

Из внешних систем в зонтичный мониторинг приходит три типа данных — объекты мониторинга, события и метрики. В Naumen BSM обрабатывать эти данные помогают процессы автоинвентаризации оборудования, управления событиями и анализа метрик. В статье рассмотрим, что происходит на каждом уровне и какую ценность это дает в контроле состояния инфраструктуры.
Что такое уровни мониторинга
Naumen BSM включает три уровня зонтичного мониторинга. Они соответствуют трем потокам данных об инфраструктуре. Разберем, как и какие «сырые» данные поступают в систему.
С помощью готовых коннекторов либо настраиваемых механизмов интеграции система подключается к внешним источникам. Внешними источниками (ВИ) выступают, например, системы инфраструктурного мониторинга, системы виртуализации и другие решения для управления
В зонтичный мониторинг из ВИ поступают три типа данных: об объектах мониторинга, событиях и метриках. Далее эти данные обрабатываются, фильтруются и обогащаются, после чего используются на разных уровнях мониторинга.
Первый уровень: автоинвентаризация. Основан на инвентаризационных данных об объектах мониторинга. После обработки информация об оборудовании и виртуальных объектах автоматически наполняет и актуализирует систему учета инфраструктуры.
Второй уровень: управление событиями. На базе сообщений об изменениях в инфраструктуре рассчитывается здоровье оборудования, информационных систем и услуг, а также автоматически регистрируются инциденты.
Третий уровень: анализ метрик. Данные о показателях оборудования помогают контролировать текущее состояние инфраструктуры, обнаруживать отклонения, которые могут привести к сбоям, а также строить прогнозы метрик.
Каждый уровень дополняет предыдущий и создает отдельную ценность. Вместе они формируют комплексную картину о состоянии
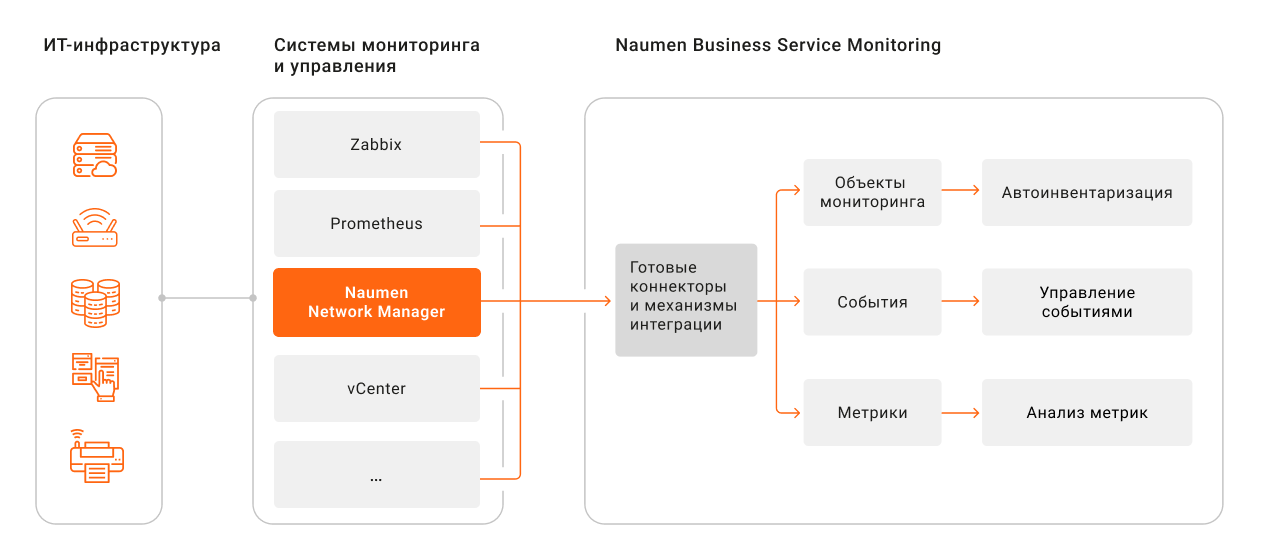
Потоки данных об ИТ-инфраструктуре в Naumen BSM
Уровень 1. Автоинвентаризация
Это процесс автоматической актуализации данных об оборудовании в CMDB. Работает это так. Naumen BSM подключается к внешним источникам, например, к системам инфраструктурного мониторинга. Внешние источники передают разные типы данных об
Сопоставление данных. На основе данных об оборудовании, которые поступают из внешних источников, в системе зонтичного мониторинга создаются объекты автоматической инвентаризации (ОАИ). Затем система обнаруживает соответствие между ОАИ и конкретной конфигурационной единицей (КЕ) в CMDB.
