

В крупных и средних компаниях число систем мониторинга нередко доходит до десятков. Это классический пример разрастания инструментов и лоскутной автоматизации. Zabbix, Prometheus, Nagios, система мониторинга сети и серверов — каждое решение отвечает за свой фрагмент
При масштабировании такая архитектура создает проблемы: нет контроля инфраструктуры, появляется все больше слепых зон ИТ. В результате инструментов много, но все еще непонятно, что происходит с
В статье проанализировали причины разрастания систем мониторинга, экономические последствия фрагментации: потери от сбоев, деградация производительности оборудования. В качестве альтернативы рассмотрели платформенный подход к консолидации через зонтичный мониторинг
Как понять, что мониторинг IT вышел из-под контроля
Как распознать, что «зоопарк» решений для мониторинга больше не работает?
Есть три признака:
- Количество инструментов растет, а время восстановления сервисов не сокращается.
- Увеличиваются трудозатраты на ручное сопоставление данных из разных источников.
- Невозможно оценить влияние ИТ на бизнес. Специалисты не могут ответить, какие именно сервисы затронул сбой, сколько пользователей пострадало и какие
бизнес-процессы остановлены.
Ниже разбираем две группы причин, которые приводят к этой ситуации.
Историческое разрастание инструментов
С ростом компании множится и число решений для мониторинга. Одна система отвечает за серверы, другая — за базы данных, третья — за сеть, и они зачастую не связаны между собой.
Подобная лоскутная организация порождает проблему совместимости. Разрозненные системы мониторинга собирают метрики по-разному: Zabbix использует один протокол, Prometheus — другой. Специалисту приходится самим связывать события вручную, что ведет к дублированию функционала.
