

Контроль инфраструктуры — основная задача руководителя
В системе зонтичного мониторинга Naumen Business Service Monitoring (BSM) реализованы дашборды
Как изменился подход к визуализации ИТ-данных
На развитие инструментов визуализации влияет стремление пользователей не просто использовать статичные данные на дашбордах, а обновлять в режиме реального времени:
- получать подсказки, на что обратить внимание;
- видеть прогнозы;
- без перенастройки фильтров менять значения и смотреть, как это сказывается на ситуации.
Посмотрим, как эти тенденции отражаются на ключевых задачах контроля
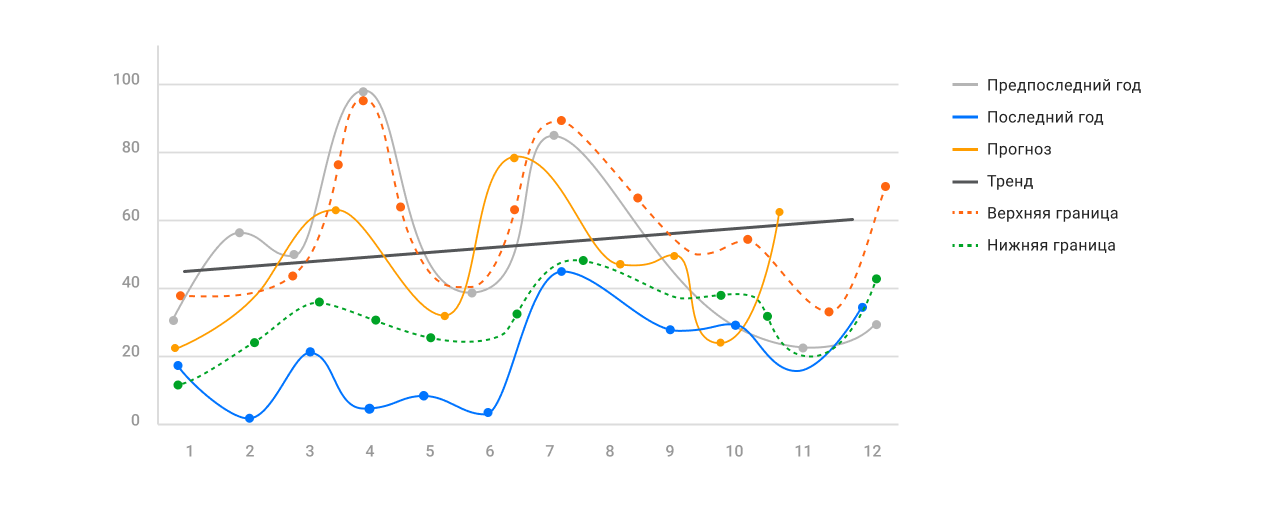
Прогнозирование. Ранее прогнозы строились на базе линейной экстраполяции. Сейчас
При визуализации они выглядят как динамические коридоры неопределенности. Виджет содержит не одну прогнозную линию, а спектр возможных значений — «веер» из прогнозов на графике. Например, оптимистичный, базовый или критический сценарии поведения метрик.
Еще одна возможность, которая получила развитие в контексте прогнозирования — интерактивное моделирование. Прямо на графике можно изменить линию