Обычно сопоставление происходит по набору атрибутов, таких как имя устройства,
Создание КЕ. Если при сопоставлении в CMDB не обнаруживается КЕ, соответствующая определенному устройству, то в Naumen BSM срабатывает логика создания конфигурационной единицы на основании данных ОАИ. Часть параметров система берет из ОАИ, например, имя устройства,
Автозаполнение недостающих атрибутов. Бывает, что данных из внешних систем недостаточно для заполнения КЕ. Например, для создания КЕ требуется знать ее тип (классификацию). Классификация КЕ может быть определена по модели устройства, сведения о которой приходят из ВИ. Если же модель в ОАИ не указана, применяются правила определения классификации. В них фиксируется, какую классификацию необходимо выбрать для различных типов ОАИ.
«Схлопывание» дублей. Допустим, система зонтичного мониторинга регистрирует несколько ОАИ, связанных с одним и тем же элементом инфраструктуры. Такое происходит, если объект контролируется несколькими системами: инфраструктурного мониторинга, управления или учета. При этом возникает конфликт данных, так как непонятно, значения из какого ОАИ нужно использовать для заполнения КЕ.
Для решения этого вопроса настраиваются правила приоритизации, основанные на весах атрибутов КЕ в разных внешних источниках. Таким образом, система заполняет атрибуты КЕ данными, имеющими наибольший приоритет. Например, характеристики «Тип ОАИ» или «Производитель» будут заполняться по данным из системы Zabbix, а остальные атрибуты — по данным, полученным из Naumen Network Manager.
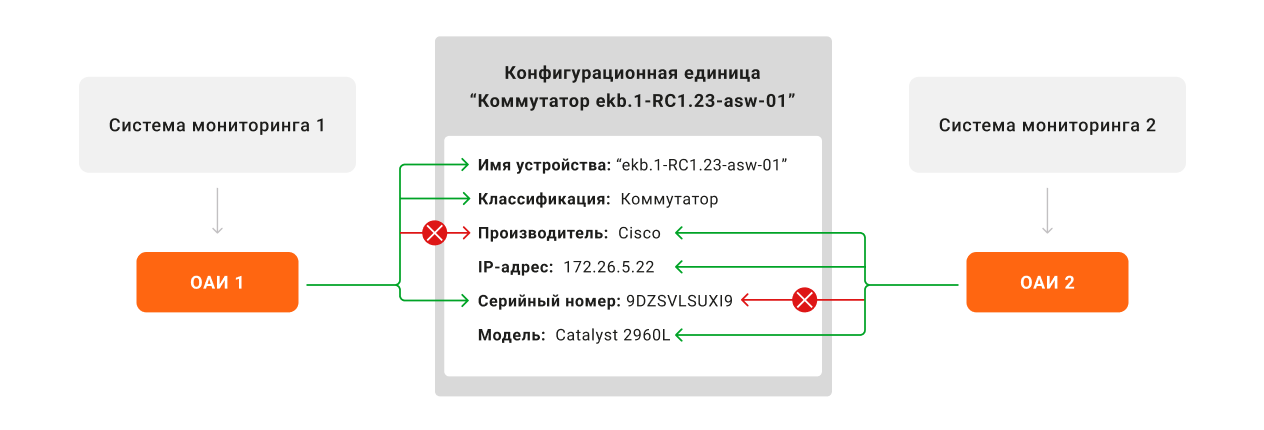
Определение веса значений параметров, полученных из разных внешних источников
Данные из различных систем мониторинга, поступившие в Naumen BSM, автоматически обрабатываются и передаются в CMDB. База данных оборудования поддерживается в актуальном состоянии, что является необходимым условием для эффективного управления инфраструктурой.
Уровень 2. Управление событиями
Событие — это сообщение об изменении, которое зафиксировала система инфраструктурного мониторинга. Процесс управления событиями заключается в непрерывном отслеживании происходящего в инфраструктуре, обнаружении критичных ситуаций и быстром реагировании на них.
В зонтичном мониторинге предусмотрены правила типизации и корреляции, с помощью которых обрабатываются события, а также запускаются механизмы реагирования. Например, в зависимости от ситуации система предупредит о необходимости провести профилактические работы или автоматически зарегистрирует инцидент.
Оценка влияния событий на оборудование. Каждая система инфраструктурного мониторинга использует свою классификацию событий. Аккумулировать «сырые» данные в зонтичной системе недостаточно. На их основе сложно сделать вывод, как влияет конкретное происшествие на работоспособность инфраструктуры и доступность сервисов.
Для обработки поступающих данных используются специальные правила. Они позволяют разделить десятки событий разных типов на основные группы. По умолчанию в Naumen BSM это «Отклонение», «Предупреждение», «Восстановление» и «Информация». Далее определяется ситуация, к которой можно отнести это событие, и анализируется степень влияния события на здоровье оборудования. Например, при регистрации события с типом «Отклонение» статус здоровья оборудования также будет определен как «Отклонение», а при поступлении «Информации» не изменится.