Также несколько систем мониторинга не решают проблему слепых зон. Допустим, в компании есть два ПО, которые отслеживают загрузку CPU, но ни одно не связывает оборудование с
Последствия импортозамещения
Уход западных вендоров с российского рынка после 2022 года привел к тому, что вместо одного решения компании вынуждены внедрять 2–3 отечественных. По данным исследований, треть компаний признают, что управление инфраструктурой критически усложнилось
Ситуация усугубляется тем, что около 60–70% экрупных заказчиков не могут себе позволить собственную разработку и выбирают готовые решения от разных производителей. При этом полностью заменить инфраструктуру на отечественные решения удалось лишь 11% компаний. Остальные работают в гибридной среде, где западные, российские и Open Source решения сосуществуют и требуют интеграции.
В результате интеграционный слой усложняется, а прозрачность
Почему классический мониторинг инфраструктуры не дает целостной картины
Системы в основном фиксируют техническое состояние оборудования, но не показывают влияние инцидента на
Отсутствие сквозной видимости между компонентами
Система регистрирует события, но не содержит сведений о
Например, на одном сервере отказал диск. Нагрузка перешла на второй, но он не выдержал. Начались
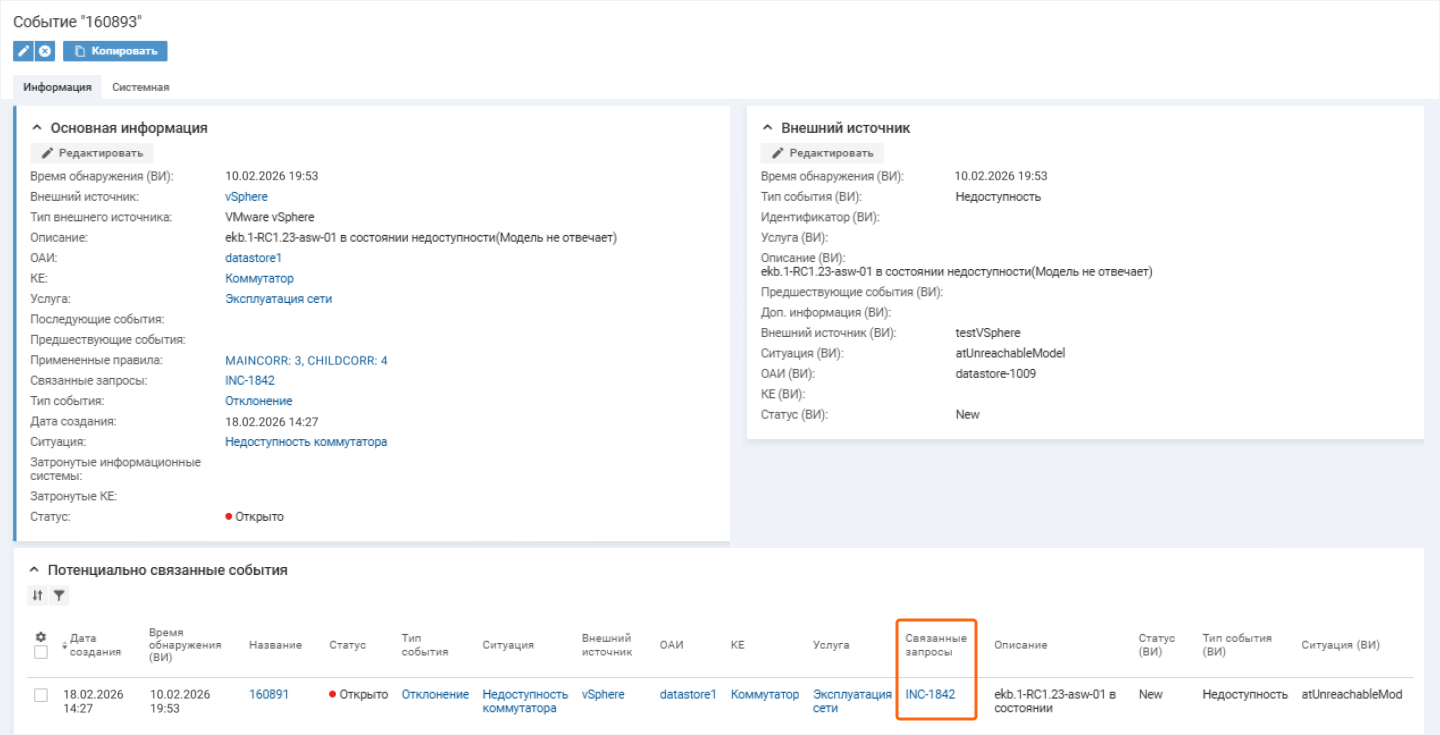
В отличие от базового, зонтичный мониторинг показывает событие, связанное оборудование и зависимые сервисы. Это позволяет проследить всю цепочку отказов
Наличие метрик при отсутствии контекста
Классические системы мониторинга ИТ оценивают состояние инфраструктуры на основе пороговых значений метрик. Превышение заданного порога генерирует алеpт, возвращение в норму — сигнал об устранении проблемы. Но происходит потеря контекста: инженер не знает, к какому сервису относится измеряемый параметр, является ли текущая нагрузка штатной или аномальной, влияет ли отклонение на доступность сервиса для пользователей.