Выявление аномалий в реальном времени. До недавнего времени отклонения определяли по метрикам, вышедшим за настроенные пороговые значения. По факту большинство из них критичными не являлись, так как нарушение правила — далеко не всегда аномалия. В результате специалисты разбирались с множеством алертов, которые не стоили внимания и ресурсов. В свою очередь
Отражением этого стал интерактивный граф
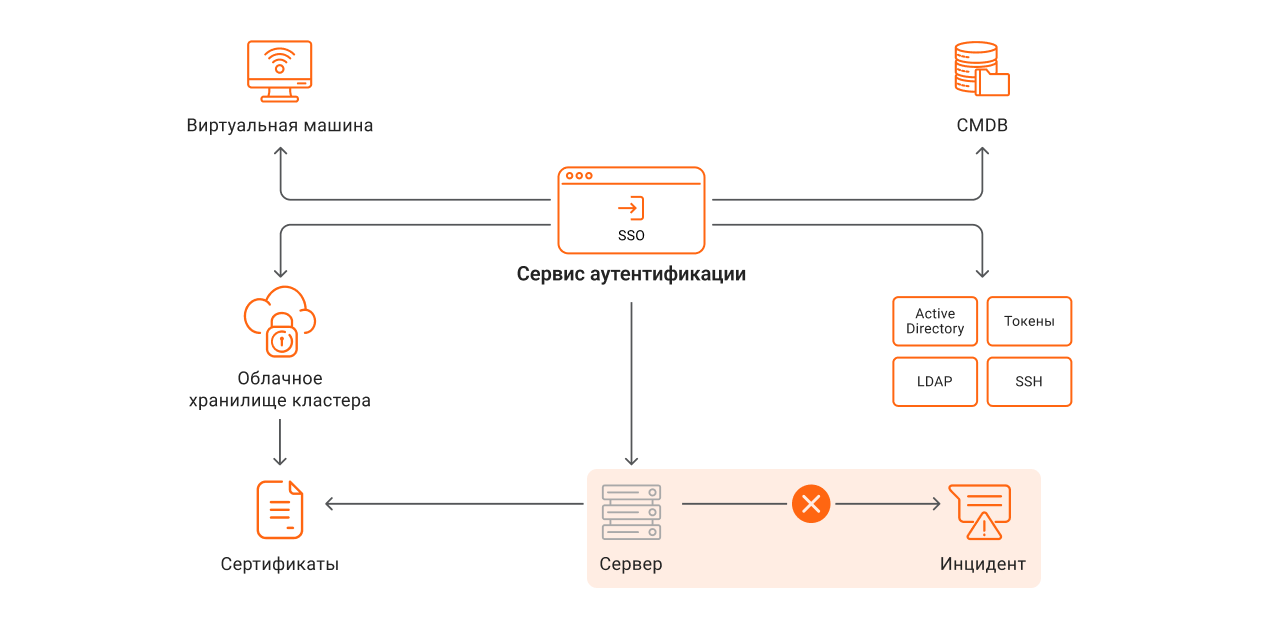
Связь с бизнесом. Мониторинг
Сложность в том, что эта связь неочевидна. Средства визуализации решают эту проблему, автоматически пересчитывая одни величины, понятные только
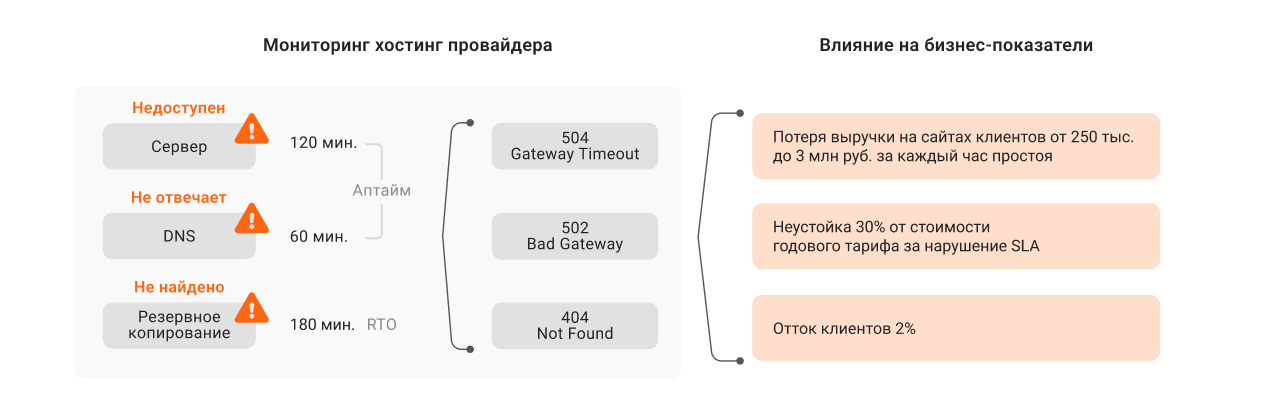
Единое окно для всех ролей. Зачастую «сырые» данные из систем корневого мониторинга умеют корректно интерпретировать только
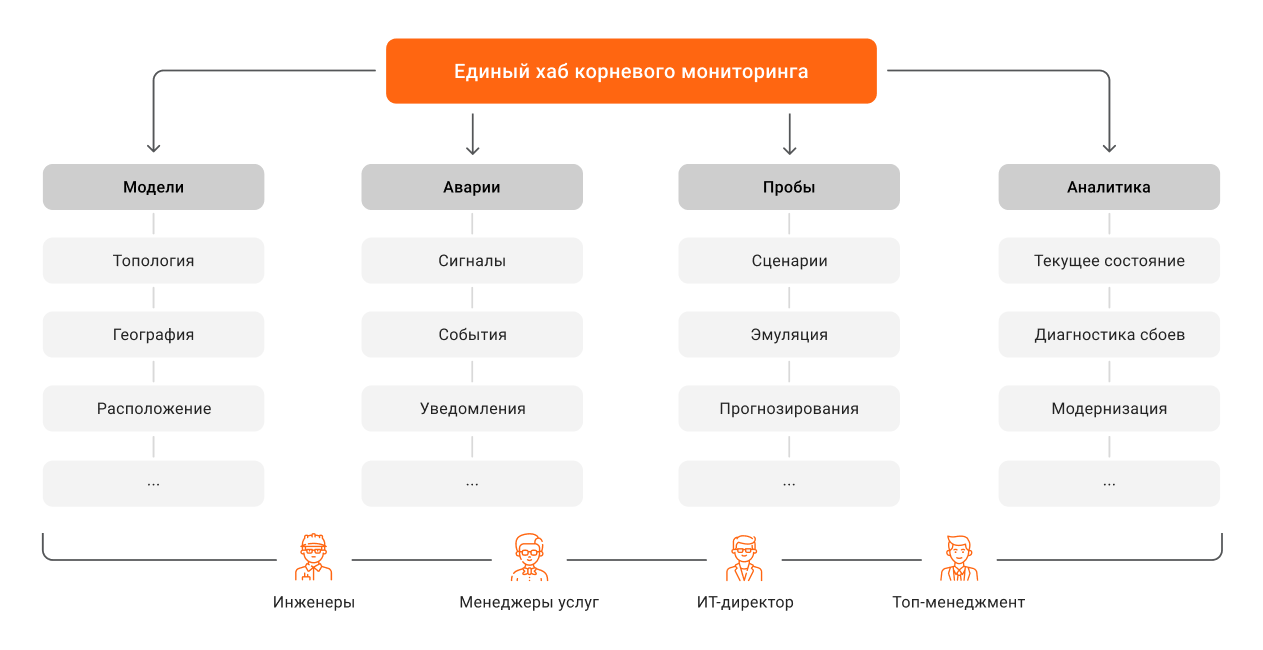
Кому какие дашборды нужны: матрица ролей
Приведем примеры возможных дашбордов для разных специалистов, участвующих в управлении
| Роль | Что в зоне ответственности | Какой дашборд будет полезен |
|---|---|---|
| Дежурные операторы | Физическая и виртуальная инфраструктура
Сетевая связность и каналы Базы данных и СУБД |
Метрики «железа»: загрузка CPU, очередь процессов, объем занятой оперативной памяти, заполненность дисков, нагрев процессора, скорость вращения кулеров и др.
