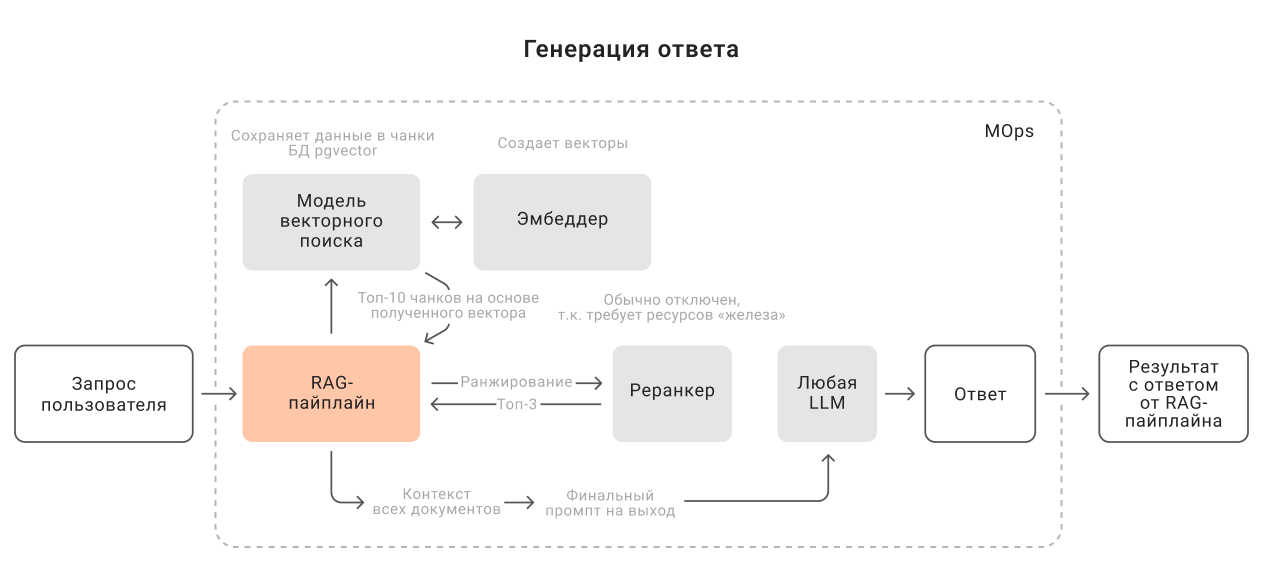
Векторный поиск и реранкер отбирают наиболее релевантные фрагменты, и LLM генерирует ответ только на их основе
Безопасность и управляемость. Ассистенты доступны не всем пользователям, а только тем группам специалистов, для которых администратор системы настроил доступ.
В отличие от систем, предлагающих заменить операторов на
Ассистент по знаниям (Knowledge Assistant)
Что делает. Ищет ответы среди внутренних источников знаний: статей базы знаний, истории запросов и инцидентов, файлов и регламентов. Ассистент выдает наиболее релевантную информацию и указывает источник. Оператор может перейти в источник, чтобы изучить информацию подробнее. Если данных нет, ассистент не выдумывает ответ, а отвечает: «По вашему запросу решение не найдено».
Результат. Оператору больше не нужно самостоятельно анализировать большой объем разных источников, искать похожий запрос и оценивать релевантность ответа. Ассистент делает все за него. Снижается время поиска и количество ошибок.