Допустим, сервер может быть загружен на 100%, но если это плановая работа в разрешенное временное окно, такое состояние не является инцидентом. И наоборот, загрузка на 30% может сопровождаться превышением
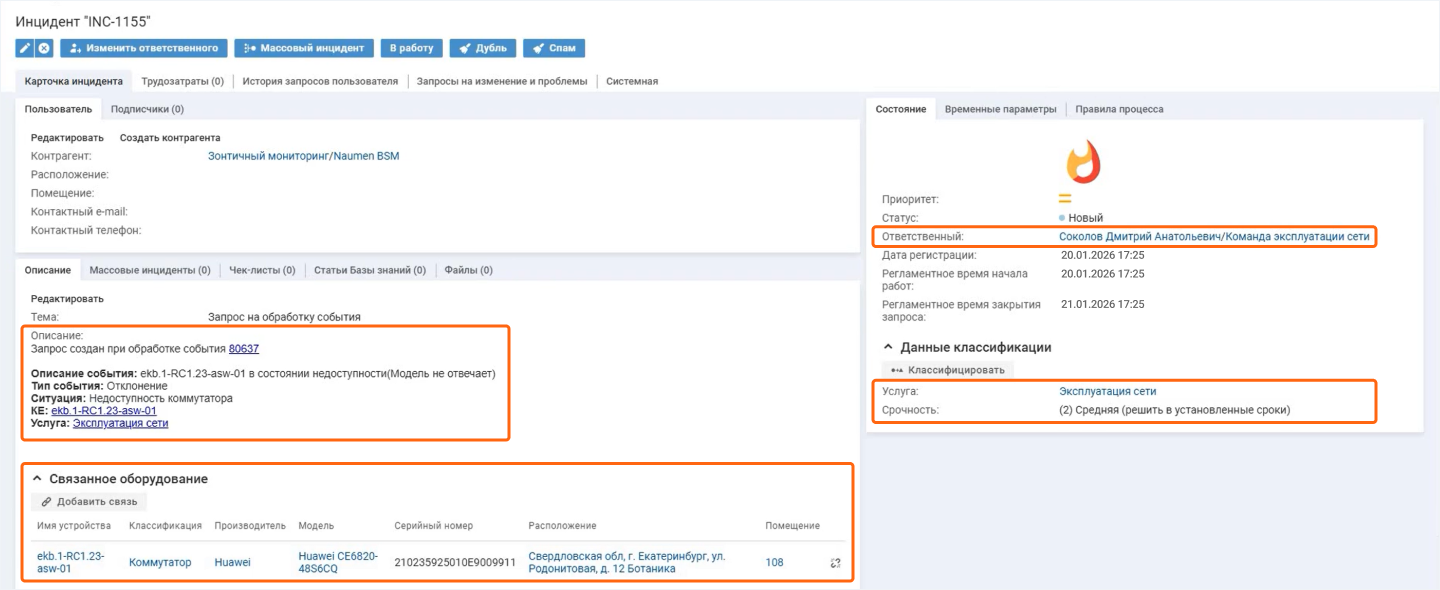
В отличие от классических систем, зонтичный мониторинг создает инцидент с полным контекстом: указывается услуга, оборудование, расположение. Инженер сразу видит, что именно затронуто и на что влияет сбой
Слепые зоны мониторинга
Отсутствие единой карты зависимостей приводит к тому, что каждая профильная команда располагает фрагментарной картиной. Например, при каскадном сбое, когда неисправность в одном компоненте порождает отказы в смежных, команды вынуждены последовательно исключать проблемы в своих зонах ответственности, обмениваясь уведомлениями и согласовывая действия. Время поиска первопричины возрастает и оказывает негативное влияние на выручку.
Экономика хаоса: сколько стоит беспорядок в данных
Фрагментация мониторинга и разрозненность данных об активах и сервисах приводят к росту затрат, прямым и косвенным финансовым потерям. Разберем три основных источника.
Деградация производительности сервисов как скрытая потеря
Сбои влияют на выручку не только в моменты полной остановки сервисов. Деградация производительности — замедление работы приложений, задержки в обработке транзакций, бездействие сотрудников в ожидании ответа системы — создает постоянный, но трудноизмеримый финансовый ущерб.
Например, простой одного сотрудника на 1 час в месяц при штате 500 человек дает потерю 250
Рост затрат при реактивном управлении
Пока инженеры вручную сопоставляют данные из разных систем мониторинга, время восстановления (MTTR) растет. Чем оно выше, тем существеннее прямые потери от сбоев и тем больше ресурсов требуется на устранение последствий. Несколько часов для компании с круглосуточными
Кроме того, реактивное управление порождает и скрытые потери выручки: сверхурочную работу инженеров, подключение дополнительных специалистов для управления инцидентами, простои смежных подразделений, ожидающих восстановления сервисов.