Сеть: пропускная способность каналов, потеря пакетных данных, статус портов коммутаторов СУБД: число активных сессий, медленные запросы, статус репликации Схемы топологии сети, архитектурные карты |
| Ответственные за оборудование из службы эксплуатации | Работоспособность конкретных технологических стеков
Утилизация и износ «железа» Замена комплектующих и поддержка вендоров |
Все необходимые данные по группам объектов, за которые отвечают конкретный специалист:
● метрики оборудования; ● жизненный цикл; ● число и история инцидентов |
| Владельцы |
Доступность и качество Соблюдение SLA/OLA Жизненный цикл сервиса |
Время бесперебойной работы сервиса, длительность простоев
Число заявок в техподдержку относительно сервиса Нарушения SLА Число повторяющихся проблем Таймлайн доступности сервиса Здоровье сервисов |
| Руководитель |
Стабильность и работоспособность Управление инцидентами и изменениями Соблюдение SLA техподдержкой |
Инциденты: число открытых, среднее время устранения (MTTR/MTTA)
Статистика затронутых инцидентами объектов инфраструктуры Изменения: соотношение успешных релизов и нереализованных задач Трудозатраты специалистов техподдержки и эксплуатации, нагрузка на персонал |
| Специалист по информационной безопасности | Защита периметра и данных
Обнаружение угроз и атак Соответствие регламентам, правилам, требованиям |
Число выявленных и заблокированных атак
Подозрительная сетевая активность Обнаруженные уязвимости по степени критичности Неавторизованные попытки входа |
| Директор направления информационных технологиий | Стратегия и бюджет ИТ
Риски и непрерывность бизнеса Эффективность инвестиций |
TCO инфраструктуры и отдельных составляющих
ROI Доступность ключевых Индекс кибербезопасности Количество критических инцидентов за месяц Тренды затрат, верхнеуровневые воронки потерь |
Несмотря на то, что каждому из этих специалистов нужна своя информация, им не требуются разные решения. Достаточно системы зонтичного мониторинга с возможностью индивидуальных настроек для пользователей.
Дашборды для оперативного контроля услуг
Рассмотрим, как в системе Naumen BSM можно отслеживать состояние
Здоровье критичных бизнес-услуг
Кому подойдет — руководителям
Что выводится на дашборд — услуга, цветовой индикатор состояния, дата и время изменения состояния. Из любой услуги можно перейти на
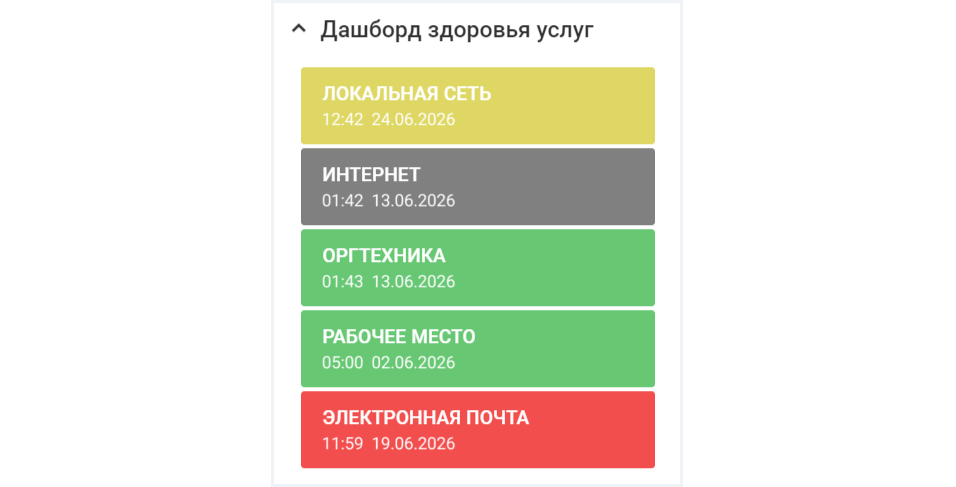
Состояние услуги отображается с помощью цвета
Такой дашборд позволяет сразу понять, какие услуги требуют внимания и срочных мер:
- Зеленый — услуга доступна. Все
ИТ-ресурсы , влияющие на нее, работают в штатном режиме. - Красный — услуга недоступна. В
ИТ-структуре обнаружены вышедшие из строя объекты, которые напрямую влияют на работу услуги. - Желтый — предупреждение. Зафиксировано событие,
из-за которого оборудование может выйти из строя, но пока работает. - Серый — услуга потенциально недоступна, то есть неизвестно, повлияла ли поломка оборудования на работу услуги.
В системе можно организовать контроль
Здоровье большого количества услуг
Для контроля инфраструктуры важно не только понимать состояние каждой услуги, но и оценивать картину в целом.
Кому подойдет — дежурным администраторам, которым необходимо отслеживать состояние множества услуг онлайн.
Что выводится на дашборд — перечень услуг и их состояние с помощью цветового кодирования.