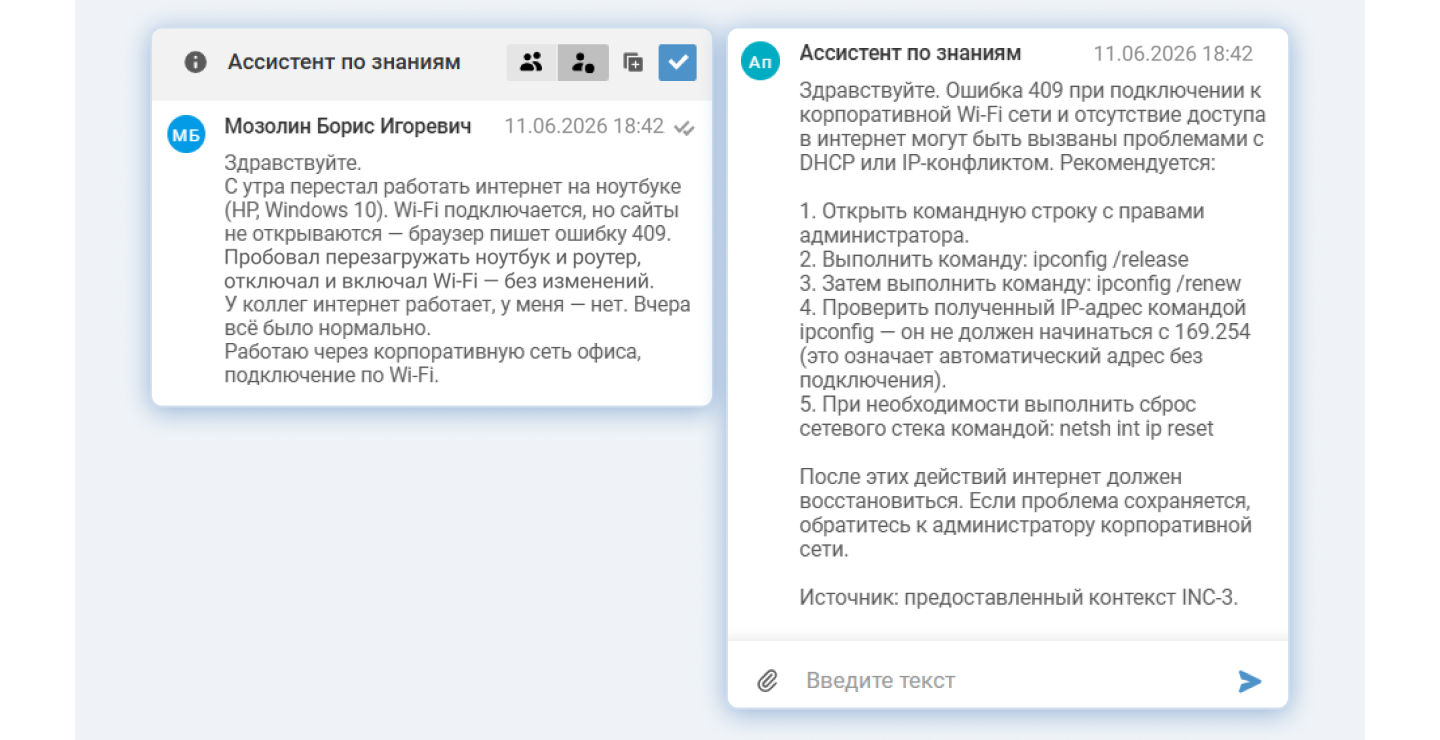
Пользователь описывает проблему, ассистент находит решение в базе знаний и выдает готовую инструкцию со ссылкой на источник
Ассистент по открытым источникам
Что делает. Если во внутренних знаниях отсутствует информация, то поиск ведется в предварительно настроенных и одобренных компанией ресурсах.
Открытыми источниками обычно выступают:
- техническая документация вендоров, загруженная в корпоративный контур;
- публичные базы знаний по используемому ПО с контролируемым доступом;
- внутренние wiki и порталы, находящиеся вне Service Desk, но внутри периметра;
- истории инцидентов из смежных систем мониторинга.
Затем ассистент предлагает оператору наиболее подходящее обходное решение. Также он консультирует оператора по возможной причине инцидента, что в дальнейшем помогает определить причины проблем или изменений в
Результат. Оператор экономит время на поиск ответа, быстро восстанавливает сервис и получает гипотезу о причине инцидента.