Оценка влияния событий на связанное оборудование и услуги. Также с помощью правил устанавливается, на какие элементы инфраструктуры и услугу влияет событие. Это позволяет оценить состояние не только самого оборудования, но и связанных с ним устройств и услуг.
Допустим, система зафиксировала проблемы с сервером. Устройство еще работает, но скоро может сломаться. Если сервер станет недоступен, то отключится виртуальная машина, развернутая на этом сервере. Еще пострадает почтовый сервис, то есть услуга «Электронная почта». Поэтому при статусе здоровья сервера «Предупреждение» в системе поменяется здоровье связанного оборудования и услуг, даже если по ним не зафиксировано никаких тревог.
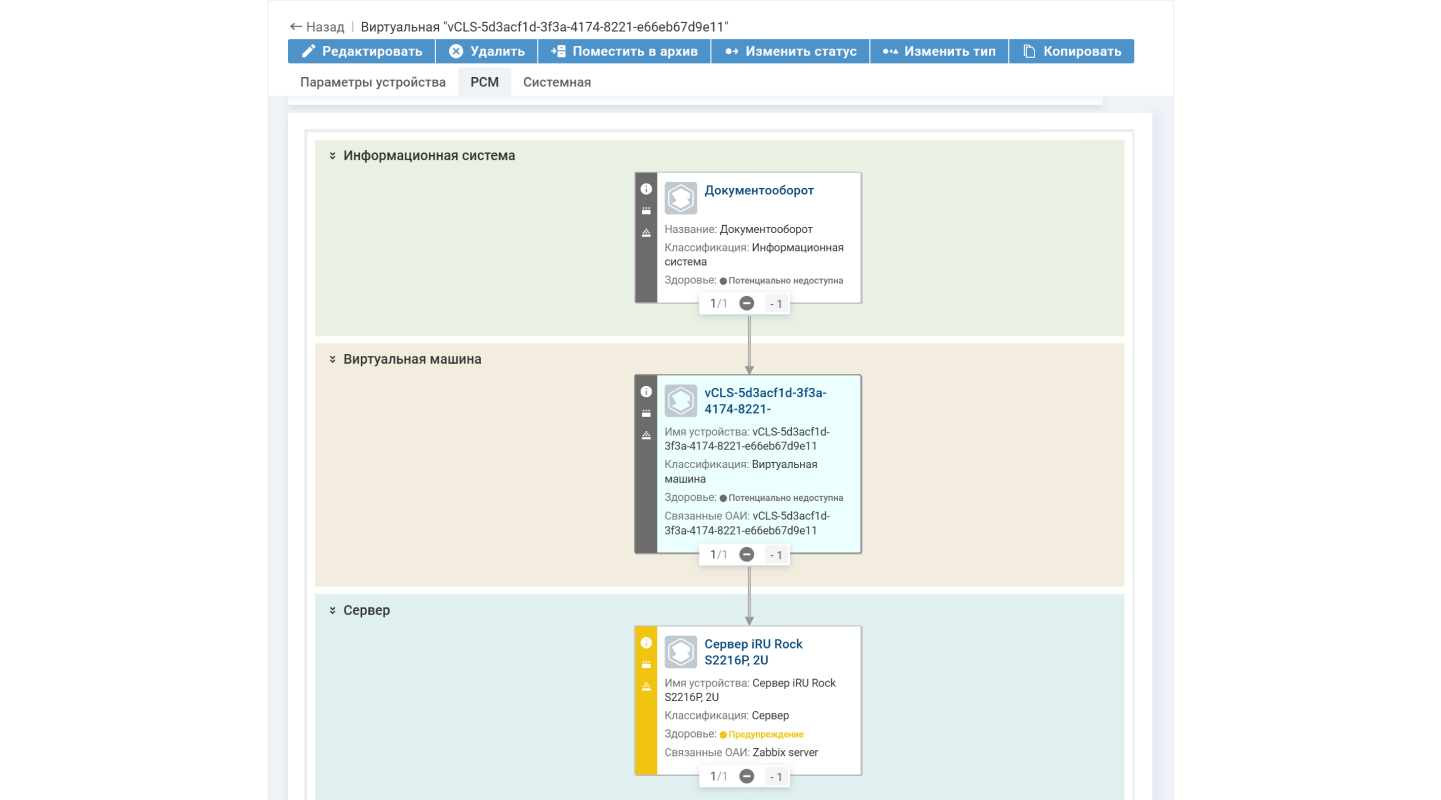
Для оценки влияния события на связанную услугу удобно использовать ресурсно-сервисную модель
Реагирование на события. События мониторинга оцениваются с точки зрения необходимости предпринять
Предотвращение шторма тревог. В зонтичном мониторинге предусмотрены настройки, которые позволяют установить, по каким событиям создавать инциденты и что делать, если в систему поступают повторяющиеся аварийные события по одной и той же конфигурационной единице.