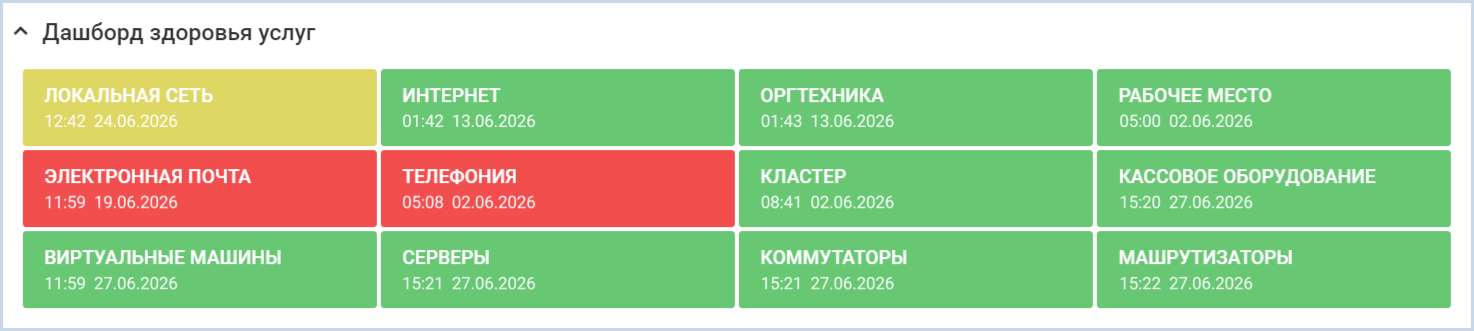
Цветовое кодирование позволяет быстро считать информацию о здоровье услуг и вычленить проблемные
Здоровье поддерживающих услуг
Эти услуги обеспечивают жизнедеятельность компании. Например, к ним относятся сетевые сервисы, вычислительные платформы, базовое ПО.
Кому подойдет —
Допустим, администратор отвечает за работу коммутаторов, от которых частично зависит доступность интернета. Сама услуга «Интернет» в зоне компетенции другого специалиста. Администратор следит только за состоянием услуги «Сетевое оборудование», поэтому будет получать уведомления о работе коммутаторов из системы мониторинга, а при возникновении инцидента устранять поломку оборудования.
Что выводится на дашборд — название и состояние поддерживающей услуги, дата обновления состояния, активные события. Например, отклонение, предупреждение, восстановление.
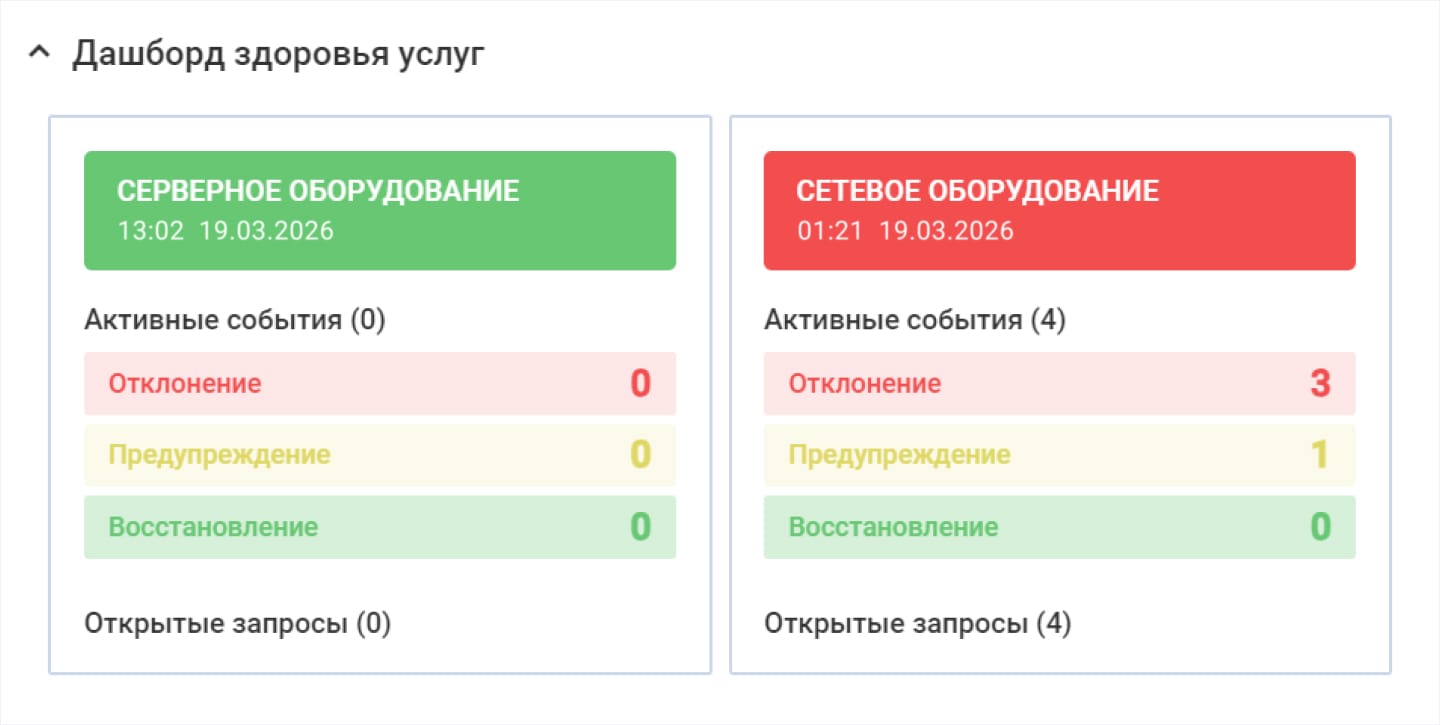
Для услуг выводится список связанных событий, на каждое из которых можно кликнуть, чтобы получить подробности
Аналитические дашборды: контроль состояния услуги в динамике
Контролировать состояние услуги на уровне «работает — не работает» не всегда достаточно. Для более детального мониторинга сервисов и аналитики
Кому подойдет — менеджерам услуг, чтобы отслеживать статистику событий и инцидентов в различных разрезах.
