

Artificial Intelligence for IT Operations (AIOps) — это подход к управлению
В статье — как AIOps меняет управление
Почему AIOps стал естественным этапом развития наблюдаемости
С 2025 года на российском рынке
Рассмотрим этапы эволюции
Переход от базового мониторинга к observability. Такой мониторинг всегда отвечал на вопрос «что сломалось?» и требовал заранее заданных порогов для метрик. Наблюдаемость добавила контекст: метрики, логи, трассировки и события начали собираться в единую картину, позволяя понять «почему сломалось».
Отказ от ручного анализа. Количество алертов в крупных инфраструктурах измеряется тысячами в день. Зачастую инженеры тратят до 50% времени на фильтрацию ложных и некритичных срабатываний и поиск корреляций. В результате специалисты физически не успевают обрабатывать такие потоки данных в реальном времени. Для этого эффективнее использовать автоматизацию.
Построение связей в инфраструктуре. Когда количество оборудования и ПО растет, увеличивается и количество взаимосвязей между компонентами. Традиционные системы мониторинга их не видят, а человек не в состоянии запомнить все. В этом случае надежным инструментом становится автоинвентаризация с ИИ.
Будущее ИТ-операций — за автоматизацией сбора и анализа данных. В дальнейшем корректная работа с информацией процессов открывает возможность прогнозировать сбои до возникновения.
Как работает AIOps: принципы и архитектура
Применение AIOps преобразует данные об
Платформа. AIOps реализуется на базе системы зонтичного мониторинга и
Сбор данных. Мониторинг принимает данные в реальном времени: события, метрики, трассировки, топологию. Они поступают из систем наблюдения, логов, APM и CMDB.
Исторический анализ.
Автоматизация. Отвечает за управление инцидентами, зависимостями и изменениями. На основе результатов анализа метрик система инициирует выполнение скриптов, ранбуков и процедур автоматического восстановления.
Интеграции. Платформа интегрируется с
Каждый элемент архитектуры AIOps связан с другим. Базовое условие эффективности — качественная работа с данными. Без нее невозможно ни обучение моделей, ни автоматизация.
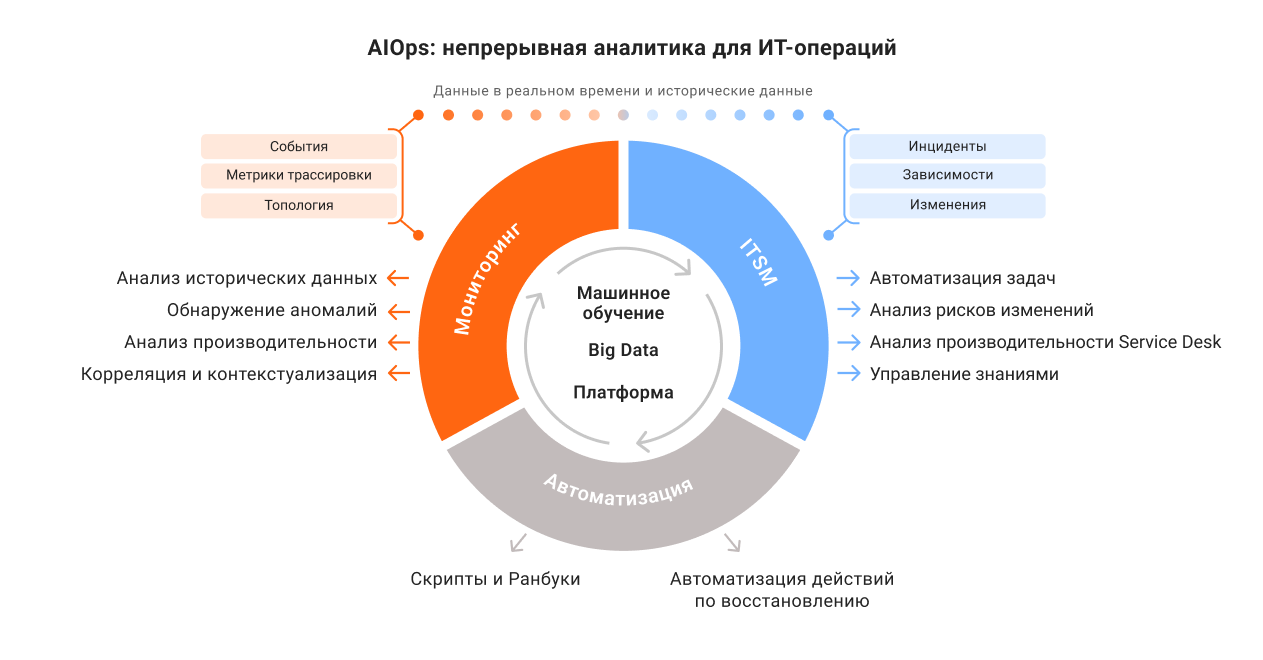
AIOps превращает разрозненные события, метрики и трассировки в автоматизированные сценарии восстановления ИТ-инфраструктуры
Какие данные использует AIOps
AIOps объединяет данные из различных источников — журналов событий, тикетов и CMDB. Здесь учитываются и исторические, и текущие значения метрик, что позволяет анализировать конкретные ситуации и выявлять долгосрочные тренды.