Ошибочные решения из-за фрагментированных данных
Без единой картины состояния
Как обрести контроль через Business Service Management и CMDB
Для перехода от классического мониторинга к управлению
Рассмотрим реализацию этих принципов на примере решения Naumen Business Service Monitoring.
От мониторинга устройств к управлению бизнес-сервисами
Ключевая идея BSM —
В BSM строится
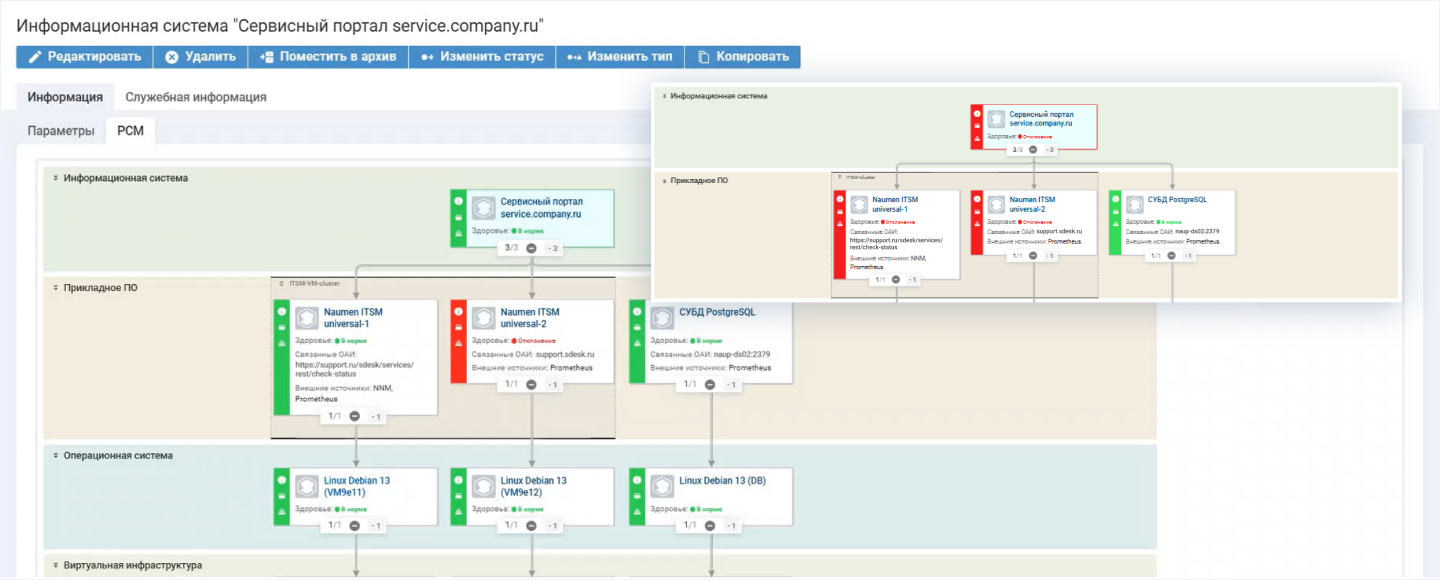
При сбое на устройстве система автоматически определяет, какие сервисы от него зависят и насколько критичен инцидент для бизнеса
Эффективность BSM напрямую зависит от точности и глубины построенных связей между элементами инфраструктуры и
- руководители ИТ и
топ-менеджеры оценивают доступность услуг, динамику событий и соблюдение SLA/SLO; - дежурные администраторы оперативно реагируют на неполадки;
ИТ-специалисты и администраторы услуг отслеживают состояние оборудования и открытые запросы;- менеджеры услуг контролируют показатели SLA/SLO и управляют приоритизацией инцидентов.
Визуализация делает сложные технические данные наглядными и понятными для всех категорий пользователей.