Что выводится на дашборд — детальная статистика по услуге. Например, количество инцидентов, скорость восстановления, какие сотрудники устраняли поломки. Дашборд консолидирует статистику по обращениям через
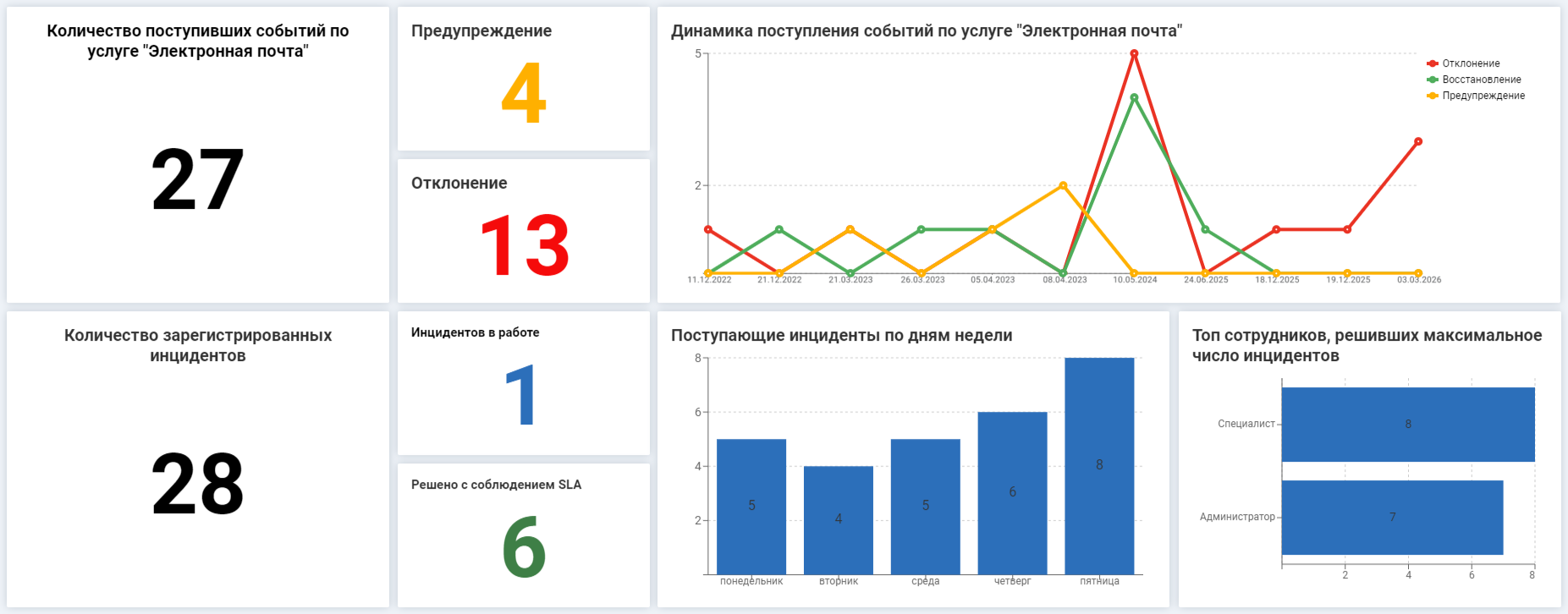
Этот дашборд позволяет оценить доступность услуги, состояние инфраструктуры и работу команды
Рассмотрим подробнее. «Количество поступивших событий», «Предупреждение», «Отклонение» — сколько критичных событий по услуге зарегистрировано системой мониторинга. Дашборд помогает оценить состояние поддерживающей инфраструктуры. Так, большое количество негативных событий и инцидентов зачастую говорит об износе оборудования.
«Количество зарегистрированных инцидентов», «Инцидентов в работе», «Решено с соблюдением SLA», «Топ сотрудников с максимальным решенным числом инцидентов» — насколько загружена команда и как справляются специалисты. Например, аналитика инцидентов показывает, что большинство из них команда устраняет с нарушением SLA. Значит, сотрудники не успевают в установленный срок, а услуга простаивает слишком долго. Следовательно, нужно разобраться в причинах и принять меры: перераспределить ресурсы, пересмотреть SLA или заменить часто ломающееся оборудование.
Дашборды для анализа состояния ИТ-инфраструктуры
Для эффективного мониторинга
В нем агрегируется вся необходимая информация о состоянии инфраструктуры и работе отдела с детализацией событий.
Кому подойдет — руководителям
Что выводится на дашборд — события мониторинга, текущее состояние ИТ, включая статистику по событиям. Сведения разделены на блоки:
- Общая статистика по событиям — сколько зарегистрировано событий за конкретный период.
- Аналитика событий по услугам — какие услуги чаще всего страдают, топ-5 проблемных услуг.
- Аналитика событий по оборудованию — какое оборудование чаще всего ломается.