| Тип данных | Источники | Для чего используется |
| Логи | Системные журналы, логи приложений, | Фиксация последовательности событий, выявление ошибок, анализ причин сбоев, поиск скрытых смыслов в неструктурированных данных |
| Метрики | Системы мониторинга (Zabbix, Prometheus, Azure Monitor), APM-решения | Оценка производительности (загрузка CPU, память, время ответа), прогнозирование нагрузки, обнаружение аномалий временных рядов |
| Взаимодействие | Онлайн во многих каналах | Онлайн и офлайн для взаимодействия непосредственно в месте возникновения потребности |
| События | Оповещения систем мониторинга, алерты, изменения конфигурации, действия администраторов | Корреляция связанных событий, построение карт |
| Трассировки | Системы распределенной трассировки (Jaeger, Zipkin), APM | Отслеживание пути запроса через микросервисы, выявление проблемных мест и задержек, анализ взаимозависимостей компонентов |
| Тикеты | Service Desk, |
Анализ истории инцидентов, выявление повторяющихся проблем, автоматизация эскалации и назначения ответственных |
| CMDB | Системы управления конфигурациями | Предоставление контекста: связи между компонентами, информация об активах, версиях, владельцах сервисов, построение |
В дальнейшем нормализация и обогащение этих данных контекстом позволяет строить точные
Примеры использования AIOps для бизнеса
Применение AIOps затрагивает различные сценарии управления инфраструктурой — от автоматизации
Обнаружение инцидентов
Пример. На сайт билетного агрегатора в 4 утра пришелся пик аномального трафика. Модель предсказания временных рядов определила, что текущие значения превышают прогнозные, и зафиксировала аномалию, которая оказалась
Поиск первопричин
AIOps коррелирует события из разных источников, строит карты зависимостей и автоматически определяет наиболее вероятную причину инцидента.
Пример. При недоступности сервера система сопоставляет события и выявляет, что за минуту до этого отключился сетевой коммутатор. Инженер получает не просто сообщение «сервер не работает», а конкретную причину — отсутствие питания на линии.
Оптимизация ресурсов
Чтобы распределить ресурсы, ИИ собирает историю нагрузки и прогнозирует потребность. На основе прогнозов система автоматически масштабирует вычислительные мощности.
Пример. ИИ прогнозирует рост пользовательской активности на время распродажи в
Предиктивное обслуживание
Пример. Система прогнозирует, что свободное место на сервере закончится через 48 часов, и автоматически создает заявку в Service Desk с приоритетом «средний» и рекомендацией по очистке или расширению тома.
Улучшение UX
ИИ анализирует данные о пользовательских сессиях, времени отклика интерфейса и частоте ошибок. При выявлении аномалий система предлагает или автоматически применяет корректирующие действия.
Пример. ИИ фиксирует рост времени ответа API для пользователей из определенного региона и автоматически переключает трафик на менее загруженный кластер, предотвращая массовые жалобы.
Преимущества AIOps: 5 изменений в работе ИТ-инфраструктуры
Базовый принцип AIOps — увеличение результата при сохранении или снижении затрат. По данным OpsRamp, 74%
Выделим основные
- Сокращение времени простоя сервисов за счет проактивного управления.
ML-модели , обученные на исторических данных, прогнозируют инциденты, нагрузку и потребность в ресурсах. 58%ИТ-специалистов отмечают предупреждение аномалий как ключевую функцию. - Ускорение поиска корневых причин (RCA). ИИ в реальном времени анализирует телеметрию и разнородные данные, указывая источник проблемы. 48% респондентов OpsRamp считают это основным преимуществом AIOps.
- Сокращение расходов на ИТ. При том же штате специалисты обслуживают в 2 раза бóльшую инфраструктуру. Среднее повышение производительности труда в кейсах вендоров — около 60%. Инженеры переключаются с рутины на развитие сервисов.