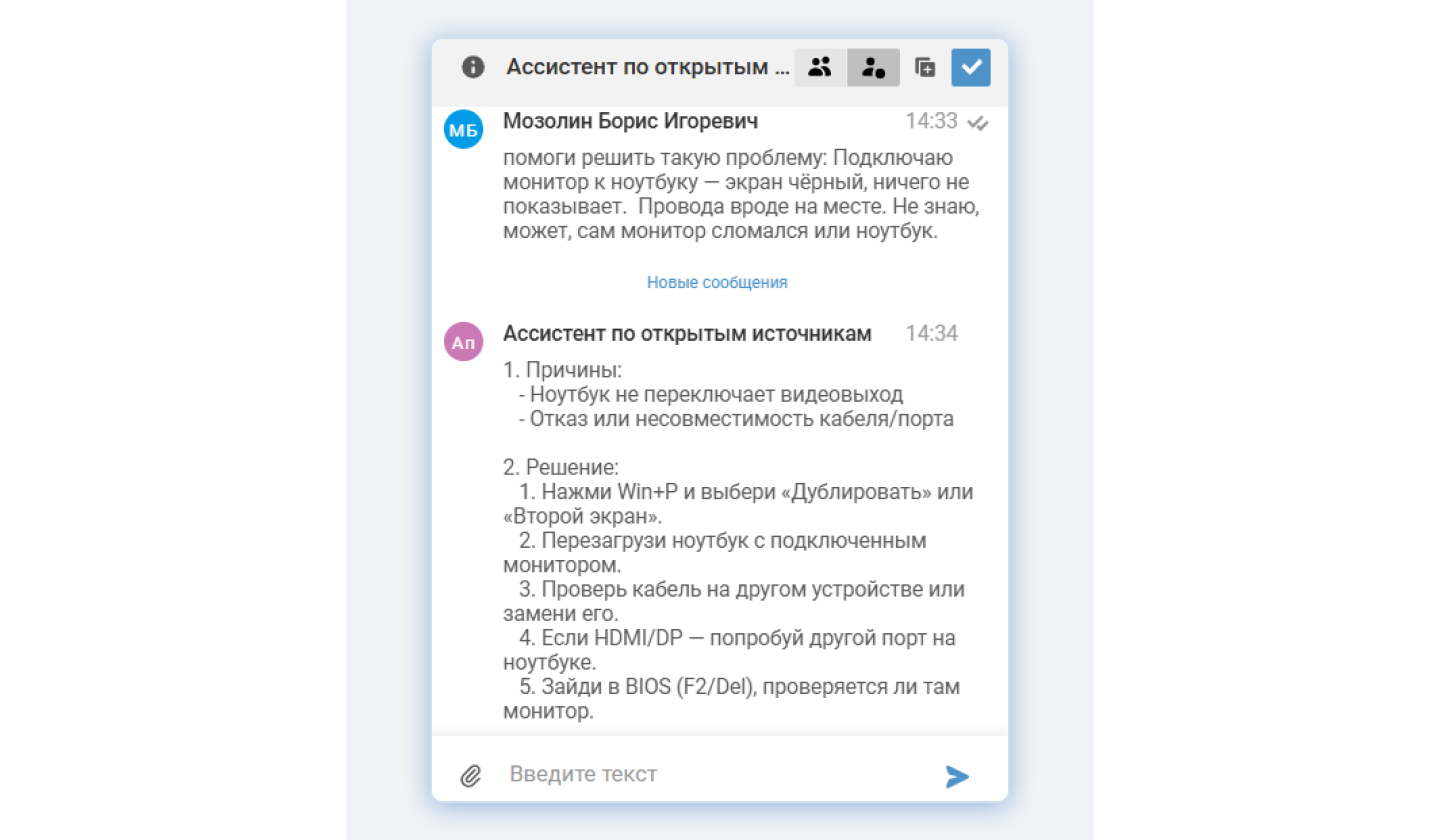
Ассистент по открытым источникам разделяет ответ на причины и решения, что позволяет оператору быстро понять логику диагностики и предложить пользователю конкретные шаги по устранению проблемы
Агент для переклассификации обращений
Что делает. По запросу оператора собирает информацию о заявке и обо всех доступных заявителю услугах. Проверяет, корректно ли выбраны услуга и тип запроса. Если нет — предлагает оператору наиболее подходящие услугу, соглашение и тип запроса из всех доступных. После подтверждения оператором агент автоматически переклассифицирует запрос.