- Аналитика по инцидентам.
Рассмотрим подробнее.
Общая статистика по событиям
На этом дашборде данные группируются по всем событиям, поступающим из инфраструктуры.
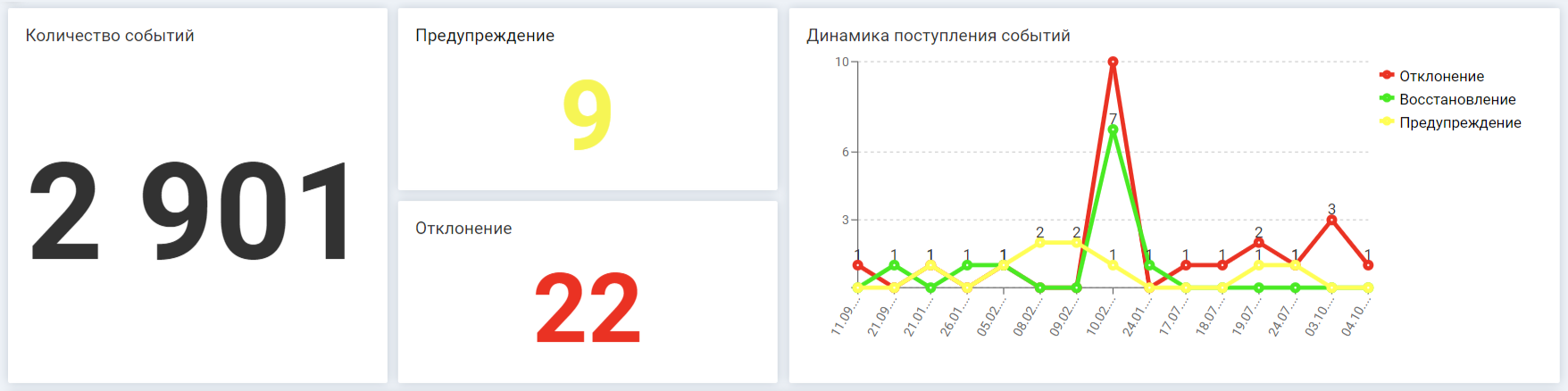
Сигналы классифицируются по типам и при клике на каждый можно получить детальную информацию
Количество событий — общая статистика поступивших событий за период.
Отклонение — число событий, где триггер сработал в системе мониторинга, из которой далее данные поступили в систему зонтичного мониторинга.
Предупреждение — число событий в системе мониторинга, которое сигнализирует о возможном срабатывании триггера.
Динамика поступления событий по типам и датам — показываются не только «плохие» события (отклонения и предупреждения), но и «хорошие» — восстановление работоспособности.
События могут связываться не только с выходом оборудования из строя (отклонением). Например, если настроить триггеры на изменение показателя в системе зонтичного мониторинга, то события будут группироваться по типам «Предупреждение» и «Отклонение». Например, когда показатель «Свободное место на диске» = 0 — это отклонение. А когда «Осталось 20%» — это предупреждение. Место на диске еще есть, и пока все работает, но скоро могут возникнуть проблемы.
Так на графике виден всплеск по отклонениям: 10 событий зафиксированы в один день. Возможно, они произошли по одной причине. Кроме того, график показывает, что команда успешно справилась с большинством сбоев.
Аналитика событий по услугам
Здесь показано, как события в инфраструктуре влияют на бизнес и в каком состоянии находятся услуги.
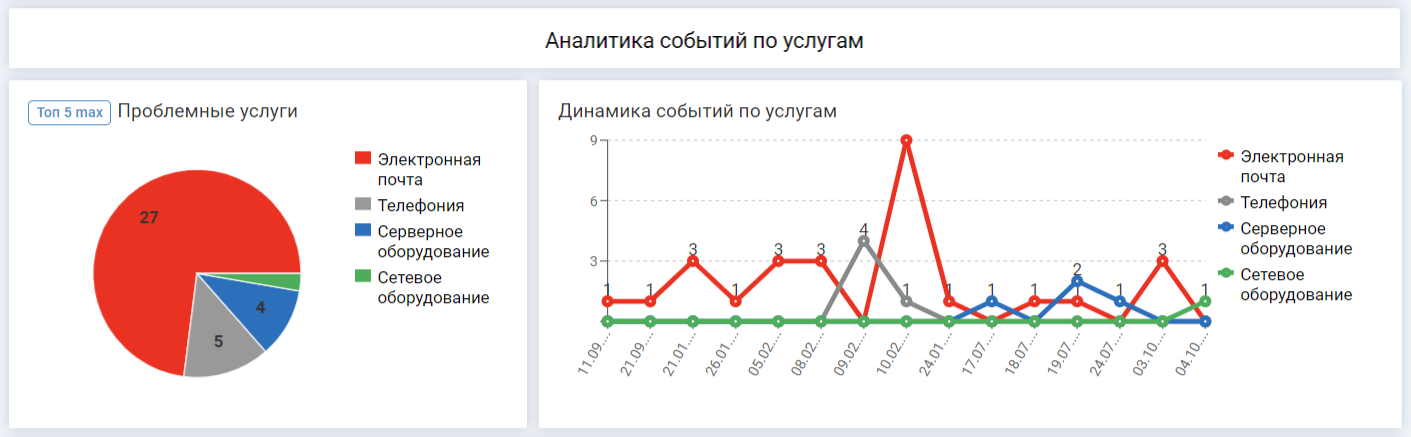
На дашборде видно, какие услуги нестабильны, и их состояние за определенный период
«Топ-5 проблемных услуг» — рейтинг формируется по числу инцидентов, созданных на основе событий, которые приходятся на каждую услугу за период.