Представим, что сервер вышел из строя. Системы мониторинга фиксируют аварийные события по связанным объектам до тех пор, пока не восстановится нормальная работа оборудования. В результате специалисты получат огромное количество уведомлений о сбое, устранением которого они уже занимаются. В зонтичном мониторинге можно настроить так, чтобы инцидент регистрировался только по первому событию, поступившему за
Таким образом, при управлении событиями с помощью Naumen BSM появляется возможность консолидировать данные об инфраструктуре. В системе автоматически создаются инциденты, предотвращается шторм тревог, контролируется здоровье оборудования и услуг.
Уровень 3. Анализ метрик
Метрики — это характеристики ОАИ, или иными словами — показатели оборудования. Naumen BSM агрегирует данные из разных систем инфраструктурного мониторинга, что позволяет в одном окне наблюдать состояние любого элемента инфраструктуры. Значения хранятся в виде временных рядов. Это дает возможность анализировать текущие показатели, отслеживать изменения с помощью графиков и дополнительных триггеров, прогнозировать метрики.
Здесь используются пассивные и активные метрики. Пассивные метрики — это показатели, собранные из внешних источников, например, из систем инфраструктурного мониторинга. Активные — показатели, которые настраивает пользователь и которые вычисляются с помощью скрипта.
Мониторинг доступности сервисов. Система позволяет контролировать показатели доступности различных сервисов. Например, с помощью метрики «Доступность сервиса» следить за работоспособностью корпоративных приложений, периодически выполняя проверку. В правила вычисления метрики необходимо прописать скрипт, который делает запрос к сервису, определяет его доступность и записывает ответ в метрику.
Создание обобщающих метрик. В скриптах описываются алгоритмы для агрегации различных метрик и вычисления средних значений на их основе. Например, задается активная метрика, чтобы контролировать определенный сегмент оборудования. Допустим, пользователю нужно контролировать работу не каждого отдельного сервера, а всего кластера. Настраивается скрипт, который вычисляет среднее значение загрузки центрального процесора на основании данных по пассивным метрикам «CPU Utilization» каждого сервера.
Контроль метрик конкретного ОАИ. В системе можно транслировать графики изменения нескольких метрик на одном дашборде. Информационная панель позволяет быстро оценить состояние оборудования, например, при расследовании инцидента. Набор метрик, которые выводятся на дашборд, настраиваются пользователем.

На общий дашборд можно вывести сразу несколько графиков метрик конкретного устройства
Добавление обобщенного триггера. Триггер — это механизм, который запускается, когда метрика достигает пороговых значений или выполняются более сложные условия, описывающие недопустимые состояния инфраструктуры. Если триггер сработал, система автоматически отправляет уведомление оператору мониторинга или регистрирует инцидент. Обобщенный триггер позволяет учитывать пороговые значения одновременно нескольких метрик.
Допустим, зонтичная система получает информацию о количестве сообщений в очередях Artemis из одной системы мониторинга. Другая система передает значения метрики «Свободное место на диске». Обобщенный триггер отслеживает и рост очередей, и объем доступного места на диске. Если триггер сработал, значит, система не успевает обрабатывать поток данных.
Есть способ исключить активацию триггера во время кратковременных пиковых нагрузок. Например, отложить запуск механизмов реагирования на тревогу на 10 минут. Триггер сработает, если нормальная работа систем не восстановится за это время.
Прогнозирование значений метрик. В Naumen BSM можно предсказывать значения метрик с помощью
Например, модель вычисляет, как будет меняться значение метрики «Свободная память в процентах» по определенному серверу. Дальность прогноза — 12 часов. Триггер настроен на значение «Ниже 60%». Если модель выявит, что пороговое значение будет достигнуто в прогнозируемом периоде, то триггер активируется и создается событие прогноза. И уже по этому событию регистрируется инцидент.
Таким образом, зонтичный мониторинг позволяет контролировать метрики, включая обобщенные показатели состояния инфраструктуры. Кроме того, прогнозы от
К выводам
В Naumen BSM можно выделить три уровня мониторинга — автоинвентаризация, управление событиями и анализ метрик. На каждом из них выполняются разные задачи, а вместе эти уровни помогают вести комплексный мониторинг инфраструктуры. Это дает возможность внедрить проактивный подход, обнаруживать сбои на ранних стадиях и минимизировать количество инцидентов.