Результат. Корректная классификация заявки, которая опредлеляет параметры запроса и процедуру решения. Например, назначение ответственного за поддержку услуги, сроки по SLA, автоматическое создание согласований и задач в рамках
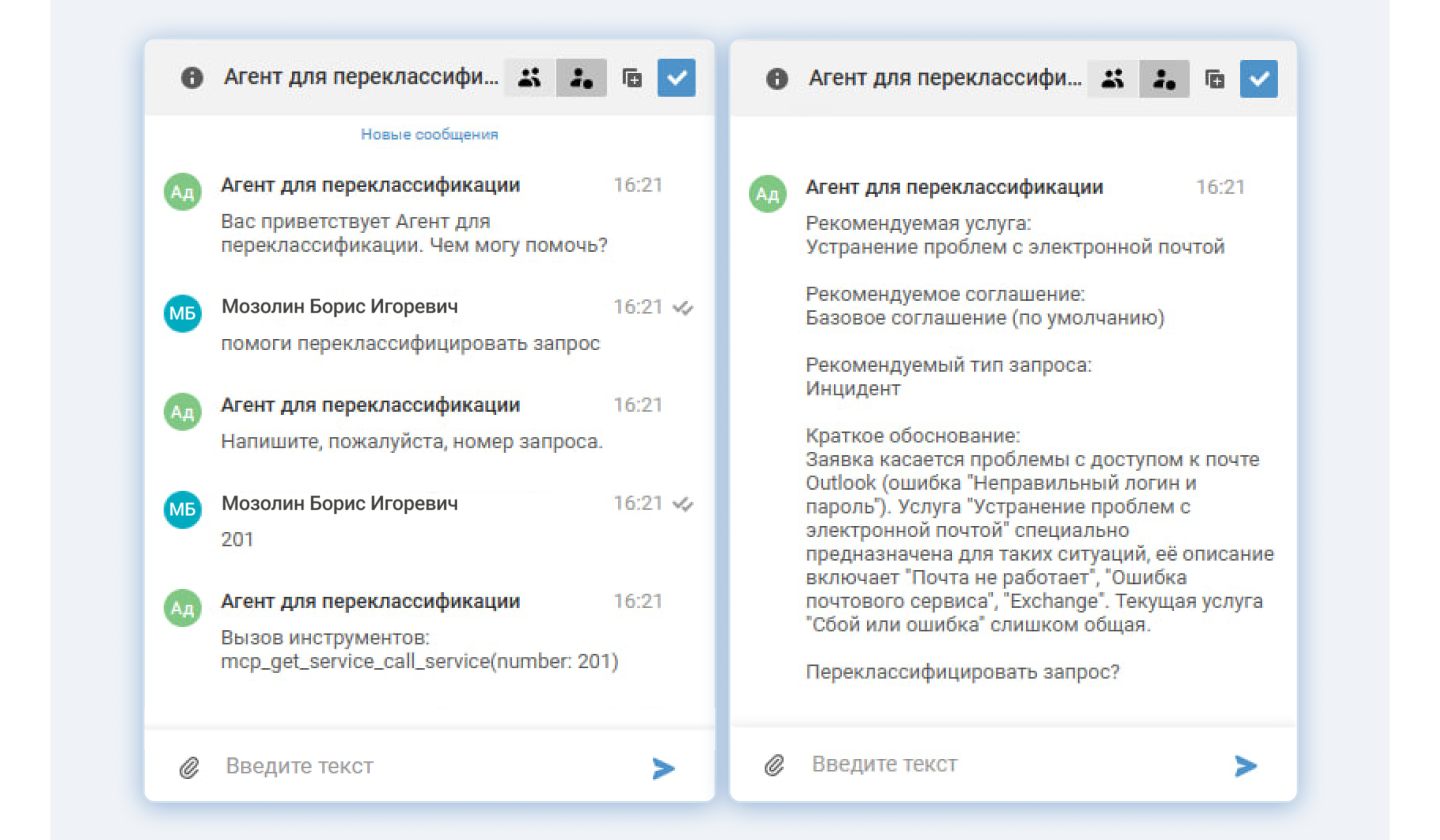
Агент анализирует заявку, определяет, что текущая услуга выбрана неверно, предлагает корректную услугу и тип запроса. Оператору остается подтвердить действие
Агент для суммаризации обращений
Что делает. Помогает оператору структурировать описание заявки: выделяет ключевой запрос клиента и инфраструктурное окружение, описывает действия клиента (пользователя) и выявленную им неисправность.
Этот агент незаменим для описаний, включающих множество деталей, которые создают «шум» и мешают понять суть проблемы. Кроме того, ИИ формирует список вопросов, которые рекомендуется задать заявителю на первом этапе работы. Это особенно полезно для кратких описаний, например, «Не работает принтер». Сформированная справка добавляется в комментарий к заявке, чтобы не затеряться в диалоге.