- Повышение производительности систем. Обученные модели прогностической аналитики быстрее выявляют и устраняют проблемы с производительностью.
- Устранение «усталости от оповещений». AIOps коррелирует связанные алерты и фильтрует низкоприоритетные уведомления. Инженеры перестают тратить время на ручной отбор и тонуть в оповещениях.
Внедрение AIOps приносит множество экономических преимуществ и полностью меняет вектор работы
Корректно оценить пользу технологии помогут метрики эффективности AIOps.
| Метрика | Описание | Ожидаемая динамика |
| MTTR | Среднее время восстановления после сбоя | Снижение — до 90% для автоматизированных инцидентов |
| MTTD | Среднее время обнаружения инцидента | Снижение |
| False Positives | Количество ложноположительных срабатываний | Снижение |
| Alert Noise Reduction | Объем подавленных избыточных алертов | Рост |
| SLA/SLO | Доля выполненных соглашений об уровне сервиса | Рост |
| Uptime | Доступность систем | Рост |
| RCA Time | Время анализа корневой причины | Снижение |
| Productivity | Обслуживаемая инфраструктура на штатную единицу | Рост в 2 раза и более |
Важно учесть, что ROI AIOps рассчитывается не только через снижение затрат, но и через улучшение клиентского опыта. Компания с качественным сервисом приносит в 5,7 раз больше дохода, чем конкуренты, отстающие в обслуживании.
Внедрение AIOps: этапы и ошибки
Внедрение AIOps — это крупный и сложный проект, который меняет фундаментальные
Рассмотрим этапы внедрения AIOps:
- Сбор и агрегация данных. Определяются источники: системы мониторинга, логи, системы управления инцидентами, APM, базы знаний и другие. Они подключаются к системе зонтичного мониторинга.
- Очистка и нормализация данных. Удаляются дубликаты, унифицируются названия атрибутов, данные обогащаются контекстом (сервис, среда, версия). Без этого этапа модели ML будут обучаться хаотично.
- Анализ и корреляция событий. Для установления связи между событиями используются правила и
ML-алгоритмы кластеризации. Например, если в офисе не работает интернет, ИИ проверяет другие события и видит, что за минуту до этого маршрутизатор в серверной перезагрузился. - Обучение моделей на реальных данных. Модели обучаются для обнаружения аномалий, прогнозирования инцидентов и настройки алертов под конкретную инфраструктуру и
бизнес-процессы компании. - Автоматизация
IT-операций . Создаются сценарии для типовых инцидентов: автоматическое масштабирование подов, перезапуск сервиса, создание тикета, отправка уведомления в нужный канал и другие. Сценарии запускает триггер. - Циклическое переобучение для повышения точности.
ИТ-инфраструктура постоянно меняется. Поэтому организуется регулярное переобучение моделей на свежих данных с учетом обратной связи от инженеров.
Следует отметить, что без системного подхода к сбору данных и обучению моделей инвестиции в AIOps не дают измеримого результата. Поэтапное внедрение технологии позволит перестроить

Системный план внедрения AIOps показывает, как превратить данные в самообучающиеся модели
На каждом этапе внедрения AIOps возможны ошибки. Подсказываем, какие они могут быть и как их избежать.
Ошибка 1. Переоценка зрелости
Ошибка 2. Подбор моделей и алгоритмов без предварительного сбора и оценки качества данных. ИИ обучается на искаженных сведениях, не распознает сезонные паттерны и аномалии, нет четких правил типизации и корреляции событий.
Ошибка 3. Нет переобучения моделей. В этом случае точность не растет, доверие к системе падает.
Ошибка 4. Нет пилотного проекта. В попытке реализовать сразу множество сценариев команда перегружена настройками, интеграции работают нестабильно, измеримый результат отсутствует.
Ошибка 5. Игнорирование регуляторных требований. Автоматическое изменение конфигураций может привести к блокировке системы, особенно в финансовом секторе и государственных организациях.
Ошибки внедрения AIOps возникают при нарушении последовательности этапов. Например, попытка автоматизации процессов без собранных данных, масштабирования без пилотного проекта, обучения моделей без накопленной истории. Соблюдение порядка «от простого к сложному» — главное условие получить измеримый результат и доказать пользу технологии для бизнеса.