«Динамика событий по услугам» — в какие дни происходили события. Эти данные понадобятся для анализа причин.
На диаграмме видно, что первые места занимают услуги «Электронная почта» и «Телефония». По ним произошло больше всего событий. Судя по графику, значительная часть сбоев по услугам зафиксирована в один день. Известно, что в тот момент не работала услуга «Интернет». Скорее всего, события по указанным услугам спровоцированы внешними факторами.
Аналитика событий по оборудованию
Дашборд показывает слабые места в инфраструктуре. С учетом дополнительных данных можно определить, какие поломки вызваны внешними факторами, а какие — перегрузками или износом оборудования.
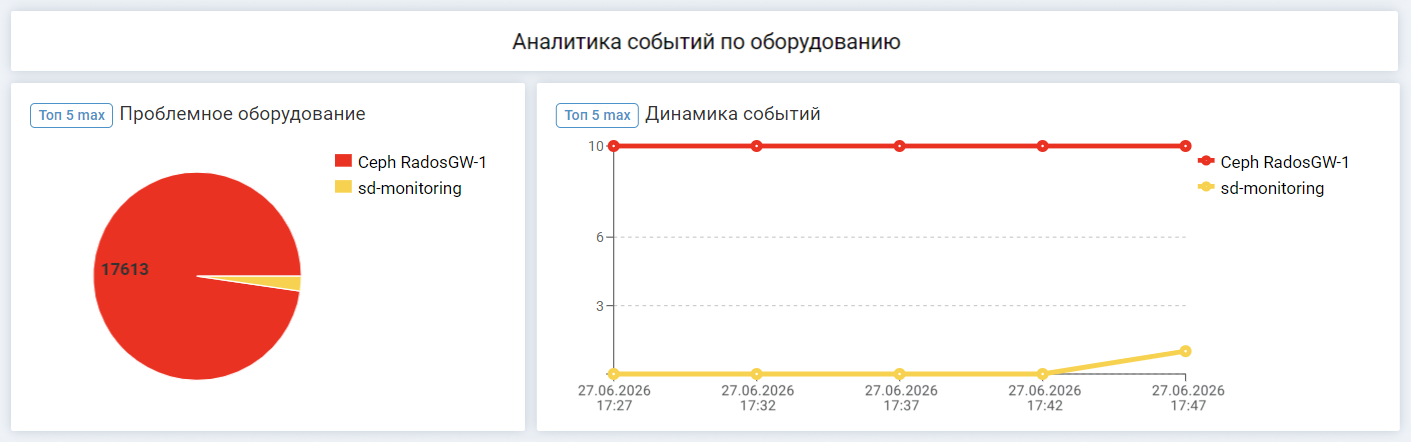
Помогает выявить оборудование, с которым чаще возникают проблемы
«Топ-5 проблемного оборудования" — рейтинг формируется по количеству негативных событий на оборудовании.
«Динамика событий» — в какие дни зафиксированы события на оборудовании.
В совокупности диаграмма и график дают возможность сопоставить факты и проанализировать причины возникновения сбоев. Например, на графике видно, что в один день произошли проблемы на двух конфигурационных единицах. Известно, что в этот день зафиксирован скачок электричества, а значит, эти события могут быть ложными. Чтобы понять, так ли это, потребуется перейти в список событий.
Аналитика инцидентов
Показывает, по каким категориям оборудования чаще всего происходят инциденты и как команда успевает решать возникающие проблемы.
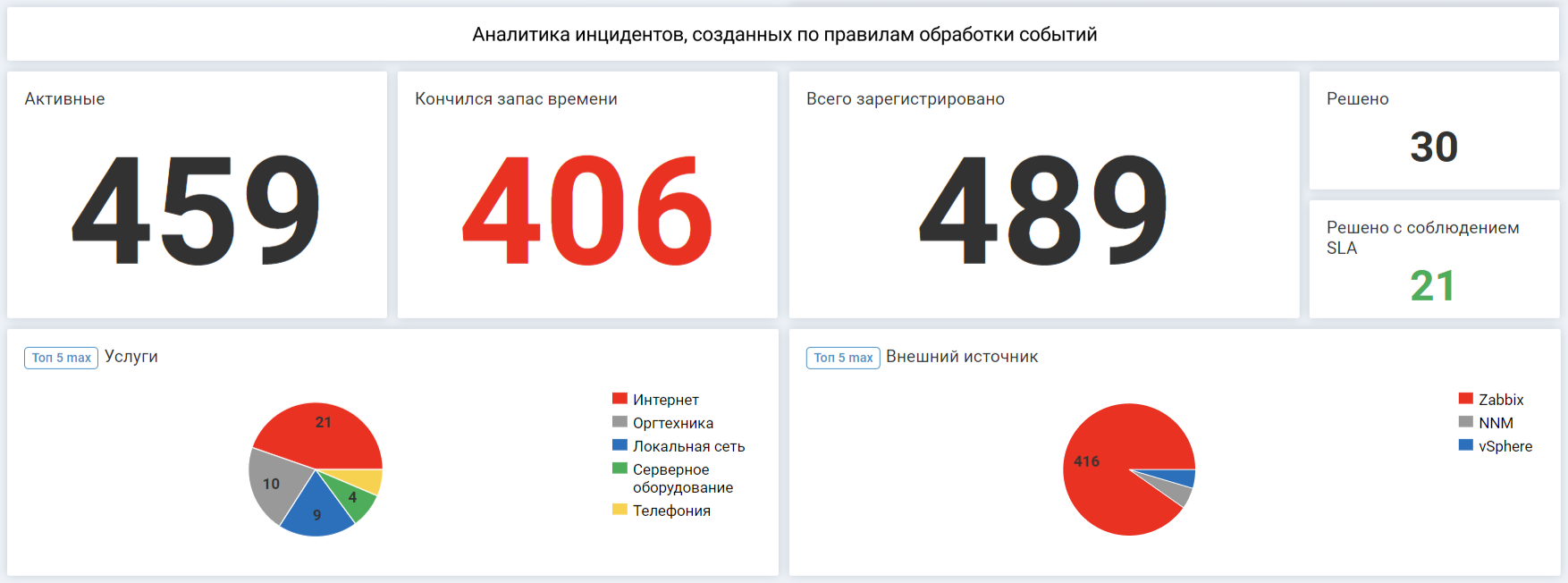
Дашборд показывает статистику по инцидентам и помогает понять, какие услуги затрагиваются
«Активные» — сколько инцидентов в работе на текущий момент.