Результат. Снижается время анализа заявки, исключается риск пропустить важные детали. Оператор получает готовый список уточняющих вопросов.
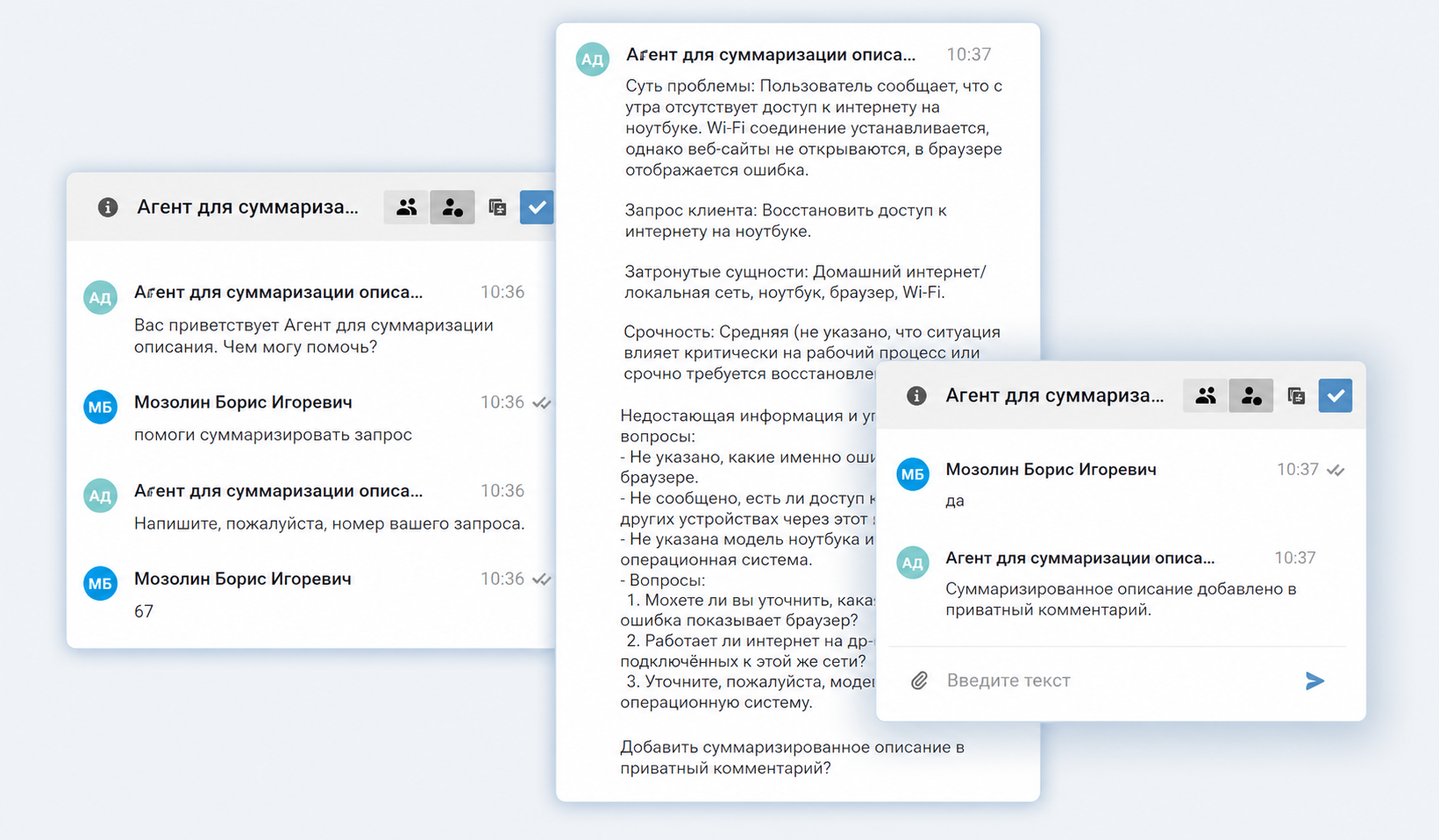
Агент формирует список уточняющих вопросов для заявителя, если информации недостаточно. Это позволяет оператору с первого раза запросить все данные, которые нужны для решения
Агент для формирования отчета о решении
Что делает. Изучает контекст заявки, анализирует комментарии, отсекает лишнее, выделяет относящееся к решению и формирует лаконичный структурированный отчет. Оператор может попросить агента добавить или убрать детали, после чего финальный вариант автоматически вставляется в поле «Отчет о решении».