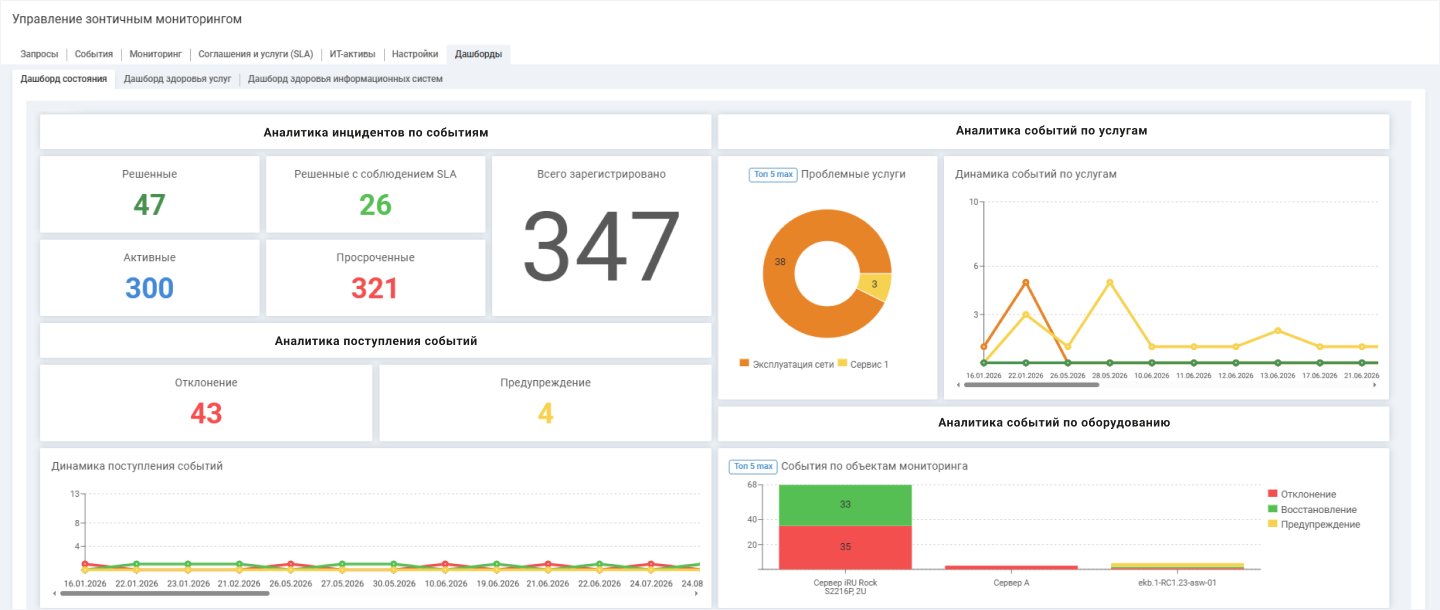
Дашборд руководителя показывает доступность услуги, динамику инцидентов и соблюдение SLA как ключевые метрики для управления ИТ-сервисами
CMDB и ITAM как единый источник контекста
Информацию о сбое и модель зависимостей можно получать сразу с оповещениями, если оборудование и ПО отображены в CMDB и системе управления
CMDB и мониторинг в связке с ITAM формируют единый контур управления
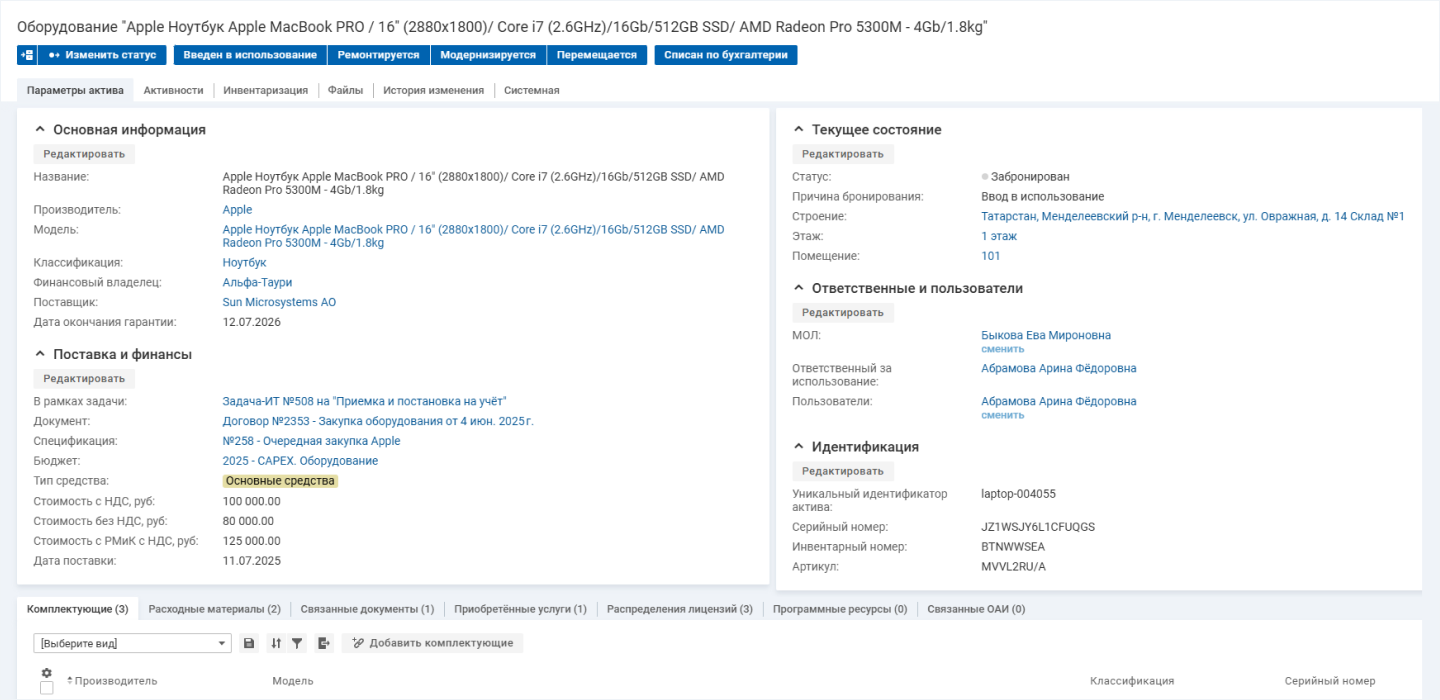
Из связки CMDB, ITAM и мониторинга оператор получает вместе с уведомлением о сбое: модель устройства, серийный номер, статус, ответственных, историю обращений и другую нужную информацию
Приоритет инцидентов по влиянию на бизнес