«Кончился запас времени» — количество просроченных инцидентов.
«Всего зарегистрировано» — число зафиксированных инцидентов.
«Решено», «Решено с соблюдением SLA» — статистика по количеству решенных инцидентов, в т.ч. в срок.
«Топ-5 услуг» — по каким поддерживающим услугам, а по сути на оборудовании какого типа (серверном, сетевом и т.п.) чаще всего возникают сбои.
«Топ-5 внешних источников» — в каких системах инфраструктурного мониторинга чаще всего фиксируются события.
Этот дашборд показателей позволяет реализовать аналитику инфраструктуры, оценить соблюдение установленных регламентов обслуживания. На основе рейтинга «Топ-5 внешних источников» получится сделать вывод о том, в каких частях инфраструктуры чаще всего возникают сбои.
Дашборды для оценки эффективности ИТ-команды
Один из важных факторов управления
Кому подойдет — руководителям
Что выводится на дашборд — насколько эффективно команда решает поступающие инциденты.
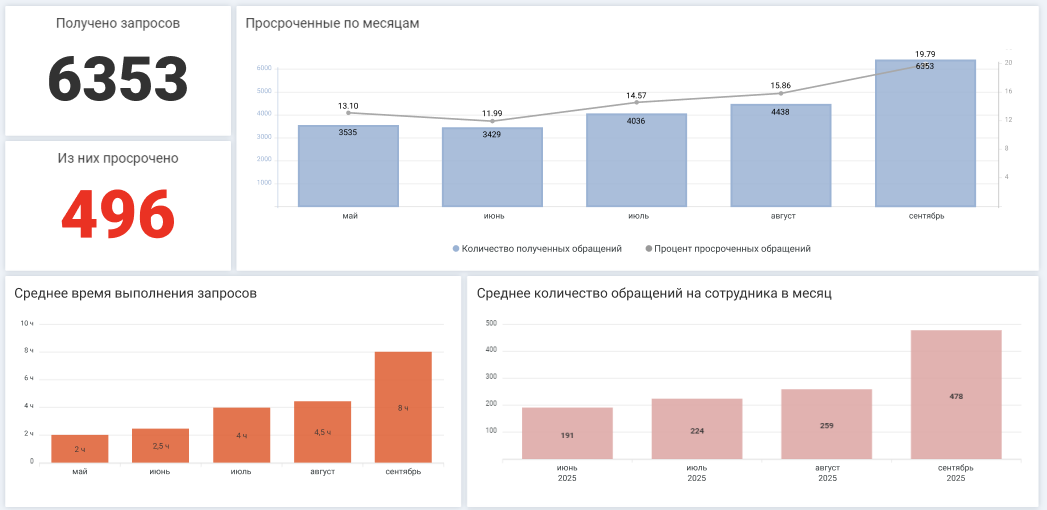
На дашборде аккумулируются все важные показатели по работе с инцидентами, что позволяет анализировать работу команды
«Решено», «Просрочено» — статистика по инцидентам позволяет оценить эффективность работы специалистов.
«Просроченные по месяцам» — график помогает просматривать динамику по решению инцидентов. Например, растет или уменьшается количество просроченных инцидентов по сравнению с другими месяцами.
«Среднее время решения инцидентов по месяцам» — сколько времени требуется специалисту на решение обращения в динамике.
«Среднее количество инцидентов на сотрудника в месяц» — сколько обращений в среднем приходится на инженера.
Также на дашборд можно вывести, к примеру, источники инцидентов. Это позволило бы дополнительно оценить, сколько инцидентов зафиксировано автоматически системами мониторинга, а сколько поступило от операторов техподдержки через Service Desk.
Подобный дашборд нацелен на анализ эффективности работы, чтобы в опоре на данные оценить, нужно ли пересмотреть SLA, расширить штат и как быстро сотрудники решают инциденты в принципе.
Вывод: как дашборды помогают управлять ИТ-инфраструктурой
- Дашборды в Naumen BSM помогают реализовать мониторинг сервисов, одним сотрудникам получать оперативную информацию о доступности услуг, другим — аналитику для управления
ИТ-инфраструктурой и работеИТ-подразделения в целом. - Данные собираются онлайн на одном экране и в понятном виде.
- Фактически дашборд становится незаменимым источником информации для анализа различных ситуаций и принятия оперативных и стратегических решений, связанных с управлением
ИТ-услугами .