Результат. Экономия времени на ручное написание отчета, формирование базы знаний на основе стандартизированных и детализированных ответов.
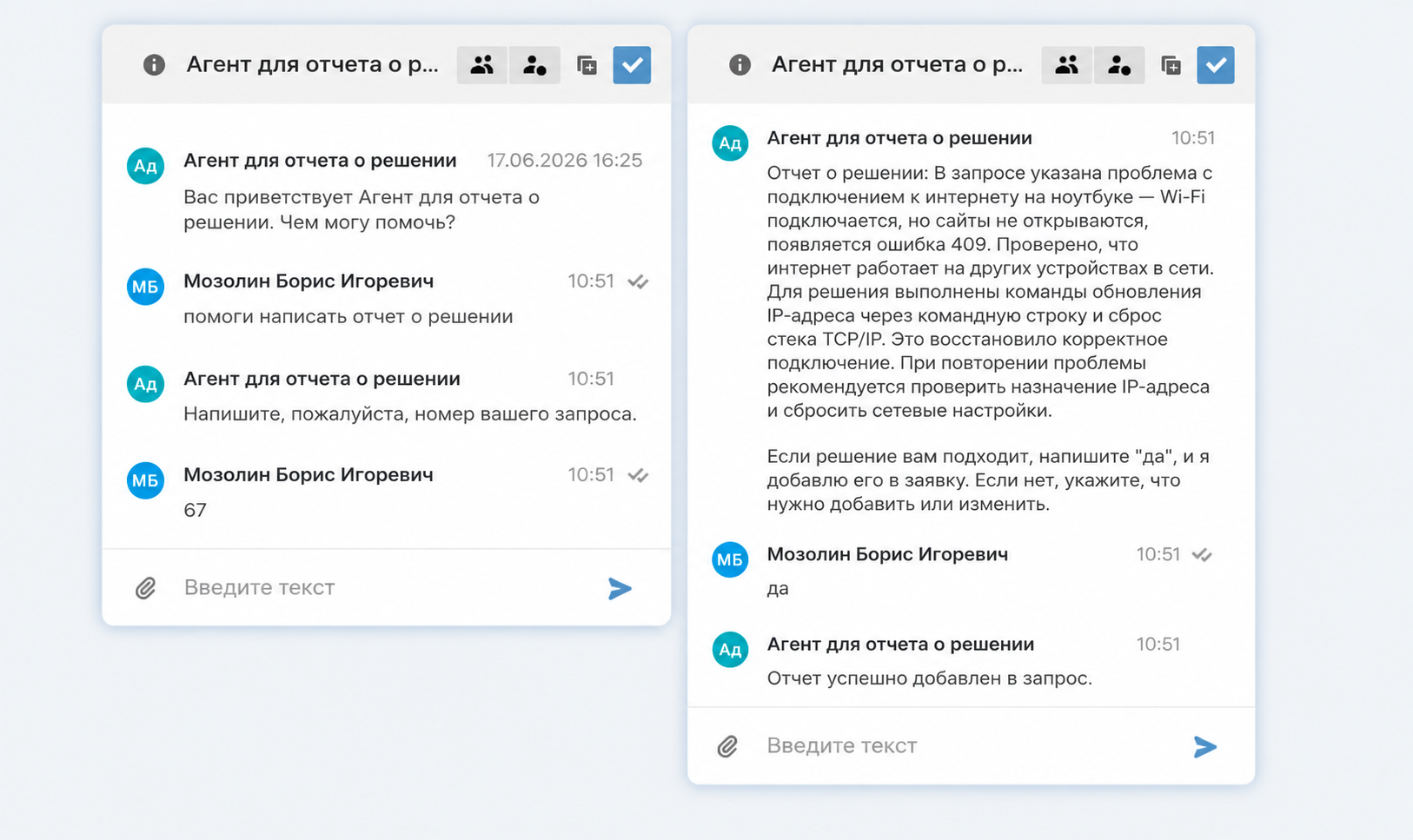
Агент для отчета о решении создает стандартизированный ответ на основе реальных действий оператора. Это помогает сформировать актуальную базу знаний
Безопасность и контроль AI в корпоративной среде
Интеллектуальная поддержка пользователей должна учитывать требования корпоративной безопасности. Внедрение
Naumen Service Desk включает несколько уровней контроля.