На основе данных из РСМ, CMDB и ITAM мониторинг бизнес-сервисов автоматически передает дальше инцидент в Service Desk с заполненным контекстом. В результате ресурсы ИТ сразу направляются на устранение сбоев. Это увеличивает эффективность управления
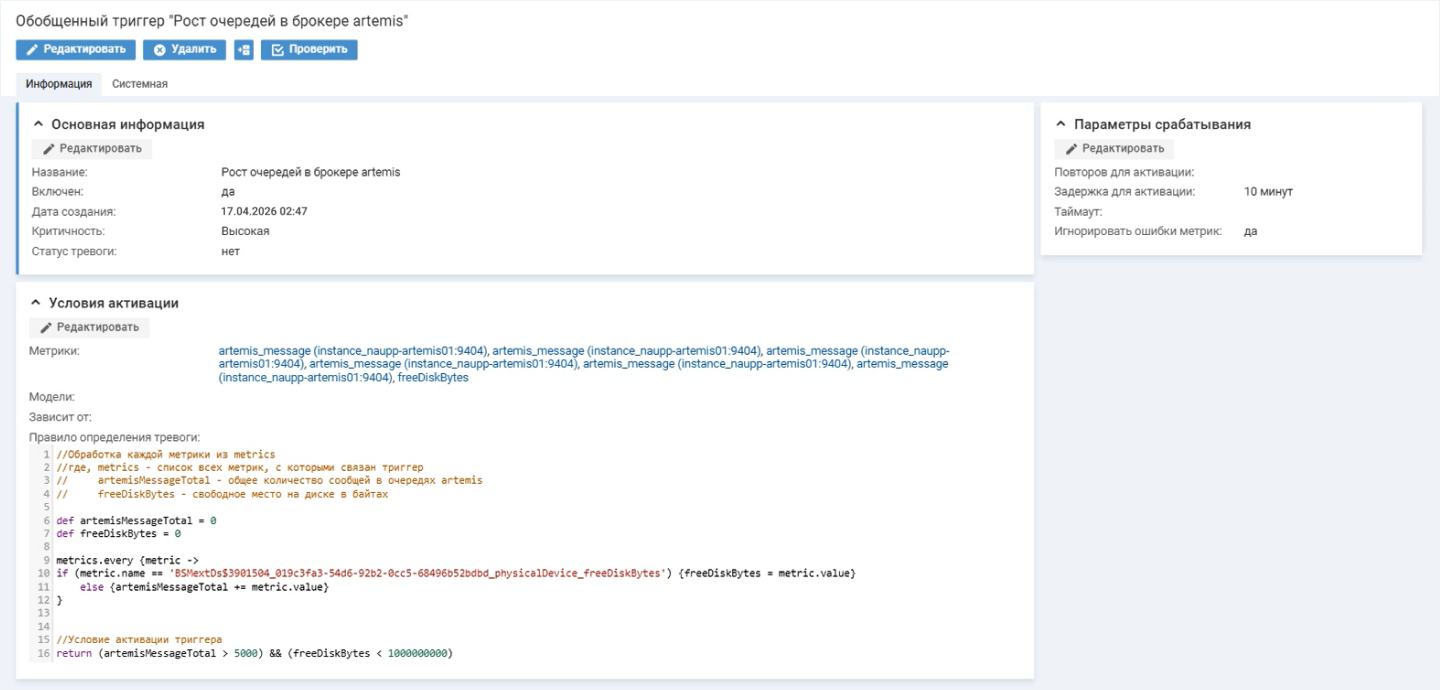
Триггер привязан не к единичному порогу, а к совокупности метрик. Это позволяет системе оценивать влияние на сервис и передавать для обработки в Service Desk
Платформенный подход: единое окно без отказа от старых систем
Наиболее распространенное возражение против консолидации мониторинга — наличие значительного числа действующих систем, единовременная замена которых невозможна. Решение — в платформенном подходе.
Интеграционный слой вместо тотальной замены
Зонтичный мониторинг разворачивается поверх действующих систем сбора логов, корневого мониторинга и иных источников данных.
В Naumen BSM для этой цели предусмотрены быстрые коннекторы. Достаточно указать реквизиты подключения, после чего автоматически формируются необходимые скрипты для сбора и обработки данных.
Интеграция мониторинга и ITSM работает по принципу триггера: когда порог превышен или сработало правило корреляции событий, зонтичный мониторинг автоматически создает заявку в Service Desk. В цифровой экосистеме продуктов Naumen обмен данными происходит бесшовно благодаря тому, что все системы базируются на
Единое окно мониторинга
Вместо множества окон Naumen BSM предлагает одно для всех событий (single pane of glass). Для пользователей настраивается объем информации, соответствующий задачам, без избыточной технической детализации.