Уровни зрелости AIOps
Модель зрелости AIOps — это фреймворк для оценки текущих возможностей компании в области AIOps и построения дорожной карты для постепенного улучшения. Она описывает, насколько глубоко ИИ и ML применяются в
Существует 4 стандартных уровня, на основе которых оценивается зрелость.
| Возможности | Трудности | Экономический эффект | |
| 1. Базовый мониторинг | 1. Реагирование на случившийся сбой. 2. Разрозненные процессы с высокой долей ручных операций, минимальная автоматизация. 3. Данные и операции разрознены по разным командам и инструментам. |
Частые простои, медленное устранение инцидентов | Потери от простоев, неэффективное использование времени инженеров, неконтролируемые операционные расходы |
| 2. Реактивный AIOps | 1. Улучшенный мониторинг с централизацией и лучшей интеграцией данных. 2. Автоматические оповещения для спрогнозированных проблем. 3. Начальное использование RCA для управления инцидентами. |
1. Интеграция данных нестабильна. 2. Возможности прогнозирования ограничены. 3. Зависимость от ручного вмешательства остается значительной. |
Снижение затрат на ручную обработку алертов, сокращение времени простоя за счет быстрой диагностики |
| 3. Проактивный AIOps | 1. Автоматическое обнаружение инцидентов. 2. Развертывание 3. Прогнозирование инцидентов и проблем с производительностью. 4. Автоматический анализ корневых причин. |
1. Обеспечение качества данных, интеграция продвинутых аналитических инструментов, оптимизация процессов автоматизации. 2. Интеграция разнородных источников данных, поддержание точности моделей, непрерывное совершенствование прогностических возможностей. |
Предотвращение простоев до возникновения, освобождение инженеров для более сложных задач, влияющих на прибыль |
| 4. Автономный AIOps | 1. Инфраструктура способна обнаруживать и диагностировать проблемы, инициировать устранение неисправностей и оптимизировать производительность без ручного вмешательства. 2. Нормализация, синхронизация и контроль качества данных из разнородных источников (legacy, облака, on-premise, SaaS) без ручных доработок. 3. Команды переориентируют свои усилия на долгосрочное планирование и оптимизацию. Это обеспечивает автономное реагирование, долгосрочную масштабируемость и бесшовный пользовательский опыт. |
1. Постоянное изменение 2. Проблемы, связанные с пользовательским опытом и 3. Регуляторные ограничения в финансах, госсекторе и КИИ — автоматические изменения конфигураций без участия человека могут нарушать требования. |
Минимизация человеческого участия в рутинных операциях, снижение операционных затрат. ИТ работает как драйвер |
Переход от базового мониторинга к автономному AIOps предполагает последовательное снятие ограничений: ручных операций (2), реактивного управления (3), зависимости от человека при типовых инцидентах (4). На всех уровнях ключевыми факторами остаются качество интеграции данных и доверие к автоматизации.
Экономический эффект возрастает нелинейно: основной прирост происходит на этапе перехода от реактивного к проактивному уровню за счет предотвращения простоев. Автономный уровень минимизирует операционные затраты, но требует от бизнеса готовности отдать ИИ критический контроль за
Как понять, что вашей компании нужен AIOps
Потребность в AIOps возникает по мере накопления операционных проблем, которые перестают решаться масштабированием штата или добавлением новых инструментов мониторинга. Ниже — признаки того, что текущая модель управления
В компании используются гибридные среды. Это разные комбинации
«Зоопарк» инструментов мониторинга. Одновременно действуют несколько систем мониторинга: Zabbix, Prometheus, Grafana и другие. Каждая собирает данные в своем формате, консолидация отсутствует.
Количество уведомлений об инцидентах превышает возможности команды на их обработку. Более 30–40% алертов — ложные или низкоприоритетные. Инженеры привыкли игнорировать оповещения или тратят время на ручную фильтрацию.
Время диагностики инцидентов (MTTD) растет. Поиск корневой причины сбоя занимает часы, а иногда дни. Данные разрознены по системам, инженер вынужден вручную переключаться между дашбордами, логами и трассировками. Отсутствует единый контекст по инциденту.
Повторяющиеся сбои не анализируются. Схожие инциденты возникают регулярно, но каждый раз их расследование начинается с нуля. Потери времени на повторную диагностику одних и тех же проблем составляют десятки часов в месяц.
Снижается качество
Затраты на поддержку растут быстрее инфраструктуры. Увеличение числа инженеров в службе эксплуатации опережает рост самой инфраструктуры. Команда решает операционные проблемы и почти не занимается профилактикой и развитием. Бюджет ИТ увеличивается, но измеримого улучшения сервисов не происходит.
При наличии трех и более признаков из списка внедрение AIOps становится необходимостью для контроля операционных затрат и выполнения SLA.