Поддержка закрытых и открытых контуров. Система работает как в средах с полным доступом к интернету, так и в изолированных закрытых контурах. Для
Разграничение доступа. Администратор настраивает, каким ролям и командам доступен каждый ассистент. Например, ассистент по внешним источникам — только для инженеров второй линии, а по знаниям — всей первой линии. Это предотвращает нецелевое использование ИИ и снижает риски ИБ.
Принятие решений с участием человека.
Снижение рисков галлюцинаций за счет RAG.
Ограничения и зоны ответственности. Качество ответов
Также в системе реализован инструмент по автоматическому пополнению базы знаний новыми источниками — например, когда закрывается массовый критичный инцидент.
Naumen Service Desk предлагает управленческую модель, в которой ИИ расширяет возможности оператора, но не исключает из процессов. Для бизнеса это означает, что инвестиции в ИИ дают измеримый операционный эффект: возможность обрабатывать больше обращений без роста штата и рисков для безопасности.
Бизнес-эффект внедрения AI в Service Desk
По данным практики внедрения Naumen, использование ИИ в управлении запросами и инцидентами дает следующие измеримые результаты.
Снижение времени обработки заявки на 20–50%. Экономия достигается за счет сокращения жизненного цикла заявки. Оператор с ассистентом тратит на одну заявку в среднем от 2 до 10 минут.
Уменьшение ошибок при классификации и маршрутизации на 80%. До внедрения ассистентов в среднем 25% заявок может переадресовываться между командами
Снижение количества повторных обращений на 10–30%. Эффект достигается за счет помощи агента по переклассификации, а также агентов по суммаризации описания и формирования отчета о решении.
Ускорение адаптации новых сотрудников до 5 раз. ИИ может выступать в роли тренера и консультанта. Новый оператор получает возможность быстро находить похожие решения, разбираться в процессе предоставления услуги и формировать корректный отчет без длительного обучения.
Ключевой
Перспективы развития AI в Service Desk
Следующий этап развития ИИ в системах типа Service Desk — распространение моделей на смежные процессы управления
В управлении проблемами ИИ способен анализировать потоки инцидентов, выявлять устойчивые паттерны и автоматически инициировать процесс по управлению проблемами. Это позволяет переходить от точечного устранения последствий к устранению коренных причин.
В гетерогенных
В мониторинге событий ИИ открывает возможности для предиктивной аналитики. Модели анализируют поступающие в Service Desk события, формируют предупреждения о потенциальной деградации сервисов до того, как пользователи заметят проблему. Кроме того, AI способен периодически анализировать накопленные события, выделять наиболее приоритетные из них и генерировать предложения по правилам нормализации.
Таким образом, ИИ в Service Desk постепенно эволюционирует от инструмента поддержки оператора до интеллектуального слоя управления
Главное
- Первая линия поддержки сталкивается с четырьмя типами операционных потерь, которые не устраняет базовая автоматизация. Например, это ошибки классификации, работа с неструктурированными данными, поиск в распределенных источниках знаний и ручное формирование отчетов. Такие потери увеличивают MTTR и создают скрытые затраты на доработки и повторные обращения.
- В Naumen Service Desk реализованы
ИИ-ассистенты и агенты. Любое их действие или рекомендация остаются под контролем оператора. Это не техническое ограничение, а осознанное решение, которое позволяет масштабировать поддержку без компромиссов по безопасности и риска ошибок. - Архитектура ИИ для службы поддержки учитывает два фактора: возможность работы в закрытых контурах и точность ответов за счет
RAG-пайплайна с утвержденными источниками. Таким образом качество работы ИИ пропорционально качеству базы знаний. Это переносит фокус с выбора LLM на поддержку корпоративных данных в актуальном состоянии. - Измеримый
бизнес-эффект достигается уже на текущих объемах нагрузки: снижение времени обработки заявок, ошибок классификации, повторных обращений, а также существенное ускорение онбординга первой линии поддержки.