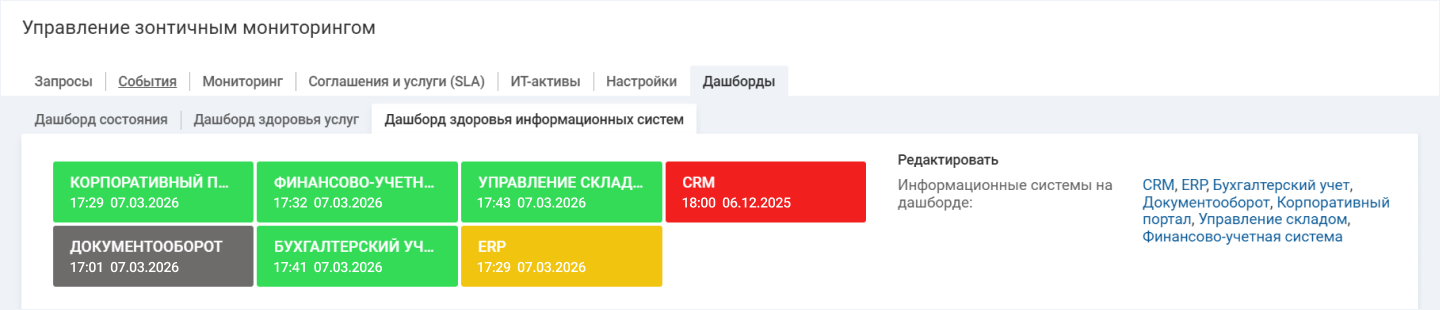
На дашборде здоровья пользователь видит только состояние ИТ-сервисов. При необходимости можно перейти в РСМ и посмотреть детали
Поэтапная консолидация без рисков
Внедрение платформенного подхода не требует замены всех действующих цифровых решений. Рекомендуемая последовательность действий выглядит так:
- Аудит существующих систем мониторинга.
- Выбор критичных
бизнес-сервисов для пилотного проекта. - Настройка интеграций через коннекторы.
- Построение
ресурсно-сервисной модели для выбранных сервисов. - Масштабирование на новые сервисы и источники данных.
Единая система мониторинга позволяет получить измеримый результат на пилотных сервисах и поэтапно расширять охват без остановки действующих систем.
Сравним классический и платформенный мониторинг.
| Классический мониторинг | Платформенный подход | Ручной анализ алертов и переключения между разными системами | Единое окно мониторинга, которое отражает агрегированные события и связь с сервисами |
| Приоритеты расставляет менеджер услуги или инженер | Система автоматически рассчитывает приоритет реагирования по влиянию на бизнес |
| История активов хранится в отдельных системах, бумажных журналах | Полная информация о любом |
| Решения по закупкам и инвестициям принимаются реактивно, после массовых сбоев | Руководство отслеживает затраты, простои и метрики, решения принимаются по |
Консолидация мониторинга, например, на базе Naumen BSM позволяет перейти от фрагментарного обзора к управлению ИТ через единую модель «ресурсы — сервисы — бизнес». Поэтапная консолидация начинается с аудита и пилотного проекта на критичных сервисах, что дает измеримый результат без остановки действующих систем.
Итогом внедрения платформы мониторинга становится единый контур управления ИТ: от ручного поиска связей к прогнозируемому и экономически обоснованному контролю
Переход от мониторинга инфраструктуры к управлению цифровым ландшафтом: главные тезисы
- Разрозненные инструменты мониторинга ИТ не делают управление
ИТ-инфраструктурой прозрачнее. Часто компании годами наращивают количество ПО, но время восстановления сервисов только растет, а бизнес не видит связей между техническими проблемами и расходами. - Благодаря РСМ каждую конфигурационную единицу получится привязать к конкретному сервису. Так приоритет инцидента будет определяться на основе влияния на бизнес.
- Единая платформа мониторинга работает как интеграционный слой поверх существующих систем и не требует их замены. Она аккумулирует данные из всех действующих систем мониторинга, баз знаний, CMDB, ITAM и ITSM, объединяя их все в едином окне.
- Внедрение такой системы стоит организовать поэтапно. Например, провести аудит, запустить пилот на критичных сервисах, затем масштабировать на весь
ИТ-ландшафт .








